标签:
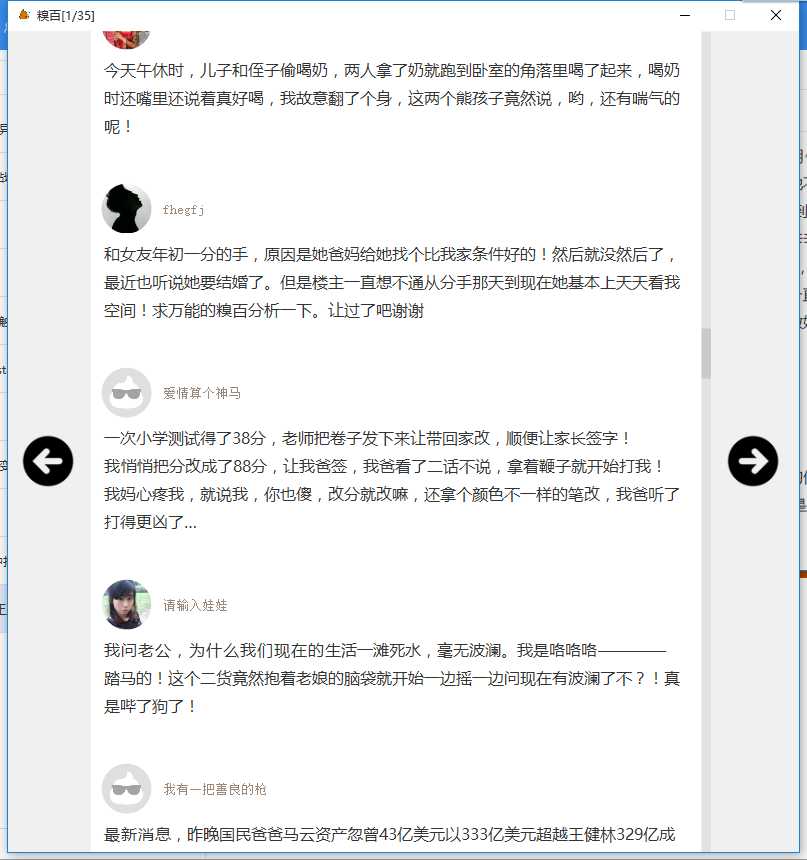
打开糗事百科笑话的主页,在这里我只取糗事笑话中文字这一板块,点击文字这一菜单栏。如下图。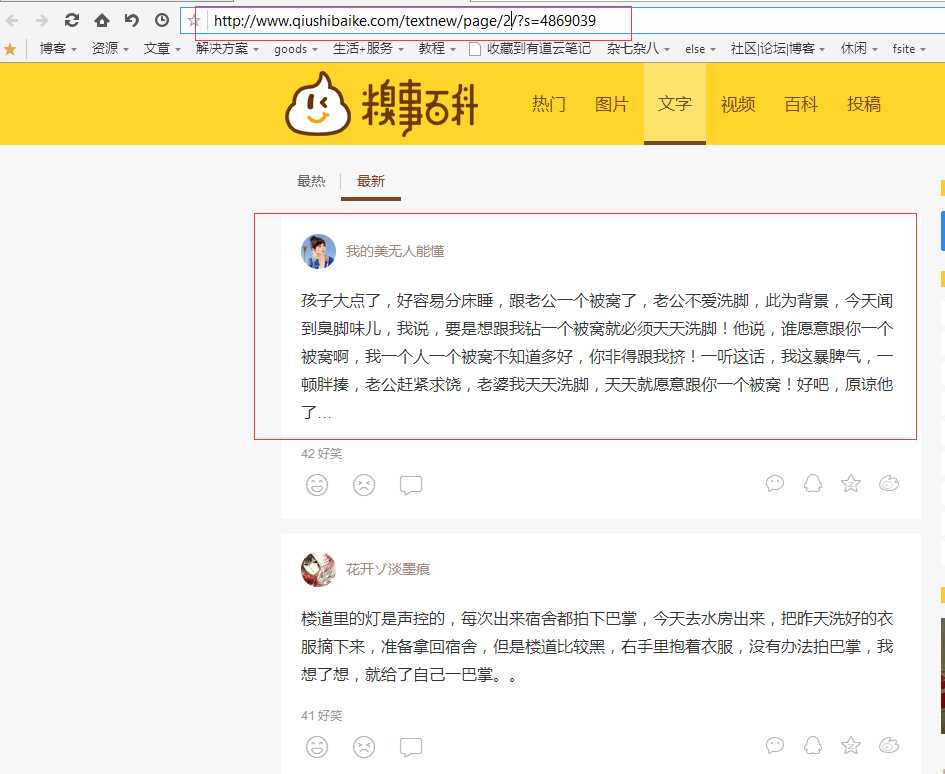
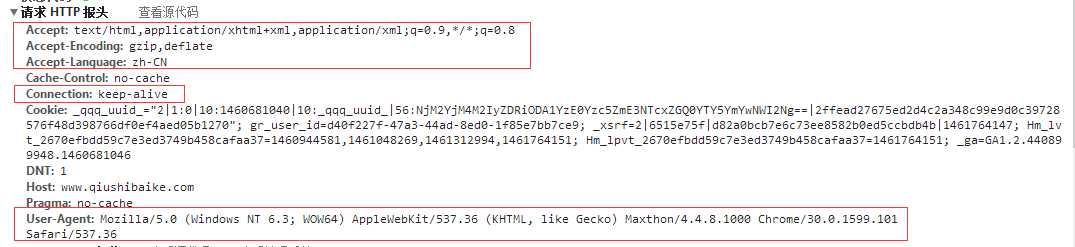

const string qsbkMainUrl = "http://www.qiushibaike.com";
//获取糗百文字笑话页的url
private static string GetWBJokeUrl(int pageIndex)
{
StringBuilder url = new StringBuilder();
url.Append(qsbkMainUrl);
url.Append ("/textnew/page/");
url.Append(pageIndex.ToString ());
url.Append("/?s=4869039");
return url.ToString();
}
//根据网页的url获取网页的html源码
private static string GetUrlContent(string url)
{
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.8.1000 Chrome/30.0.1599.101 Safari/537.36";
request.Method = "GET";
request.ContentType = "text/html;charset=UTF-8";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream myResponseStream = response.GetResponseStream();
StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));//因为知道糗百网页的编码方式为utf-8
string retString = myStreamReader.ReadToEnd();
myStreamReader.Close();
myResponseStream.Close();
return retString;
}
catch { return null; }
}
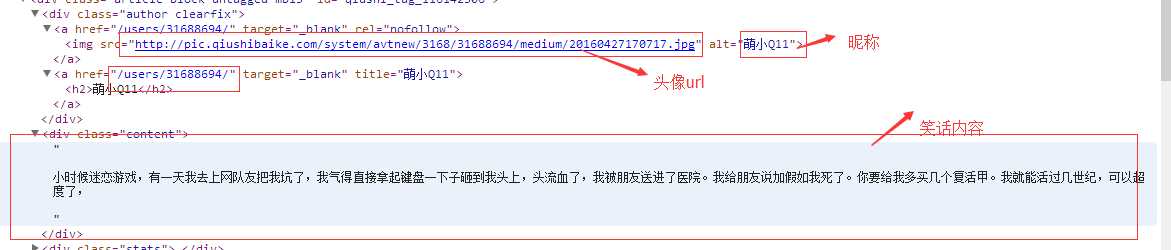
正则:<img src="([^"]*")\s*alt="([^"]*)"/>\s</a>\s<a href="([^"]*)"[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class="content">\s*((.*|<br/>)*)
public class JokeItem
{
private string nickName;
/// <summary>
/// 昵称
/// </summary>
public string NickName
{
get { return nickName; }
set { nickName = value; }
}
private Image headImage;
/// <summary>
/// 头像
/// </summary>
public Image HeadImage
{
get { return headImage; }
set { headImage = value; }
}
private string jokeContent;
/// <summary>
/// 笑话内容
/// </summary>
public string JokeContent
{
get { return jokeContent; }
