标签:
文件系统的安装过程中,有几个重要的数据结构:
另外,在安装文件系统之前,从设备文件层面看,一个块设备是可以被访问的。只不过这时候访问时只能当作一个特殊文件来读写,也就是说只是一个大的线性空间,或者说这时候的块设备只是一个容量极大的文件而已。但是安装了文件系统之后,整个文件系统作为块设备的代理,通过目录节点访问,这时候对块设备的管理就可以按照一定格式来管理,读写也是按照一定格式来读写,在文件系统的管理之下,块设备的灵活性极大。
文件系统的安装工作主要由do_mount函数完成。
[fs/super.c : 1338~1445 : do_mount]
1338 long do_mount(char * dev_name, char * dir_name, char *type_page,
1339 unsigned long flags, void *data_page)
1340 {
1341 struct file_system_type * fstype;
1342 struct nameidata nd;
1343 struct vfsmount *mnt = NULL;
1344 struct super_block *sb;
1345 int retval = 0;
1346
/* .......此处省略代码若干 */
1385 /* ... filesystem driver... */
1386 fstype = get_fs_type(type_page);
1387 if (!fstype)
1388 return -ENODEV;
1389
1390 /* ... and mountpoint. Do the lookup first to force automounting. */
1391 if (path_init(dir_name,
1392 LOOKUP_FOLLOW|LOOKUP_POSITIVE|LOOKUP_DIRECTORY, &nd))
1393 retval = path_walk(dir_name, &nd);
1394 if (retval)
1395 goto fs_out;
1396
1397 /* get superblock, locks mount_sem on success */
1398 if (fstype->fs_flags & FS_NOMOUNT)
1399 sb = ERR_PTR(-EINVAL);
1400 else if (fstype->fs_flags & FS_REQUIRES_DEV)
1401 sb = get_sb_bdev(fstype, dev_name, flags, data_page);
1402 else if (fstype->fs_flags & FS_SINGLE)
1403 sb = get_sb_single(fstype, flags, data_page);
1404 else
1405 sb = get_sb_nodev(fstype, flags, data_page);
1406
/*......此处省略代码若干*/
1414
1415 /* Refuse the same filesystem on the same mount point */
1416 retval = -EBUSY;
1417 if (nd.mnt && nd.mnt->mnt_sb == sb
1418 && nd.mnt->mnt_root == nd.dentry)
1419 goto fail;
1420
1421 retval = -ENOENT;
1422 if (!nd.dentry->d_inode)
1423 goto fail;
1424 down(&nd.dentry->d_inode->i_zombie);
1425 if (!IS_DEADDIR(nd.dentry->d_inode)) {
1426 retval = -ENOMEM;
1427 mnt = add_vfsmnt(&nd, sb->s_root, dev_name);
1428 }
1429 up(&nd.dentry->d_inode->i_zombie);
1430 if (!mnt)
1431 goto fail;
1432 retval = 0;
/*......此处省略代码若干*/
1445 }第一步:查找file_system_type
1386: 系统支持的每种文件系统都有一个file_system_type结构用于描述和记录文件系统的一些特性。file_system_type定义于[include/linux/fs.h : 839~846],该结构在系统启动,或者是文件系统作为模块被加载进入内核时注册到一全局链表上。这里通过遍历该链表并且比对字符串从而查找到文件系统对应的file_system_type结构。
第二步:查找安装点的dentry结构。
1391~1393: 查找安装点的dentry结构,返回的nd.dentry即为根据路径名查找到的安装节点dentry。而nd.mnt是目前安装节点所在的文件系统的安装信息。
第三步:将待安装文件系统的super_block读取进内存并且建立起VFS的super_block。
1401 : 考虑非特殊文件系统的情况,调用get_sb_bdev读取超级块。该函数定义于[fs/super.c : 785~847 : get_sb_bdev]
