标签:
一、Hibernate开发流程
Hibernate是一个面向Java环境的对象/关系数据库映射工具,用来把对象模型表示的对象映射到基于SQL的关系模型数据结构中去。主要是完成面向对象的编程语言到关系型数据库的映射
Hibernate的开发流程一般有如下几个步骤:
1、编写domain对象:持久化类。
2、加入hibernate.jar和其依赖的包。
3、编写XX.hbm.xml映射文件。
4、编写hibernate.cfg.xml配置文件。必须要提供以下几个参数:connection.driver_class、connection.url、connection.username、connection.password、dialect、hbm2ddl.auto。
5、编写HibernateUtil工具类、主要用于完成hibernate的初始化过程和提供一个获得session的方法(可选)。
6、编写实现类。
二、Hibernate的体系结构
Hibernate有如下三种体系结构:
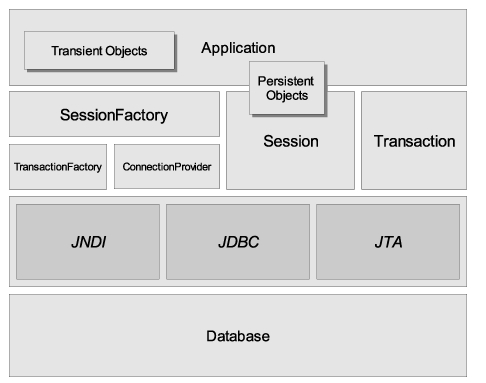
非常简要的Hibernate体系结构的概要图:

从这个图可以看出,Hibernate使用数据库和配置信息来为应用程序提供持久化服务(以及持久的对象)。
轻型”的体系结构方案,它要求应用程序提供自己的JDBC 连接并管理自己的事务

全面解决”的体系结构方案,将应用层从底层的JDBC/JTA API中抽象出来,而让Hibernate来处理这些细节。
三、Hibernate的持久化类
Hibernate采用完全面向对象的方式来操作数据库,通过Hibernate的支持,我们只需要管理对象的状态,无须关心底层数据库系统的细节。
虽然Hibernate对持久化类没有太多的要求,但是我们应该遵循如下规则:
1、提供一个无参的构造函数。
2、提供一个标识属性。
3、为持久化类的每个属性听过getter和setter方法
4、使用非final类
持久化对象有如下几个对象状态:
1、瞬态:对象有new操作符创建,且尚未与Hibernate Session关联的对象被认为处于瞬态。
2、持久化:持久化实例在数据库中有对应的记录,并且拥有一个持久化标识
3、托管:某个实例曾经处于持久化状态,但随着与之关联的Session被关闭了额,那么该对象就变成了托管状态。
三种状态的演变图如下:
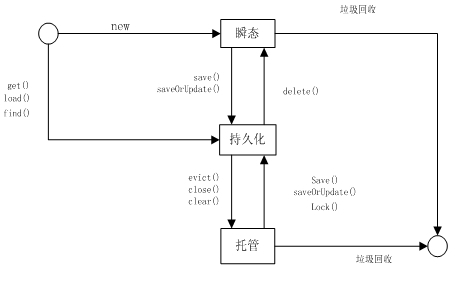
Hibernate提供save()、persist()方法可以将对象转变为持久化状态。但是两个方法存在一点区别:save()方法保存持久化对象时,该方法返回持久化对象的标识属性值,而且他会立即将持久化对象的数据插入到数据库中。但是persist()方法就没有任何返回值,它保证当他在一个事务外部被调用时,并不会立即转换成insert语句,这个特性对于我们在封装一个长回话流程的时候,显得很重要。
同时我们还可以通过load()和get()方法来加载一个持久化对象。两者都是根据主键装载持久化实例的。但是两者的区别就在于:get()方法会立即加载,而load()方法会延迟加载。
四、Hibernate的配置:hibernate.cfg.xml和映射文件
Hibernate进行持久化操作时是离不开SessionFactory对象,这个对象是整个数据库映射关系经过编译后的内存镜像。该对象由Configuration对象产生的。Configuration对象代表了应用程序到数据库的映射配置。创建Configuration对象,通常有如下几种配置Hibernate的方式。
