标签:
1.kmp算法的原理
举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?
许多算法可以完成这个任务,Knuth-Morris-Pratt算法(简称KMP)是最常用的之一。它以三个发明者命名,起头的那个K就是著名科学家Donald Knuth。
1.

首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。
7.
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.

怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
9.
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.

因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
14.

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
15.
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
16.
"部分匹配"的实质是,有时候,字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。
2.next数组的求解思路
通过上文完全可以对kmp算法的原理有个清晰的了解,那么下一步就是编程实现了,其中最重要的就是如何根据待匹配的模版字符串求出对应每一位的最大相同前后缀的长度。

1 void makeNext(const char P[],int next[])
2 {
3 int q,k;//q:模版字符串下标;k:最大前后缀长度
4 int m = strlen(P);//模版字符串长度
5 next[0] = 0;//模版字符串的第一个字符的最大前后缀长度为0
6 for (q = 1,k = 0; q < m; ++q)//for循环,从第二个字符开始,依次计算每一个字符对应的next值
7 {
8 while(k > 0 && P[q] != P[k])//递归的求出P[0]···P[q]的最大的相同的前后缀长度k
9 k = next[k-1]; //不理解没关系看下面的分析,这个while循环是整段代码的精髓所在,确实不好理解
10 if (P[q] == P[k])//如果相等,那么最大相同前后缀长度加1
11 {
12 k++;
13 }
14 next[q] = k;
15 }
16 }
现在我着重讲解一下while循环所做的工作:

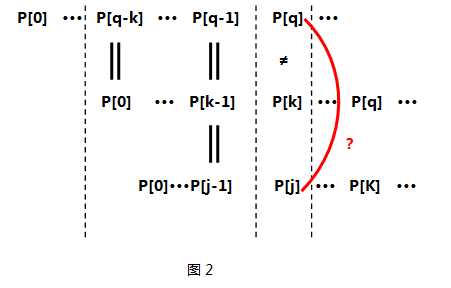
附代码:
1 #include<stdio.h>
2 #include<string.h>
3 void makeNext(const char P[],int next[])
4 {
5 int q,k;
6 int m = strlen(P);
7 next[0] = 0;
8 for (q = 1,k = 0; q < m; ++q)
9 {
10 while(k > 0 && P[q] != P[k])
11 k = next[k-1];
12 if (P[q] == P[k])
13 {
14 k++;
15 }
16 next[q] = k;
17 }
18 }
19
20 int kmp(const char T[],const char P[],int next[])
21 {
22 int n,m;
23 int i,q;
24 n = strlen(T);
25 m = strlen(P);
26 makeNext(P,next);
27 for (i = 0,q = 0; i < n; ++i)
28 {
29 while(q > 0 && P[q] != T[i])
30 q = next[q-1];
31 if (P[q] == T[i])
32 {
33 q++;
34 }
35 if (q == m)
36 {
37 printf("Pattern occurs with shift:%d\n",(i-m+1));
38 }
39 }
40 }
41
42 int main()
43 {
44 int i;
45 int next[20]={0};
46 char T[] = "ababxbababcadfdsss";
47 char P[] = "abcdabd";
48 printf("%s\n",T);
49 printf("%s\n",P );
50 // makeNext(P,next);
51 kmp(T,P,next);
52 for (i = 0; i < strlen(P); ++i)
53 {
54 printf("%d ",next[i]);
55 }
56 printf("\n");
57
58 return 0;
59 }
KMP算法,是由Knuth,Morris,Pratt共同提出的模式匹配算法,其对于任何模式和目标序列,都可以在线性时间内完成匹配查找,而不会发生退化,是一个非常优秀的模式匹配算法。但是相较于其他模式匹配算法,该算法晦涩难懂,第一次接触该算法的读者往往会看得一头雾水,主要原因是KMP算法在构造跳转表next过程中进行了多个层面的优化和抽象,使得KMP算法进行模式匹配的原理显得不那么直白。本文希望能够深入KMP算法,将该算法的各个细节彻底讲透,扫除读者对该算法的困扰。
KMP算法对于朴素匹配算法的改进是引入了一个跳转表next[]。以模式字符串abcabcacab为例,其跳转表为:
| j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| pattern[j] | a | b | c | a | b | c | a | c | a | b |
| next[j] | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 5 | 0 | 1 |
跳转表的用途是,当目标串target中的某个子部target[m...m+(i-1)]与pattern串的前i个字符pattern[1...i]相匹配时,如果target[m+i]与pattern[i+1]匹配失败,程序不会像朴素匹配算法那样,将pattern[1]与target[m+1]对其,然后由target[m+1]向后逐一进行匹配,而是会将模式串向后移动i+1 - next[i+1]个字符,使得pattern[next[i+1]]与target[m+i]对齐,然后再由target[m+i]向后与依次执行匹配。
举例说明,如下是使用上例的模式串对目标串执行匹配的步骤
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| b | a | b | c | b | a | b | c | a | b | c | a | a | b | c | a | b | c | a | b | c | a | c | a | b | c |
| a | b | c | a | b | c | a | c | a | b | ||||||||||||||||
| a | b | c | a | b | c | a | c | a | b | ||||||||||||||||
| a | b | c | a | b | c | a | c | a | b | ||||||||||||||||
| a | b | c | a | b | c | a | c | a | b | ||||||||||||||||
| a | b | c | a | b | c | a | c | a | b | ||||||||||||||||
| a | b | c | a | b | c | a | c | a | b |
通过模式串的5次移动,完成了对目标串的模式匹配。这里以匹配的第3步为例,此时pattern串的第1个字母与target[6]对齐,从6向后依次匹配目标串,到target[13]时发现target[13]=‘a‘,而pattern[8]=‘c‘,匹配失败,此时next[8]=5,所以将模式串向后移动8-next[8] = 3个字符,将pattern[5]与target[13]对齐,然后由target[13]依次向后执行匹配操作。在整个匹配过程中,无论模式串如何向后滑动,目标串的输入字符都在不会回溯,直到找到模式串,或者遍历整个目标串都没有发现匹配模式为止。
next跳转表,在进行模式匹配,实现模式串向后移动的过程中,发挥了重要作用。这个表看似神奇,实际从原理上讲并不复杂,对于模式串而言,其前缀字符串,有可能也是模式串中的非前缀子串,这个问题我称之为前缀包含问题。以模式串abcabcacab为例,其前缀4 abca,正好也是模式串的一个子串abc(abca)cab,所以当目标串与模式串执行匹配的过程中,如果直到第8个字符才匹配失败,同时也意味着目标串当前字符之前的4个字符,与模式串的前4个字符是相同的,所以当模式串向后移动的时候,可以直接将模式串的第5个字符与当前字符对齐,执行比较,这样就实现了模式串一次性向前跳跃多个字符。所以next表的关键就是解决模式串的前缀包含。当然为了保证程序的正确性,对于next表的值,还有一些限制条件,后面会逐一说明。
如何以较小的代价计算KMP算法中所用到的跳转表next,是算法的核心问题。这里我们引入一个概念f(j),其含义是,对于模式串的第j个字符pattern[j],f(j)是所有满足使pattern[1...k-1] = pattern[j-(k-1)...j - 1](k < j)成立的k的最大值。还是以模式串abcabcacab为例,当处理到pattern[8] = ‘c‘时,我们想找到‘c‘前面的k-1个字符,使得pattern[1...k-1] = pattern[8-(k-1)...7],这里我们可以使用一个笨法,让k-1从1到6递增,然后依次比较,直到找到最大值的k为止,比较过程如下
| k-1 | 前缀 | 关系 | 子串 |
| 1 | a | == | a |
| 2 | ab | != | ca |
| 3 | abc | != | bca |
| 4 | abca | == | abca |
| 5 | abcab | != | cabca |
| 6 | abcabc | != | bcabca |
因为要取最大的k,所以k-1=1不是我们要找的结果,最后求出k的最大值为4+1=5。但是这样的方法比较低效,而且没有充分利用到之前的计算结果。在我们处理pattern[8] = ‘c‘之前,pattern[7] = ‘a‘的最大前缀包含问题已经解决,f(7) = 4,也就是说,pattern[4...6] = pattern[1...3],此时我们可以比较pattern[7]与pattern[4],如果pattern[4]=pattern[7],对于pattern[8]而言,说明pattern[1...4]=pattern[4...7],此时,f(8) = f(7) + 1 = 5。再以pattern[9]为例,f(8) = 5,pattern[1...4]=pattern[4...7],但是pattern[8] != pattern[5],所以pattern[1...5]!=pattern[4...8],此时无法利用f(8)的值直接计算出f(9)。
