filter()函数是 Python 内置的另一个有用的高阶函数,filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。
例如,要从一个list [1, 4, 6, 7, 9, 12, 17]中删除偶数,保留奇数,首先,要编写一个判断奇数的函数:
def is_odd(x):
return x % 2 == 1
然后,利用filter()过滤掉偶数:
filter(is_odd, [1, 4, 6, 7, 9, 12, 17])
结果:[1, 7, 9, 17]
利用filter(),可以完成很多有用的功能,例如,删除 None 或者空字符串:
def is_not_empty(s):
return s and len(s.strip()) > 0
filter(is_not_empty, [‘test‘, None, ‘‘, ‘str‘, ‘ ‘, ‘END‘])
结果:[‘test‘, ‘str‘, ‘END‘]
注意: s.strip(rm) 删除 s 字符串中开头、结尾处的 rm 序列的字符。
当rm为空时,默认删除空白符(包括‘\n‘, ‘\r‘, ‘\t‘, ‘ ‘),如下:
a = ‘ 123‘
a.strip()
结果: ‘123‘
a=‘\t\t123\r\n‘
a.strip()
结果:‘123‘
自定义排序函数
Python内置的 sorted()函数可对list进行排序:
>>>sorted([36, 5, 12, 9, 21])
[5, 9, 12, 21, 36]
但 sorted()也是一个高阶函数,它可以接收一个比较函数来实现自定义排序,比较函数的定义是,传入两个待比较的元素 x, y,如果 x 应该排在 y 的前面,返回 -1,如果 x 应该排在 y 的后面,返回 1。如果 x 和 y 相等,返回 0。
因此,如果我们要实现倒序排序,只需要编写一个reversed_cmp函数:
def reversed_cmp(x, y):
if x > y:
return -1
if x < y:
return 1
return 0
这样,调用 sorted() 并传入 reversed_cmp 就可以实现倒序排序:
>>> sorted([36, 5, 12, 9, 21], reversed_cmp)
[36, 21, 12, 9, 5]
sorted()也可以对字符串进行排序,字符串默认按照ASCII大小来比较:
>>> sorted([‘bob‘, ‘about‘, ‘Zoo‘, ‘Credit‘])
[‘Credit‘, ‘Zoo‘, ‘about‘, ‘bob‘]
‘Zoo‘排在‘about‘之前是因为‘Z‘的ASCII码比‘a‘小。
返回函数
Python的函数不但可以返回int、str、list、dict等数据类型,还可以返回函数!
例如,定义一个函数 f(),我们让它返回一个函数 g,可以这样写:
def f():
print ‘call f()...‘
# 定义函数g:
def g():
print ‘call g()...‘
# 返回函数g:
return g
仔细观察上面的函数定义,我们在函数 f 内部又定义了一个函数 g。由于函数 g 也是一个对象,函数名 g 就是指向函数 g 的变量,所以,最外层函数 f 可以返回变量 g,也就是函数 g 本身。
调用函数 f,我们会得到 f 返回的一个函数:
>>> x = f() # 调用f()
call f()...
