标签:
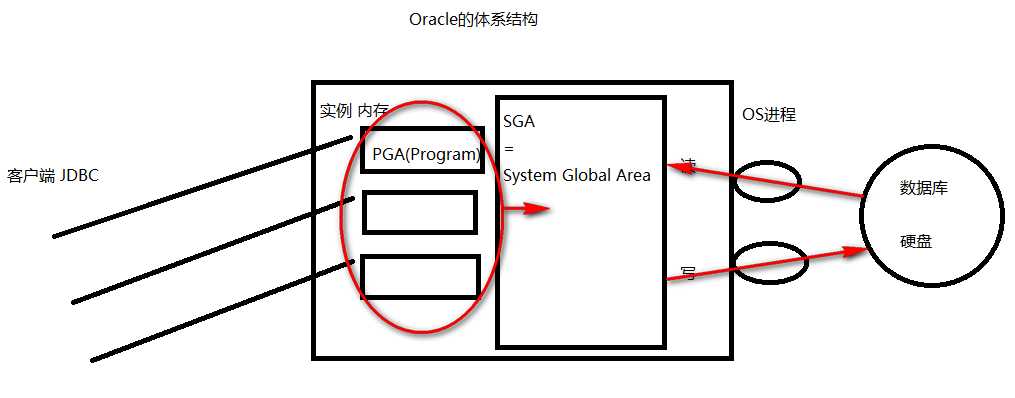
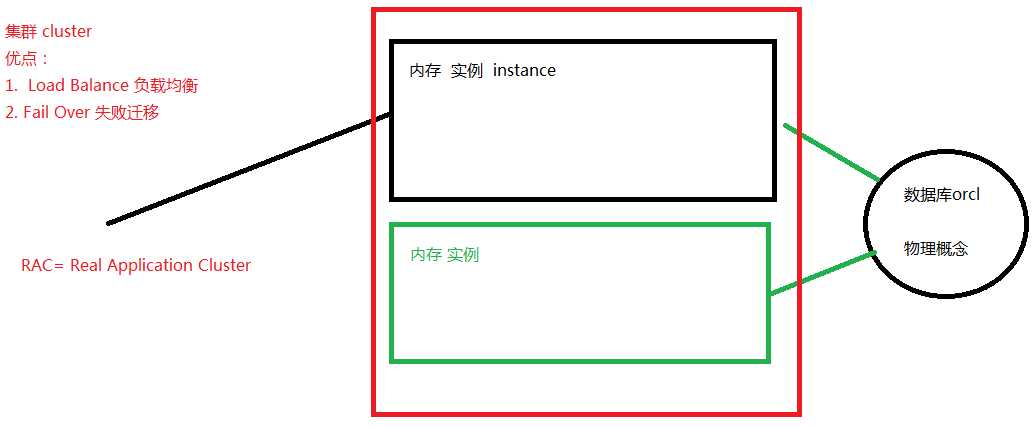


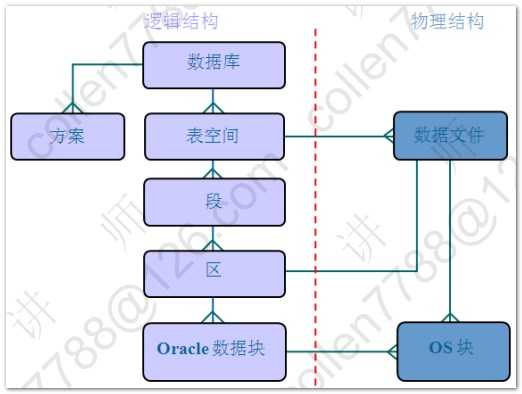
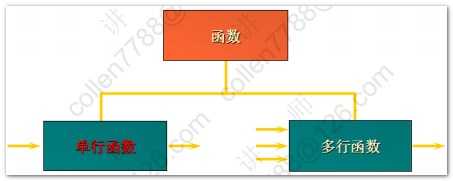
1.基本的登录语句:
--登录Oraclesqlplus scott/tiger@192.168.56.101:1521/orcl--清屏host cls--当前用户show userUSER 为 "SCOTT"
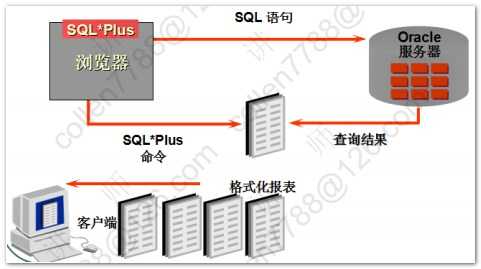
jdbc:oracle:thin:@localhost:1521:orcljdbc:oracle:oci:@loaclhost:1521:orcl
第一种方式只需要一个jar包,第二种方式更复杂一些(功能更强大)。
--开始记录spool d:\1.txt--结束记录spool off
--当前用户下的表(oracle中必须要有from)select * from tab;--员工表的结构desc是describe的缩写desc emp--查询所有员工信息select * from emp;--显示设置行宽show linesize--结果linesize 80set linesize 120--设置列宽(col代表column,a表示字符类型,8表示长度为8,9表示以为数字,9999表示四个数字,for是format的缩写)col ename for a8col sal for 9999--/表示引用上面的sql语句/
--通过列名查询select empno,ename,job,mgr,hiredate,sal,comm,deptno form emp;--第 2 行出现错误: ORA-00923: 未找到要求的 FROM 关键字--c命令 change缩写--指定第二行2--结果:2* form emp--/form原错误值/from新值c /form/from--改正结果:2* from emp--/代表引用上面的sql语句/
将comm奖金中的null值变成0,从而不会出现总薪水的值为null
select empno,ename,sal,sal*12,comm,sal*12+nvl(comm,0) from emp;
--ed是edit的缩写ed--结果:已写入 file afiedt.buf--执行sql语句/
"别名"或者不加引号,区别:别名中有空格或者关键字必须加上双引号
1 2 | --别名的使用select empno as "员工号",ename "姓名",sal "月 薪",sal*12,comm,sal*12+nvl(comm,0) from emp |
1 2 3 4 5 6 7 8 9 10 11 12 13 | --distinct去掉重复记录select distinct deptno from emp;--字符串连接--distinct作用于后面所有的列select distinct deptno,job from emp;--连接符--concatselect concat('Hello',' World');--dual: 伪表select 'hello'||' world' 字符串 from dual; |
 |  |
 |  |
 |  |
 |  |
 |  |
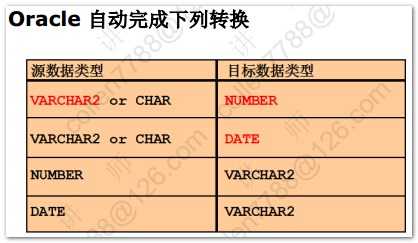