set { jokeContent = value; }
}
private string jokeUrl;
/// <summary>
/// 笑话地址
/// </summary>
public string JokeUrl
{
get { return jokeUrl; }
set { jokeUrl = value; }
}
}
b、利用正则获取笑话内容
/// <summary>
/// 获取笑话列表
/// </summary>
/// <param name="htmlContent"></param>
public static List<JokeItem> GetJokeList(int pageIndex)
{
string htmlContent=GetUrlContent(GetWBJokeUrl(pageIndex));
List<JokeItem> jokeList = new List<JokeItem>();
Regex rg = new Regex(@"<img src=""([^""]*"")\s*([^""]*)""/>\s</a>\s<a href=""([^""]*)""[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class=""content"">\s*((.*|<br/>)*)", RegexOptions.IgnoreCase);
JokeItem joke;
MatchCollection matchResults = rg.Matches(htmlContent);
foreach (Match result in matchResults)
{
joke = new JokeItem();
joke.HeadImage = GetWebImage(result.Groups[1].Value);
joke.HeadImage = joke.HeadImage != null ? new Bitmap(GetWebImage(result.Groups[1].Value), 50, 50) : null;
joke.NickName = result.Groups[2].Value;
joke.JokeUrl = qsbkMainUrl + "/" + result.Groups[3].Value; ;
joke.JokeContent = result.Groups[4].Value.Replace("<br/>", "\r\n").Replace("<br>", "\r\n");
joke.JokeContent = Regex.Replace(joke.JokeContent, @"(\r\n)+", "\r\n");//去掉多余的空行
jokeList.Add(joke);
}
return jokeList;
}
c、根据头像url地址获取头像
private static Image GetWebImage(string webUrl)
{
try
{
Encoding encode = Encoding.GetEncoding("utf-8");//网页编码==Encoding.UTF8
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(new Uri(webUrl));
HttpWebResponse ress = (HttpWebResponse)req.GetResponse();
Stream sstreamRes = ress.GetResponseStream();
return System.Drawing.Image.FromStream(sstreamRes);
}
catch { return null; }
}
3、数据绑定
标签:
原文地址:http://www.cnblogs.com/Leo_wl/p/5454414.html