| j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| pattern[j] | a | b | c | a | b | c | a | c | a | b |
| next[j] | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 5 | 0 | 1 |
| f(j) | 0 | 1 | 1 | 1 | 2 | 3 | 4 | 5 | 1 | 2 |
我们可能考虑还是使用之前的笨方法来求出f(9),但是且慢,利用之前的结果,我们还可以得到更多的信息。还是以pattern[8]为例。f(8) = 5,pattern[1...4]=pattern[4...7],此时我们需要关注pattern[8],如果pattern[8] != pattern[5],那么在匹配算法如果匹配到pattern[8]才失败,此时就可以将输入字符target[n]与pattern[f(8)] = pattern[5]对齐,再向后依次执行匹配,所以此时的next[8] = f(8)(此平移的正确性,后面会作出说明)。而如果pattern[8] = pattern[5],那么pattern[1...5]=pattern[4...8],如果target[n]与pattern[8]匹配失败,那么同时也意味着target[n-5...n]!=pattern[4...8],那么将target[n]与pattern[5]对齐,target[n-5...n]也必然不等于pattern[1...5],此时我们需要关注f(5) = 2,这意味着pattern[1] = pattern[4],因为pattern[1...4]=pattern[4...7],所以pattern[4]=pattern[7]=pattern[1],此时我们再来比较pattern[8]与pattern[2],如果pattern[8] != pattern[2],就可以将target[n]与pattern[2],然后比较二者是否相等,此时next[8] = next[5] = f(2)。如果pattern[8] = pattern[2],那么还需要考察pattern[f(2)],直到回溯到模式串头部为止。下面给出根据f(j)值求next[j]的递推公式:
如果 pattern[j] != pattern[f(j)],next[j] = f(j);
如果 pattern[j] = pattern[f(j)],next[j] = next[f(j)];
当要求f(9)时,f(8)和next[8]已经可以得到,此时我们可以考察pattern[next[8]],根据前面对于next值的计算方式,我们知道pattern[8] != pattern[next[8]]。我们的目的是要找到pattern[9]的包含前缀,而pattern[8] != pattern[5],pattern[1...5]!=pattern[4...8]。我们继续考察pattern[next[5]]。如果pattern[8]
= pattern[next[5]],假设next[5] = 3,说明pattern[1...2] = pattern[6...7],且pattern[3] = pattern[8],此时对于pattern[9]而言,就有pattern[1...3]=pattern[6...8],我们就找到了f(9) = 4。这里我们考察的是pattern[next[j]],而不是pattern[f(j)],这是因为对于next[]而言,pattern[j] != pattern[next[j]],而对于f()而言,pattern[j]与pattern[f(j)]不一定不相等,而我们的目的就是要在pattern[j]
!= pattern[f(j)]的情况下,解决f(j+1)的问题,所以使用next[j]向前回溯,是正确的。
现在,我们来总结一下next[j]和f(j)的关系,next[j]是所有满足pattern[1...k - 1] = pattern[(j - (k - 1))...j -1](k < j),且pattern[k] != pattern[j]的k中,k的最大值。而f(j)是满足pattern[1...k - 1] = pattern[(j - (k - 1))...j -1](k < j)的k中,k的最大值。还是以上例的模式来说,对于第7个元素,其f(j) = 4, 说明pattern[7]的前3个字符与模式的前缀3相同,但是由于pattern[7] = pattern[4], 所以next[7] != 4。
通过以上这些,读者可能会有疑问,为什么不用f(j)直接作为KMP算法的跳转表呢?实际从程序正确性的角度讲是可以的,但是使用next[j]作为跳转表更加高效。还是以上面的模式为例,当target[n]与pattern[7]发生匹配失败时,根据f(j),target[n]要继续与pattern[4]进行比较。但是在计算f(8)的时候,我们会得出pattern[7]
= pattern[4],所以target[n]与pattern[4]的比较也必然失败,所以target[n]与pattern[4]的比较是多余的,我们需要target[n]与更小的pattern进行比较。当然使用f(j)作为跳转表也能获得不错的性能,但是KMP三人将问题做到了极致。
我们可以利用f(j)作为媒介,来递推模式的跳转表next。算法如下:
<span style="font-size:18px;">inline void BuildNext(const char* pattern, size_t length, unsigned int* next)
{
unsigned int i, t;