1、使用hibernate.cfg.xml文件作为配置文件
2、使用hibernate.properties文件作为配置文件
3、不适用任何配置文件,以编码方式创建Configuration对象
其中hibernate.cfg.xml文件是最常用的。对于hibernate.cfg.xml而言,必须要提供以下几个参数:
connection.driver_class:设置连接数据库的驱动。
connection.url:设置所需要连接数据库服务的URL。
connection.username:连接数据的用户名。
connection.password:连接数据的密码
dialect:设置连接数据库使用的方言
hbm2ddl.auto:设置当创建SessionFactory时,是否根据映射文件自动建立数据。
一般hibernate.cfg.xml的配置文件如下(以SQL2005为例):
我们在创建持久化对象后,一般都需要为他提供一个Xxx.hbm.xml映射文件。该映射文件提供了对象到数据库之间的映射关系。是连接持久化对象和数据库之间的桥梁。
对于映射文件,以<hibernate-mapping.../>元素为根元素,该元素下可以拥有多个<class.../>子元素,一个<class.../>元素对应一个持久化类。
其基本形式如下:
五、Hibernate映射集合属性
集合属性是很常见的。集合属性一般分为两种,一种是单纯的集合属性,如List、Set或者数组等集合属性,另一种是map结构的集合属性,每个属性值都有对应的key映射。
集合映射的元素大致有如下这些:
1、list:用于映射List集合属性
2、set:用于映射Set集合属性
3、map:用于映射Map集合属性
4、array:用于影视数组集合属性
5、primitive-array:用于映射基本数据类型的数组
6、bag:用于应射无序集合
7、idbag:用于映射无序集合,但是为集合增加了逻辑次序
注意:
1、两个持久化对象不能共享同一个集合元素的引用
2、因为集合属性都需要保存在另一个数据表中个,所以需要指定一个外键列,用于参照到主键列
3、在所有的结合映射中,除了<set.../>和<bag.../>元素外,都需要为集合元素的数据表指定一个索引列。
下面是集合属性的基本配置:
1、List集合属性
List集合属性采用<list.../>元素进行映射,同时还需要使用<list-index.../>子元素来映射list属性的索引列,同时还需要增加<key.../>元素来映射外键列。
2、数组属性
数组属性采用<array../>元素进行映射。
3、Set集合属性
Set集合属性采用<set.../>元素进行映射。因为Set是无序,不可重复的,所以它不需要使用<list-index../>元素来映射索引列。Set也需要使用<key.../>元素来映射外键列。
4、bag元素映射
<bag../>元素只需要<key.../>元素来映射关联的外键列,<element.../>元素来映射集合属性的元素列。
使用<bag.../>元素可以映射List集合属性、Set集合属性、Collection集合属性。但是使用<bag../>元素都将会被映射成无序集合,而且集合对应的表没有主键。
5、Map集合属性
Map集合属性需要使用<map.../>元素进行映射。它除了需要使用<key.../>元素映射外键列,<element.../>元素来映射集合属性的元素列。还需要使用<map-key.../>元素映射map key.