>>> x # 变量x是f()返回的函数:
<function g at 0x1037bf320>
>>> x() # x指向函数,因此可以调用
call g()... # 调用x()就是执行g()函数定义的代码
请注意区分返回函数和返回值:
def myabs():
return abs # 返回函数
def myabs2(x):
return abs(x) # 返回函数调用的结果,返回值是一个数值
返回函数可以把一些计算延迟执行。例如,如果定义一个普通的求和函数:
def calc_sum(lst):
return sum(lst)
调用calc_sum()函数时,将立刻计算并得到结果:
>>> calc_sum([1, 2, 3, 4])
10
但是,如果返回一个函数,就可以“延迟计算”:
def calc_sum(lst):
def lazy_sum():
return sum(lst)
return lazy_sum
# 调用calc_sum()并没有计算出结果,而是返回函数:
>>> f = calc_sum([1, 2, 3, 4])
>>> f
<function lazy_sum at 0x1037bfaa0>
# 对返回的函数进行调用时,才计算出结果:
>>> f()
10
由于可以返回函数,我们在后续代码里就可以决定到底要不要调用该函数。
闭包
在函数内部定义的函数和外部定义的函数是一样的,只是他们无法被外部访问:
def g():
print ‘g()...‘
def f():
print ‘f()...‘
return g
将 g 的定义移入函数 f 内部,防止其他代码调用 g:
def f():
print ‘f()...‘
def g():
print ‘g()...‘
return g
但是,考察上一小节定义的 calc_sum 函数:
def calc_sum(lst):
def lazy_sum():
return sum(lst)
return lazy_sum
注意: 发现没法把 lazy_sum 移到 calc_sum 的外部,因为它引用了 calc_sum 的参数 lst。
像这种内层函数引用了外层函数的变量(参数也算变量),然后返回内层函数的情况,称为闭包(Closure)。
闭包的特点是返回的函数还引用了外层函数的局部变量,所以,要正确使用闭包,就要确保引用的局部变量在函数返回后不能变。举例如下:
# 希望一次返回3个函数,分别计算1x1,2x2,3x3:
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
你可能认为调用f1(),f2()和f3()结果应该是1,4,9,但实际结果全部都是 9(请自己动手验证)。
原因就是当count()函数返回了3个函数时,这3个函数所引用的变量 i 的值已经变成了3。由于f1、f2、f3并没有被调用,所以,此时他们并未计算 i*i,当 f1 被调用时:
>>> f1()
9 # 因为f1现在才计算i*i,但现在i的值已经变为3
因此,返回函数不要引用任何循环变量,或者后续会发生变化的变量。
匿名函数
高阶函数可以接收函数做参数,有些时候,我们不需要显式地定义函数,直接传入匿名函数更方便。
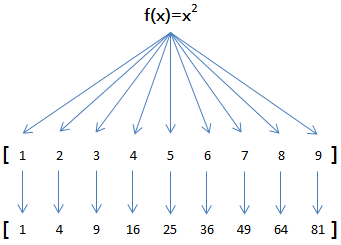
在Python中,对匿名函数提供了有限支持。还是以map()函数为例,计算 f(x)=x2 时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
>>> map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9])
[1, 4, 9, 16, 25, 36, 49, 64, 81]
通过对比可以看出,匿名函数 lambda x: x * x 实际上就是:
def f(x):
return x * x
关键字lambda 表示匿名函数,冒号前面的 x 表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不写return,返回值就是该表达式的结果。
使用匿名函数,可以不必定义函数名,直接创建一个函数对象,很多时候可以简化代码:
>>> sorted([1, 3, 9, 5, 0], lambda x,y: -cmp(x,y))
[9, 5, 3, 1, 0]
返回函数的时候,也可以返回匿名函数:
>>> myabs = lambda x: -x if x < 0 else x
>>> myabs(-1)
1
>>> myabs(1)
1
偏函数
当一个函数有很多参数时,调用者就需要提供多个参数。如果减少参数个数,就可以简化调用者的负担。
比如,int()函数可以把字符串转换为整数,当仅传入字符串时,int()函数默认按十进制转换:
>>> int(‘12345‘)
12345
但int()函数还提供额外的base参数,默认值为10。如果传入base参数,就可以做 N 进制的转换:
>>> int(‘12345‘, base=8)
5349
>>> int(‘12345‘, 16)
74565
假设要转换大量的二进制字符串,每次都传入int(x, base=2)非常麻烦,于是,我们想到,可以定义一个int2()的函数,默认把base=2传进去:
def int2(x, base=2):
return int(x, base)
这样,我们转换二进制就非常方便了:
>>> int2(‘1000000‘)
64
>>> int2(‘1010101‘)
85
