标签:
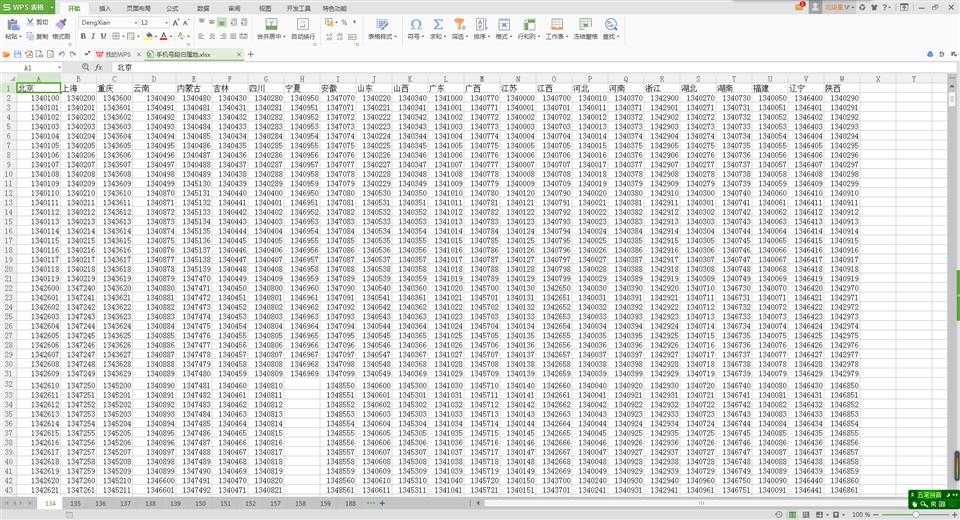
上周,老板给我一个小任务:批量生成手机号码并去重。给了我一个Excel表,里面是中国移动各个地区的可用手机号码前7位(如下图),里面有十三张表,每个表里的电话号码前缀估计大概是八千个,需要这些7位号码生成每个都生成后4位组成11位手机号码,也就说每一个格子里面的手机号码都要生成一万个手机号。而且还有,本来服务器已经使用了一部分手机号码了,要在生成的号码列表里去掉已经使用过的那一批。已经使用过的这一批号码已经导出到了一批txt文本里,约4000w,每个txt有10w个号码,里面有重复的,老板估计实际大概是3000w左右。老板可以给我分配使用一个16G内存、8核CPU的Windows服务器来跑程序。
要处理海量数据,所以程序的执行效率和占用内存不能太高,应该能在开发机的4G内存下也大概跑得动,即关掉所有编程IDE和服务器软件,只用Notepad++和浏览器(用来查资料)的情况下不会卡机。这次任务可能会用到的技术有:程序Excel的处理,文件的遍历和读写,大型数组的操作,多线程并发。预估任务完成周期:一周(日常工作正常进行的前提下)。
PHP:很熟悉,但是执行效率和内存占用不够好,可能会卡机,要实现多线程似乎有点复杂。(有待斟酌)
Javascript:较熟悉,执行效率和内存占用不太清楚,但是弱类型通常都比较堪忧,各种回调比较干扰思维不顺手。(不考虑)
Java:略懂,学起来和写起来都比较麻烦,开发效率比较慢。(有待斟酌)
C#:没用过,较难学(比JAVA易,比脚本难)。(有待斟酌)
C/C++:略懂,数组处理、多线程这两个似乎比较难搞。(不考虑)
Python:没用过,据说很容易学,有个研究生同学用它来做物理运算等,执行效率应该不低。(试试看)
于是就打着试试看的心态,打开了菜鸟教程(Runoob)的Python教程大概看了一下,目录中有几个数组(List、元组、字典)、文件IO、File和多线程,看了一下例程果然好简单。再度娘了一下python处理Excel,果断简单快捷!于是开启了玩蛇之路。
本文开头说到,有4000w的已用号码列表,但是里面是有重复的,而后面的处理都需要用到这些号码。而看到这400多个txt文件加起来大小约500M,所以全部读进去再进行处理也可以承受。所以先把这些文件读进去合并去重,输出成为一个txt文件。最后得到的号码有1800w多条,输出txt文件大小约209M。
 hebing.py
hebing.py其中对数组内的元素进行合并去重的那一句是 txtArr = list( set(txtArr) ) 。很神奇对吧,这两个是什么函数?其实这两个都是转换类型的函数。先把它转换成了 set 类型,再转换为 list 类型(列表/数组)。python的set(集合)类型是一个无序不重复的元素集,所以list转换为set之后就自动去重了,当然同时顺序也会被打乱了,不过这里的顺序不重要就不用管它啦。
最后数组转换为字符串也是直接用字符串拼接数组就转换了,不要用for循环,非常非常耗时间的。
根据网上例程直接读取Excel第一个表里面的内容出来,合并成数组转成字符串存到文本里面去。在转成字符串的时候发现报错似乎是说数据类型不对,才知道原来python与PHP、JS不同,是强类型的=_=!于是先在Excel里把表里面的数据转换成字符串格式(excel里准确叫文本格式),转换后excel表里面的数据格左上角是有绿色的小三角形的。每个表单独处理生成一个文件,一个文件里面大概有八千个手机号码前缀。
preNum.py首先来想想,有十三个表,一个表里面有大概八千个号码前缀,每个前缀生成一万个号码,每个号码要与前面所说的1800万的已用手机号码进行比对去重。你会怎么做呢???