Map集合属性是以外键列和key列作为联合主键。
六、Hibernate映射组件属性
组件属性标志着该属性并不是一个简单的基本数据类型、字符串、日期的变量,而是一个符合类型的对象。
在映射组件属性中,Hibernate提供了<component.../>元素进行映射,每一个<component.../>元素映射一个组件属性。使用<component.../>元素时需要指定一个name属性,该属性用于指定该组件属性的名称。
当集合属性的元素作为组件时,我们需要使用<composite-element.../>来映射了。使用<composite-element.../>元素时需要指定一个class属性,该属性值指定了集合里组件对象的类型。
七、Hibernate的关联映射
Hibernate的关联关系有两种:单向、双向。
其中单向关联分为:1-1、1-N、N-1、N-N。
双向关联分为:1-1、1-N、N-N。
7.1、单向N-1关联
对于单向N-1关联,只需要在在N的一端的持久化类增加一个属性,该属性引用1的一端的关联实体。
1、无连接表的N-1关联(基于外键)
Hibernate使用<many-to-one.../>元素映射N-1的关联实体。N的一端采用<many-to-one.../>元素来映射关联关系,同时需要增加一个外键列,用来参照主表记录。1的一端保存不变。
注意:对于所有的基于外键约束关联关系中,都必须这样:要么总是持久化主表对应的实体,要么设置级联操作(cascade="all")。
2、基于连接表的N-1关联
对于基于有连接表的关联关系,需要使用<join.../>元素来映射。<join.../>元素用于强制将一个类的属性映射到多张表中。
在这里映射文件中这样:N的一端使用<join.../>元素来映射关联关系,同时还需要增加<key.../>子元素来映射外键,并且为<join.../>元素增加<many-to-one.../>子元素,用来映射N-1的关联实体。同样1的一端不变。
7.2、单向1-1关联
对于1-1关联而言,它有三种关联映射策略:基于外键、基于连接表、基于主键。
1、基于外键的单向1-1关联
基于外键的1-1关联映射与基于外键的N-1的映射文件几乎没有什么区别,只需要在<many-to-one../>元素中指定unique="true"即可实现。
2、基于连接表的单向1-1关联
基于连接表的1-1关联映射与基于连接表的N-1的映射也没有什么区别,同样只需要在<many-to-one../>元素中指定unique="true"即可实现。
3、基于主键的单向1-1关联
对于基于主键的1-1关联映射,它的持久化类不能有自己的主键生成器策略,它的主键应该有关联实体来负责生成。
采用<one-to-one.../>元素来映射基于主键的1-1关联。同时应该给该元素指定一个name属性,该属性的值指定关联实体属性的属性名。
7.3、单向1-N关联
对于单向1-N关联关系的持久化类,1的一端需要访问N的一端,而N的一端应该以集合的形式表现。
1、基于无连接表的单向1-N
在N的一端需要映射集合属性,还要使用<one-to-many.../>来映射关联实体。
2、基于有连接表的单向1-N
对于有连接表的1-N关联映射,映射文件使用<many-to-many.../>元素来映射关联实体,但为了保证当前实体是1的一端,需要增加unique="true"属性来指定。
7.4、单向N-N关联
单向的N-N关联与1-N关联的持久化类完全相同,控制关系的一端需要增加一个Set类型的属性,被关联的持久化类实体以集合形式存在。
映射文件也相同,只需要去掉unique="true"即可。
7.5、双向1-N关联
双向的1-N关联的持久化类,N的一端增加引用到关联实体的属性,1的一端增加集合属性,集合元素为关联实体。
1、基于无连接表的双向1-N关联
对于基于无连接表的双向1-N关联的映射文件,需要在N的一端增加<many-to-one.../>元素来映射关联属性。而1的一端则需要使用<set.../>或者<bag.../>元素来映射关联属性,同时还需要增加<key.../>子元素映射外键列,并使用<one-to-many.../>子元素映射关联属性。此外由于对于1-N关联关系中,我们一般都是有N的一端来控制关联关系,所以我们需要在<set.../>元素中指定inverse="true",用来指定1的一端不控制关联关系。
1的一端的映射文件
N的一端的映射文件
2、基于连接表的双向1-N关联
1的一端使用集合元素映射,然后在集合元素里增加<many-to-many.../>子元素,该子元素映射到关联类,同时在该子元素中增加unique="true"属性以保证该实体是1的一端。N的一端则使用<join.../>元素来强制使用连接表。
1的一端映射文件