functools.partial就是帮助我们创建一个偏函数的,不需要我们自己定义int2(),可以直接使用下面的代码创建一个新的函数int2:
>>> import functools
>>> int2 = functools.partial(int, base=2)
>>> int2(‘1000000‘)
64
>>> int2(‘1010101‘)
85
所以,functools.partial可以把一个参数多的函数变成一个参数少的新函数,少的参数需要在创建时指定默认值,这样,新函数调用的难度就降低了。
模块和包的概念
当代码越来越多的时候,把所有的代码写到同一个文件里面,是没法维护的。如果将代码分拆放到多个文件当中,同一个名字的变量互不影响,只要它们在不同的py文件中。模块的名字就是py文件的文件名。

在一个模块中也可以引用其他的模块,引用其他模块中定义的函数或变量。

模块多了以后,也很容易重名。当模块名冲突时,解决方法是同名模块放入不同的包中。报名.模块名 就可以了。在文件系统中,包就是文件夹,模块就是.py文件。那如何区分包和普通的目录呢?在python中,包下面有个_init_.py文件,而且包的每一层都要有,即使是空的也要有,这样python才能把这个目录当成一个包来处理。
导入模块
要使用一个模块,我们必须首先导入该模块。Python使用import语句导入一个模块。例如,导入系统自带的模块 math:
import math
你可以认为math就是一个指向已导入模块的变量,通过该变量,我们可以访问math模块中所定义的所有公开的函数、变量和类:
>>> math.pow(2, 0.5) # pow是函数
1.4142135623730951
>>> math.pi # pi是变量
3.141592653589793
如果我们只希望导入用到的math模块的某几个函数,而不是所有函数,可以用下面的语句:
from math import pow, sin, log
这样,可以直接引用 pow, sin, log 这3个函数,但math的其他函数没有导入进来:
>>> pow(2, 10)
1024.0
>>> sin(3.14)
0.0015926529164868282
如果遇到名字冲突怎么办?比如math模块有一个log函数,logging模块也有一个log函数,如果同时使用,如何解决名字冲突?
如果使用import导入模块名,由于必须通过模块名引用函数名,因此不存在冲突:
import math, logging
print math.log(10) # 调用的是math的log函数
logging.log(10, ‘something‘) # 调用的是logging的log函数
如果使用 from...import 导入 log 函数,势必引起冲突。这时,可以给函数起个“别名”来避免冲突:
from math import log
from logging import log as logger # logging的log现在变成了logger
print log(10) # 调用的是math的log
logger(10, ‘import from logging‘) # 调用的是logging的log
动态导入模块
如果导入的模块不存在,Python解释器会报 ImportError 错误:
>>> import something
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: No module named something
有的时候,两个不同的模块提供了相同的功能,比如 StringIO 和 cStringIO 都提供了StringIO这个功能。
这是因为Python是动态语言,解释执行,因此Python代码运行速度慢。
如果要提高Python代码的运行速度,最简单的方法是把某些关键函数用 C 语言重写,这样就能大大提高执行速度。
同样的功能,StringIO 是纯Python代码编写的,而 cStringIO 部分函数是 C 写的,因此 cStringIO 运行速度更快。
利用ImportError错误,我们经常在Python中动态导入模块:
try:
from cStringIO import StringIO
except ImportError:
from StringIO import StringIO
上述代码先尝试从cStringIO导入,如果失败了(比如cStringIO没有被安装),再尝试从StringIO导入。这样,如果cStringIO模块存在,则我们将获得更快的运行速度,如果cStringIO不存在,则顶多代码运行速度会变慢,但不会影响代码的正常执行。
try 的作用是捕获错误,并在捕获到指定错误时执行 except 语句。
使用__future__
Python的新版本会引入新的功能,但是,实际上这些功能在上一个老版本中就已经存在了。要“试用”某一新的特性,就可以通过导入__future__模块的某些功能来实现。
例如,Python 2.7的整数除法运算结果仍是整数:
>>> 10 / 3
3
但是,Python 3.x已经改进了整数的除法运算,“/”除将得到浮点数,“//”除才仍是整数:
>>> 10 / 3
3.3333333333333335
>>> 10 // 3
3
要在Python 2.7中引入3.x的除法规则,导入__future__的division:
>>> from __future__ import division
>>> print 10 / 3
3.3333333333333335
当新版本的一个特性与旧版本不兼容时,该特性将会在旧版本中添加到__future__中,以便旧的代码能在旧版本中测试新特性。