第四步:开始安装,连接dentry—>vfsmount—>super_block
调用add_vfsmnt函数进行文件系统的安装,实际上是利用vfsmount结构将安装节点和super_block关联起来。调用完后dentry->d_vfsmnt链表上挂接有vfsmount,vfsmount->mnt_mountpoint = dentry,vfsmount->mnt_root = super_block->s_root。dentry、vfsmount、super_block如图所示:
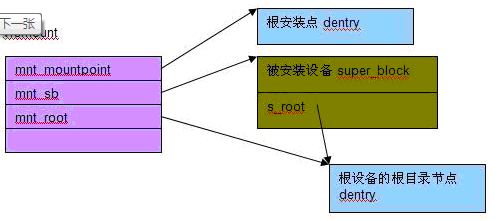
(链接后的dentry、vfsmount、super_block之间的关系,详情请参考这篇文章)
当一个目录节点/home/User/dir被挂接了一个设备时,当利用路径查找/dir下文件时会是如何的呢?path_walk相关部分如下。
[fs/namei.c : 501~511 : path_walk]
501 dentry = cached_lookup(nd->dentry, &this, LOOKUP_CONTINUE);
502 if (!dentry) {
503 dentry = real_lookup(nd->dentry, &this, LOOKUP_CONTINUE);
504 err = PTR_ERR(dentry);
505 if (IS_ERR(dentry))
506 break;
507 }
508 /* Check mountpoints.. */
509 /*如果该节点是一个挂载节点,则前进到挂载设备的根目录中去*/
510 while (d_mountpoint(dentry) && __follow_down(&nd->mnt, &dentry))
511 ;510 : 调用d_mountpoint检查该节点是不是挂载节点,如果是挂载节点就进入被挂载设备的根节点中,用挂载设备的根节点替代这次查找得到的dentry。逻辑上与该语句等效dentry = nd->mnt->mnt_root。d_mountpoint和__follow_down分别定义于[include/linux/dcache.h : 261]和[fs/namei.c : 352]
[include/linux/dcache.h : 261]
261 static __inline__ int d_mountpoint(struct dentry *dentry)
262 {
263 return !list_empty(&dentry->d_vfsmnt);
264 }
[fs/namei.c : 352]
352 static inline int __follow_down(struct vfsmount **mnt, struct dentry **dentry)
353 {
354 struct list_head *p;
355 spin_lock(&dcache_lock);
356 p = (*dentry)->d_vfsmnt.next;
357 while (p != &(*dentry)->d_vfsmnt) {
358 struct vfsmount *tmp;
359 tmp = list_entry(p, struct vfsmount, mnt_clash);
360 if (tmp->mnt_parent == *mnt) {
361 *mnt = mntget(tmp);
362 spin_unlock(&dcache_lock);
363 mntput(tmp->mnt_parent);
364 /* tmp holds the mountpoint, so... */
365 dput(*dentry);
366 *dentry = dget(tmp->mnt_root);
367 return 1;
368 }
369 p = p->next;
370 }
371 spin_unlock(&dcache_lock);
372 return 0;
373 }
文件系统的卸载主要是拆除dentry、vfsmount、super_block之间的链接关系。在文件系统卸载时,完成了以下工作:
文件系统的卸载,主要由do_umount函数完成。
[fs/super.c : 1045]
1045 static int do_umount(struct vfsmount *mnt, int umount_root, int flags)
1046 {
1047 /* 入口参数:
1048 * vfsmount *mnt : 卸载点上的安装信息结构,在安装文件系统时,该结构被填充。
1049 * umount_root : 为0时表示当前要卸载的不是根目录,为非0时,表示当前要卸载根目录
1050 *
1051 * */
1052
1053 struct super_block * sb = mnt->mnt_sb;
/*......此处省略代码若干*/
1065 //如果当前要卸载的mnt挂载点是根目录,则进行只读重装
1066 if (mnt == current->fs->rootmnt && !umount_root) {
1067 int retval = 0;
1068 /*
1069 * Special case for "unmounting" root ...
1070 * we just try to remount it readonly.
