标签:

下面,将对这几类 API 做分别的讨论。
// 创建 IndexSearcher 类实例: Directory dir = FSDirectory.open(/path/to/indices); IndexReader reader = IndexReader.open(dir); IndexSearcher searcher = new IndexSearcher(reader); // 实现搜索功能 IndexSearcher.search(): TopDocs search(Query query, int n) //————直接进行搜索,返回评分最高的N个文档 TopDocs search(Query query, Filter filter, int n) //————搜索受文档子集约束,约束条件基于过滤条件 TopFieldDocs search(Query query, Filter filter, int n, Sort sort) //————排序 void search(Query query, Collector results) //————使用自定义文档访问策略 void search(Query query, Filter filter, Collector results)
调用 IndexSearcher.search() 方法,返回 TopDocs 对象。
TopDocs.totalHits() //匹配搜索条件的文档数量 TopDocs.scoreDocs() //包含搜索结果的ScoreDoc对象数组 TopDocs.getMaxScore() //如果已完成排序这返回最大评分
使用 Query 类就是直接使用 Lucene 的各种 Query API 来进行查询。
Query 的子类可以直接实例化,也可以通过 QueryParser 类实例化。通过 QueryParser 实例化会首先将自由文本转换为各种 Query 类型,这个将在【使用 QueryParser 类】 小节讲述。
该查询是区分大小写的,搜索前要对索引后的项大小写进行匹配
TermQuery: //该查询是区分大小写的,搜索前要对索引后的项大小写进行匹配 Term t = new Term("contents", "java"); Query query = new TermQuery(t);
索引中的各个 Term 回想会按照字典编排排序,并允许在 Lucene 的 TermQuery 对象提供的范围内进行文本项的直接搜索。
用两个Boolean对象参数表示是否包含搜索范围的起点/终点。
TermRangeQuery: //用两个Boolean对象参数表示是否包含搜索范围的起点/终点 TermRangeQuery query = new TermRangeQuery("title2", "d", "j", true, true); //搜索 title 域起始字母从 ‘d‘ 到 ‘j‘ 的文档
用两个Boolean对象参数表示是否包含搜索范围的起点/终点。
NumericRangeQuery: //用两个Boolean对象参数表示是否包含搜索范围的起点/终点 NumericRangeQuery query = new NumericRangeQuery.newIntRange("pubmonth", 200605, 200609, true, true);
搜索包含以指定字符串开头的项的文档。
PrefixQuery: //搜索包含以指定字符串开头的项的文档 Term term = new Term("category", "/technology/computers/programing"); PrefixQuery query = new PrefixQuery(term); //搜索编程方面的书籍,包括他们的子类书籍(子目录) Query query = new TermQuery(term); //搜索编程方面的书籍,不包括子类书籍(子目录)
通过BooleanQuery可以将各种查询类型组合起来。
BooleanQuery: //通过BooleanQuery可以将各种查询类型组合起来 TermQuery searchingBooks = new TermQuery(new Term("subject", "search")); Query books2010 = NumericRangeQuery.newIntRange("pubmonth", 201001, 201009, true,true); BooleanQuery searchingBooks2010 = new BooleanQuery(); searchingBooks2010.add(searchingBooks, BooleanClause.Occur.MUST); searchingBooks2010.add(books2010,BooleanClause.Occur.MUST)
PhraseQuery类会根据项的位置信息定位某个距离范围内的项所对应的文档。
PhraseQuery: //PhraseQuery类会根据项的位置信息定位某个距离范围内的项所对应的文档 PhraseQuery query = new PhraseQuery(); query.setSlop(slop);
使用不完整的、缺少某些字母的项进行查询。
WildcardQuery: //使用不完整的、缺少某些字母的项进行查询 Query query = new WildcardQuery(new Term("contents", "?ild*"));
用于查询与指定项相似的项(如:three/tree编辑距离为1)。
FuzzyQuery: //用于查询与指定项相似的项(three/tree编辑距离为1) Query query = new FuzzyQuery(new Term("contents", "wuzza"));
MatchAllDocsQuery: Query query = new MatchAllDocsQuery(); //对匹配的分配固定的评分 Query query = new MatchAllDocsQuery(field); //文档根据指定的域评分
与 matchVersion、一个域名和一个分析器一起用于将输入的文本分割成 Terms 对象:
QueryParser parse = new QueryParser(Version.LUCENE_30, "contents", new SimpleAnalzer());
IndexSearcher searcher = new IndexSearcher(dir); QueryParser parse = new QueryParser(Version.LUCENE_30,"contents", new SimpleAnalzer()); Query query = parser.parse("+JUNIT +ANT -MOCK"); //解析 "+JUNIT +ANT -MOCK" 为Query对象 TopDocs docs = searcher.search(query, 10);
