标签:
用官方的话来说,所谓K近邻算法(k-Nearest Neighbor,KNN),即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居),
这K个实例的多数属于某个类,就把该输入实例分类到这个类中。这是一个有监督的学习算法
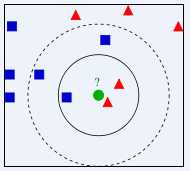
例如下图,红色和蓝色代表已知的训练好的的数据,这个时候来一个示例,也就是图中的绿色圆块,这个绿色圆块属于哪一类呢?
标签:
原文地址:http://www.cnblogs.com/qwj-sysu/p/5439772.html