N的一端映射文件
这里必须要保证以下三队相等:两个table的值要相等、<set.../>元素里的<key../>的column属性的值与<join.../>元素里的<many-to-one../>的column属性的值相等、<set.../>元素里的<many-to-many.../>的column属性的值与<join.../>元素里的<key.../>的column属性的值相等。
7.6、双向N-N关联
双向N-N关联需要两端都使用Set集合属性,两端都增加对集合属性的访问。
7.7、双向1-1关联
双向的1-1关联同样有这样三种映射方式:基于外键、基于连接表、基于主键
1、基于外键的双向1-1关联
基于外键的1-1关联,外键可以存放在任意一边。需要存放外键的一端,需要增加<many-to-many.../>元素,这里需要为<many-to-many.../>元素增加unique="true"属性来表示该实体实际上是1的一端。
另一端需要使用<one-to-one.../>元素,该<one-to-one.../>元素需要使用name属性指定关联属性名,同时使用property-ref属性指定引用关联类的属性。
2、基于连接表的双向关联
双向1-1关联两端都需要使用<join../>元素强制使用连接表,还需要在两端增加<many-to-one.../>元素映射关联属性,两个<many-to-many.../>元素都应该增加unique="true"
3、基于主键的双向关联
在任意一端采用foreign主键生成器策略。两端同时使用<one-to-one.../>元素映射关联实体。
这里关于关联映射要注意以下几点:
1、对于所有的基于外键约束的关联关系中,要么选择先持久化主表记录对应的实体,要么是有级联操作
2、对于1-N关联关系而言,我们一般都采用N的一端控制关联关系
3、N-N的关联关系都需要使用连接表策略来进行映射
4、单向关联更加难于查询。在大型应用中,几乎所有的关联必须在查询中可以双向导航。
7.8、组件属性包含的关联实体
对于组件属性的关联实体的映射文件使用<component.../>元素来映射该组件属性,然后在<component.../>元素里使用<set../>元素1-N关联实体。
八、Hibernate的批量处理
Hibernate在对大数据进行更新的时候,会抛出OutOfMemoryException(内存溢出)异常。有如下方案解决这个问题:定时将Session缓存的数据刷入数据库。设计一个累加器,每次更新一次数据,累加器就加1更加累加器的值决定是否需要将Session缓存中的数据刷入数据库。
同时也可以使用DML风格进行批量处理。
九、Hibernate的继承映射策略
对于面向对象的程序设计的语言,继承、多态是两个最基本的概念。Hibernate的继承映射可以理解两个持久化类之间的继承关系。Hibernate采用如下三种策略来完成继承映射:subclass、joined-subclass、union-subclass。
subclass:采用这种映射策略时,整个继承树的所有实例都保存在同一张表中。这样做的好处就是不管进行怎样的查询,不管查询继承树中的那一层实体,底层数据库都只需在一张表中查询,无需进行多表查询,但是底层数据表结构不是很清楚。在这种映射策略下,需要增加一个辨别者列:discriminator元素来区分每行记录到底是那个类的实体。
joined-subclass:采用这种映射策略时,父类实例保存在父类表里,而子类实例则由父类表和子类表共同存储。也就是说父类表保存两者共有的属性,子类表保存子类独有的属性。
在这种映射策略下,需要为每个子类使用<key.../>元素映射共有主键---该主键还将参照父类表的主键。使用该继承映射进行查询子类实例时,需要跨表查询,其中的深度要取决于该子类有多少层父类。
union-subclass:采用这种映射策略,父类实例的数据保存在父类表中,子类实例和父类实例的数据共同保存在子类表中。其中子类实例的数据在父类表中没有任何记录。对于这种继承策略,底层数据库的表结构更加符合正常情况下的数据库设计。注意:在采用这种继承映射策略时,映射持久化类时不要使用identity主键生成策略。
十、Hibernate的查询体系
Hibernate提供了强大的查询体系,可以使用如下三种方式使用Hibernate查询:HQL查询、条件查询、SQL查询。
1、HQL查询
HQL查询是完全面向对象的查询语言。它依赖于Query对象,每一个Query实例对应一个查询对象。使用HQL查询按如下步骤进行:
1、获取Hibernate Session对象。
2、编写HQL语句。
3、以HQL语句为参数,调用Session的createQuery方法创建Query查询对象。
4、如果HQL语句包含参数,则调用Query的setXxx方法为参数赋值。