1071 */
1072 mntput(mnt);
1073 if (!(sb->s_flags & MS_RDONLY))
1074 retval = do_remount_sb(sb, MS_RDONLY, 0);
1075 return retval;
1076 }
1077
1078 spin_lock(&dcache_lock);
1079
1080 /*
1081 * 如果该文件系统被安装多次,并且引用技术大于2 ,说明还有其它的目录
1082 * 节点挂载了该文件系统,这时只需要移除vfsmount即可,不做回收工作
1083 * */
1084 if (mnt->mnt_instances.next != mnt->mnt_instances.prev) {
1085 if (atomic_read(&mnt->mnt_count) > 2) {
1086 spin_unlock(&dcache_lock);
1087 mntput(mnt);
1088 return -EBUSY;
1089 }
1090 if (sb->s_type->fs_flags & FS_SINGLE)
1091 put_filesystem(sb->s_type);
1092 /* We hold two references, so mntput() is safe */
1093 mntput(mnt);
1094 /*移除vfsmount*/
1095 remove_vfsmnt(mnt);
1096 return 0;
1097 }
/*......此处省略代码若干*/
1130
1131 /*
1132 * 注:当一个dentry在内存中建立起来之后,每当被使用一次,
1133 * 则其引用计数加1,被用完之后引用计数减1直到
1134 * 一个dentry引用计数变为0之后,说明该当前已经
1135 * 没有进程使用该dentry了,但根据程序的局部性
1136 * 原理,该dentry不会被马上释放掉,而是被链入
1137 * 由LRU管理的unused_list队列当中,因为它很可能又会
1138 * 被再次使用,它会一直在该队列中直到被再次使用或者
1139 * 被LRU回收。当文件系统被卸载时,所有属于该
1140 * 文件系统的dentry都会被立即回收,而不会等到被LRU回收。
1141 * */
1142 //释放所有ununed_list中的dentry结构。
1143 shrink_dcache_sb(sb);
1144 //立即将内容回写到设备
1145 fsync_dev(sb->s_dev);
1146 if (sb->s_root->d_inode->i_state) {
1147 mntput(mnt);
1148 return -EBUSY;
1149 }
/*......此处成略代码若干*/
1162 remove_vfsmnt(mnt);
1163
1164 kill_super(sb, umount_root);
1165 return 0;
1166 }第一步: 将vfsmount从相关的list中移除
[fs/super.c : 411~428 : remove_vfsmnt]
411 static void remove_vfsmnt(struct vfsmount *mnt)
412 {
413 /* First of all, remove it from all lists */
414 list_del(&mnt->mnt_instances);
415 list_del(&mnt->mnt_clash);
416 list_del(&mnt->mnt_list);
417 list_del(&mnt->mnt_child);
418 spin_unlock(&dcache_lock);
/*.....此处省略代码若干*/
428 } 414:将vsfmount从该文件系统super_block->s_mounts维护的vsfmount链表中删除。
415:将vsfmount从该安装节点dentry->d_vfsmnt维护的vsfmount链表中删除。
416:将vsfmount从其父设备,即上一层目录的文件系统维护的mnt_child链表中删除
417:将vsfmount从内核维护的全局mnt_list链表中删除。
第二步: 释放所有该文件系统的dentry
[fs/super.c : 1103]
1103 shrink_dcache_sb(sb);第三步: 将该文件系统的super_block以及所有的inode会写到设备内。
1105 fsync_dev(sb->s_dev);文件的打开,本质上是建立起进程与文件之间的链接,也就是file结构,并且返回file结构的索引fd。使得进程能够通过file结构来对文件进行访问。
函数调用链为:
[fs/open.c : 746 : sys_open]:
在1.2的分析中,我们知道,在open_namei函数中,一旦查找路径名对应的dentry不存在的时候,就要在路径名最后一个目录下创建该文件。现在来分析文件创建的过程。
附注:分配inode的原则
标签:
原文地址:http://blog.csdn.net/u013298300/article/details/51214216