1. Query.toString:
//toString: query.add(new FuzzyQuery(new Term("field", "kountry")), BooleanClause.Occur.MUST); assertEquals("+kountry~0.5" query.toString(field));
2. 项查询:
//TermQuery QueryParse parser = new QueryParser(Version.LUCENE_30, "subject", analyzer); Query query = parser.parse("computers"); //默认域 System.out.printfln("term: " + query); //输出 term: subject:computers
3. 项范围查询:
//项范围查询 QueryParse parser = new QueryParser(Version.LUCENE_30, "subject", analyzer); Query query = parser.parse("title2:[Q TO V]"); assertTrue(query instanceof TermRangeQuery); Query query = parser.parse("title2:{Q TO \"Tapestry in action\"}");
4. 短语查询:
//短语查询 QueryParse parser = new QueryParser(Version.LUCENE_30, "field", new StandardAnalyzer(Version.LUCENE_30)); Query q = parser.parse("\"This is Some Phrase*\""); assertEquals("analyzed", "\"? ? Some Phrase\"", q.toString("field")) QueryParse parser = new QueryParser(Version.LUCENE_30, "field", analyzer); Query q = parser.parse("\"term\""); assertTrue("reduced to TermQuery", q instanceof TermQuery);
5. 布尔操作符:
//布尔操作符 QueryParse parser = new QueryParser(Version.LUCENE_30, "contents", analyzer); parser.setDefaultOperator(QueryParser.AND_OPERATOR);
6. 前缀查询和通配符查询:
//前缀和通配符查询 QueryParse parser = new QueryParser(Version.LUCENE_30, "filed", analyzer); Query query = parser.parse("prefixQuery*"); assertEquals("lowercased", "prefixQuery*", q.toString("field"))
7. 数值范围搜索和日期范围搜索:
8. 模糊查询:
QueryParse parser = new QueryParser(Version.LUCENE_30, "subject", analyzer); Query q = parser.parse("kountry~"); System.out.printfln("fuzzy: " + query); // fuzzy: subject:kountry~0.5 query = parser.parse("kountry~0-7"); System.out.printfln("fuzzy 2: " + query); // fuzzy: subject:kountry~0.7
9. MatchAllDocsQuery:
10. 分组查询:
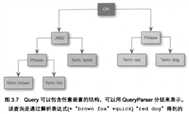
//QueryParser 使用分组后的文本类型的查询表达式来支持嵌套 BooleanQuery 子句查询 QueryParse parser = new QueryParser(Version.LUCENE_30, "subject", analyzer); Query q = parser.parse("(agile OR extreme) AND methodology");
11. 域选择:
12. 对子查询设置加权:
java //————默认域包括 java 项的文档 java junit //————默认域包括 java 和 junit 中一个或两个项的文档 java OR junit //————默认域包括 java 和 junit 中一个或两个项的文档 +java +junit //————默认域包括 java 和 junit 两项的文档 title:java //————title 域中包含 ant 项的文档 title:extreme -subject:sports //————title 域中包含 extreme 且 subject 域中不包含 sports 的文档 tielt:extreme AND NOT subject:sports //————title 域中包含 extreme 且 subject 域中不包含 sports 的文档 (agile OR extreme) AND methodogy //————默认域中包含 methodogy 且包含 agile 和 extreme 中一个或两个的文档 title:"junit in action" //————title 域为 junit in action 的文档 title:"junit action" -5 //————title 域中junit 和 action之 间距离小于5的文档 java* //————包含由 java 开头的文档 java- //————包含与单词 java 相近的单词 lastmodified:[1/1/09 TO 12/31/09] //————lastmodified 域值在这个时间区间的文档
QueryParse 在各个项中使用反斜杠来表示转义,需要转义的字符有:
+ - ! ( ) : ^ ] { } _ * ?
将首次搜索获得的多页结果手机起来保存在 ScoreDocs 和 IndexSearcher 实例中。
每次用户换页浏览时候都重新进行查询操作
使用一个打开的 IndexWriter 快速搜索索引的变更内容,而不必首先关闭 writer 或向该 writer 提交。
标签:
原文地址:http://www.cnblogs.com/licongyu/p/5452603.html