5、调用Query对象的list等方法返回查询结果集。
2、条件查询
条件查询时更具面向对象特色的数据查询方式。条件查询通过如下三个类完成:
Criteria:代表一次查询。
Criterion:代表一个查询条件。
Restrictions:代表查询条件的工具类。
执行条件查询步骤如下:
1、获得Hibernate Session对象。
2、以Session对象创建Criteria对象。
3、使用Restrictions的静态方法创建Criterion查询条件。
4、向Criteria查询中添加Criterion查询条件。
5、执行Criteria的list()或者uniqueResult()方法返回结果集。
3、SQL查询
SQL查询时通过SQLQuery接口来表示的。SQLQuery接口是Query接口的子接口。
执行SQL查询的步骤如下:
1、获取Hibernate Session对象。
2、编写SQL语句。
3、以SQL语句作为参数,调用Session的createSQLQuery方法创建查询对象。
4、调用SQLQuery对象的addScalar()或者addEntity()方法将选出的结果与标量值或者实体进行关联,分别用于进行标量查询或者实体查询。
5、如果SQL语句包含参数,调用Query的setXxx方法为参数赋值。
6、调用Query的list方法返回查询的结果集。
标量查询:
实体查询:
十一、Hibernate的数据过滤
数据过滤就是对数据进行筛选。一旦启用了数据过滤器,则不管是数据查询,还是数据加载,该过滤器将自动作用与所有数据。
数据过滤器分三步:
1、定义过滤器。使用<filter-def.../>元素定义。
2、使用过滤器。使用<filter.../>元素应用。
3、启用过滤器。在代码中通过Session启用。
十二、Hibernate的缓存
Hibernate的缓存有一级缓存和二级缓存。一级缓存是Session级别的,是一个局部缓存,只对当前Session有效。而二级缓存是SessionFactory级别的,是全局缓存,它对所有的Session都有效。
对于一级缓存而言,所有经它操作的实体,不管是使用save()、update()、savaOrUpdate()
保存对象,还是使用load()、get()、list()、iterate()、scroll()方法获得一个对象,session都会将该对象放入缓存中去。在这里我们要注意:当Session操作大批数据时,要注意它会抛出内存溢出异常。
对于二级缓存,Hibernate默认是关闭的。在使用二级缓存时,我们需要经过如下步骤:
1、在Hibernate.cfg.xml文件中开启二级缓存。
2、复制二级缓存的JAR包。
3、将缓存实现所需要的配置文件添加到系统的类加载路径在中。
4、设置对那些实体类、实体的那些熟悉启用二级缓存。
为了更好的管理二级缓存,我们可以使用二级缓存的统计功能。
<property name="generate_statistics">true</property>
通过查看二级缓存的内容,我们可以更好的管理二级缓存。
十三、Hibernate的事件机制
通过事件机制,Hibernate允许应用程序能够响应特定的内部事件,从而允许实现某些通用的功能或者对Hibernate功能进行扩展。
Hibernate的事件机制框架有两种“
1、拦截器机制:对于特定的动作拦截,回调应用中的特定动作。
2、事件系统:重写Hibernate的事件监听器。
拦截器
通过Interceptor接口,可以在数据进入数据库之前,对数据进行最后的检查。
使用拦截器按如下步骤进行:
1、定义实现Interceptor接口的拦截器类
2、通过Session启用拦截器,或者通过Configuration启用全局拦截器。
在使用拦截器时,可以通过如下两种方法实现:
1、通过SessionFactory的openSession方法打开一个带局部拦截器的Session。
2、通过Configuration的setInterceptor()方法设置全局拦截器。
事件系统
Session接口的每个方法都有对应的事件,当Session调用某个方法时,Hibernate Session会产生对应的事件,并激活对应的事件监听器。
使用事件系统按如下步骤:
1、实现自己的事件监听器类。
2、注册自定义事件监听器,代替系统默认的事件监听器。
实现用户的自定义监听器有如下三种方法:
1、实现对应的监听器接口。
2、继承事件适配器。
3、继承系统默认的事件监听器:扩展特定的方法。(推荐)。
Hibernate读书笔记-----Hibernate知识总结
标签:
原文地址:http://blog.csdn.net/u013310119/article/details/51328595