↓↓
↓↓
我的想法是,分成十三次来做,每次一个表,每个表中八千多个号码,使用多线程,八千多个线程,每个线程生成一万个号码并与那1800万个号码一 一比对。
其中生成和去重的核心代码如下,每生成一个号码的时间大概是0.5秒。所以估计了一下时间,10000*0.5s ≈ 83min,八千个线程大概要一个半小时左右。

#这里是重复的号码
#fileobj = open(‘testBugNum.txt‘); #测试的
fileobj = open(‘list-dataAll.txt‘); #实际的
bugTxtStr = fileobj.read();
fileobj.close();
bugTxtArr = bugTxtStr.splitlines(); #已用过的号码的列表
while j < 10000: #生成一万个同前缀号码
newNum = str( int(txtNum)*10000+j );
j += 1;
# print newNum;
if not newNum in bugTxtArr: #如果不在已用过的号码列表里
numArr.append( ‘+86‘+newNum );
print ‘+86‘+newNum;
我在本机大概运行了一下,观察了几分钟,似乎线程创建得比较慢,有些已经跑到了十几个了,有的才刚创建线程。线程调度嘛,不按照顺序嘛,除了输出很乱以外,似乎也没有什么其它问题。于是就上传到服务器上去跑了,然后再过了一会就下班回家了。第二天回到公司,连上服务器看看,出乎意料啊,看到输出的信息里面,那些线程才跑到 三百多,天呐什么时候才能跑到一万啊。而且还有坑爹的是,偶尔就看到有些线程创建失败⊙o⊙
从前面的运行信息来看,这里使用多线程似乎并没有加快程序的运行啊,这是为什么呢?如果不能用多线程,那么生成比对的地方就要改成另外更高效的方式了,有吗?
第一问,从网上找到答案,确实说在计算密集型程序中,多线程比单线程更糟,因为一个CPU就那么几个核,不同的线程还是一样要占用CPU资源,再加上线程调度的时间和空间,真是天坑。第二问,PHP中有从一个数组去除另一个数组的函数(官方说法叫做数组的差集 array_diff() ),那么python应该也会有这样的函数,先成一万个号码的数组再进行差集 会不会比原来 每个号码对比再合并效率快呢?
实践了一下,证明确实效率高了极多极多,python中的数组差集是这个样子的 numArr = list( set(numArr) - set(bugTxtArr) ) 测了一下,大概三秒完成一批号码(一批约等于一万个号码),之前是半秒一个号码\( ^▽^ )/。但也注意现在生成的一万个号码排序是乱的,因为中间转换成的set类型是无序的,如果需要从小到大排序,那还要再加个函数排序一下,问了老板说不用按顺序,那就直接这样了。
期间调试的时候发现,使用多线程有时会报错 Unhandled exception in thread started by sys.excepthook is missing 之类的,网上查资料说是因为主进程已经执行完毕,那么其创建的线程就会被关掉。所以我的做法就是让主进程最后为一直执行空语句,很像当年用C语言做单片机的做法呢→_→虽然最后不用多线程了,直接单线程处理,安全稳定。
doData.py经过了大概六个小时的号码生成,最后就是把一个Excel表生成的八千多个文件整理,每十个文件合成一个,每个文件约十万个号码,每个号码前面加上 “+86” 。就遍历一下目录,没什么技术点就不详说了。
hbData.py后话,总共只有十三个表,这些程序稍微改一下,执行十三次就行了。值得注意的是,我这里的程序几乎每个都有一个全局变量 tblIndex, 是以防一文件里面一个个修改目录名和文件名,疏忽有可能导致的数据覆盖。
标签:
原文地址:http://www.cnblogs.com/Leo_wl/p/5444871.html