i = 1;
t = 0;
next[1] = 0;
while(i < length + 1)
{
while(t > 0 && pattern[i - 1] != pattern[t - 1])
{
t = next[t];
}
++t;
++i;
if(pattern[i - 1] == pattern[t - 1])
{
next[i] = next[t];
}
else
{
next[i] = t;
}
}
//pattern末尾的结束符控制,用于寻找目标字符串中的所有匹配结果用
while(t > 0 && pattern[i - 1] != pattern[t - 1])
{
t = next[t];
}
++t;
++i;
next[i] = t;
}
</span>
程序中,9到27行的循环需要特别说明一下,我们发现在循环开始之后,就没有再为t赋新值,也就是说,对于计算next[j]时的t值,在计算next[j+1]时,还会用得着。实际这时的t的就等于f(j)。还是以上例的目标串为例,当j等于1,我们可以得出t = f(2) = 1。使用归纳法,当计算完next[j]后,我们假设此时t=f(j),此时第11~14行的循环就是要找到满足pattern[k] = pattern[j]的最大k值。如果这样的k存在,对于pattern[j+1]而言,其前k个元素,与模式的前缀k相同。此时的t+1就是f(j+1)。这时我们就要判断pattern[j+1]和pattern[t](t = t+1)的关系,然后求出next[j+1]。这里需要初始条件next[1] = 0。
利用跳转表实现字符串匹配的算法如下:
<span style="font-size:18px;">unsigned int KMP(const char* text, size_t text_length, const char* pattern, size_t pattern_length, unsigned int* matches)
{
unsigned int i, j, n;
unsigned int next[pattern_length + 2];
BuildNext(pattern, pattern_length, next);
i = 0;
j = 1;
n = 0;
while(pattern_length + 1 - j <= text_length - i)
{
if(text[i] == pattern[j - 1])
{
++i;
++j;
//发现匹配结果,将匹配子串的位置,加入结果
if(j == pattern_length + 1)
{
matches[n++] = i - pattern_length;
j = next[j];
}
}
else
{
j = next[j];
if(j == 0)
{
++i;
++j;
}
}
}
//返回发现的匹配数
return n;
}
</span>
该算法在原有基础上进行了扩展,在原模式串末尾加入了一个“空字符”,“空字符”不等于任何的可输入字符,当目标串匹配至“空字符”时,说明已经在目标字符串中发现了模式,将模式串在目标串中的位置,加入matchs[]数组中,同时判定为匹配失败,并根据“空字符”的next值,跳转到适当位置,这样算法就可以识别出字符串中所有的匹配子串。
最后,对KMP算法的正确性做一简要说明,还是以上文的模式串pattern和目标串target为例,假设已经匹配到第3部的位置,且在target[13]处发现匹配失败,我们如何决定模式串的滑动步数,来保证既要忽略不必要的多余比较,又不漏过可能的匹配呢?
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | |
| target | b | a | b | c | b | a | b | c | a | b | c | a | a | b | c | a | b | c | a | b | c | a | c | a | b | c |
| pattern | a | b | c | a | b | c | a | c | a | b |
对于例子中的情况,显然向后移动多于3个字符有可能会漏过target[9...18]这样的的可能匹配。但是为什么向后移动1个或者2个字符是不必要的多余比较呢?当target[13]与pattern[8]匹配失败时,同时也意味着,target[6...12]
= pattern[1...7],而next[8]=5,意味着,pattern[1...4] = pattern[4...7],pattern[1...5]
!= pattern[3...7],pattern[1...6]
!= pattern[2...7]。如果我们将模式串后移1个字符,使pattern[7]与target[13]对齐,此时target[7...12]相当于pattern[2...7],且target[7...12]与pattern[1..6]逐个对应,而我们已经知道pattern[1...6]
!= pattern[2...7]。所以不管target[13]是否等于pattern[7],此次比较都必然失败。同理向前移动2个字符也是多余的比较。由此我们知道当在pattern[j]处发生匹配失败时,将当前输入字符与pattern[j]和pattern[next[j]]之间的任何一个字符对齐执行的匹配尝试都是必然失败的。这就说明,在模式串从目标串头移动到目标串末尾的过程中,除了跳过了必然失败的情况之外,没有漏掉任何一个可能匹配,所以KMP算法的正确性是有保证的。
后记:
标签:
原文地址:http://blog.csdn.net/wyatt007/article/details/51273195