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | --字符串大小写敏感--查询名叫KING的员工select * from emp where ename='KING';--日期格式敏感--查询入职日期是17-11月-81的员工select * from emp where hiredate='17-11月-81';--默认格式:DD-MON-RR--查看日期格式select * from v$nls_parameters;--修改日期格式
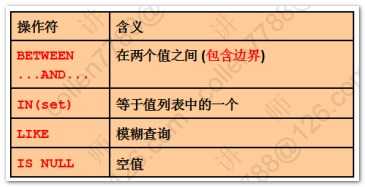
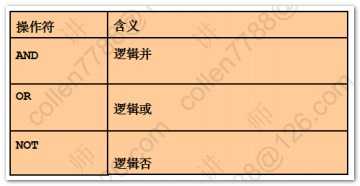
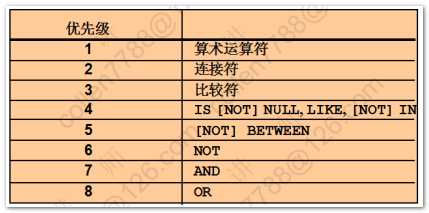
--修改成默认alter session set NLS_DATE_FORMAT='DD-MON-RR';--between and--查询工资1000~2000之间的员工select * from emp where sal between 1000 and 2000;--between and: 1. 包含边界 2. 小值在前 大值在后--in 在集合中--查询10和20号部门的员工select * from emp where deptno in (10,20);--null值 3. 如果集合中含有null,不能使用not in;但可以使用in--错误查找语句select * from emp where deptno not in (10,20,null)--like 模糊查询-- %(任意位数字符) _(一位字符)--查询名字以S打头的员工select * from emp where ename like 'S%';--\转义符号,转义_这个特殊符号select * from emp where ename like '%\_%' escape '\'--回退已完成,oracle自动开启事务,所以可以直接回滚rollback;--排序--查询员工信息,按照月薪排序select * from emp order by sal;--order by 后面 + 列,表达式,别名,序号select empno,ename,sal,sal*12 from emp order by sal*12 desc;--多个列排序(先按照第一个排序,相同时按照第二个排序)select * from emp order by deptno,sal;--order by 作用于后面所有的列;desc只作用于离他最近的一列select * from emp order by deptno desc,sal desc--查询员工信息,按照奖金排序--null 值 4. null的排序,默认情况下null最大select * from emp order by comm;--oracle默认进行分页,可以设置每页记录数set pagesize 20--a命令: append(在当前的sql语句的基础上添加desc)--a与后面的关键字之间要有两个空格(防止语句连到一起)a descselect * from emp order by comm desc nulls last(将null放到最后,默认情况下null最大) |
 |  |
 |  |
 |  |
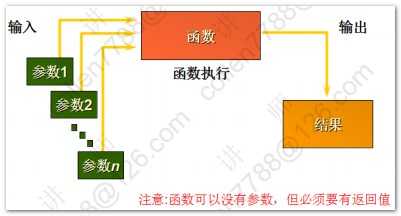
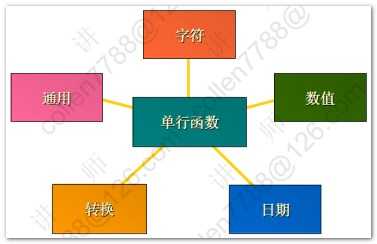
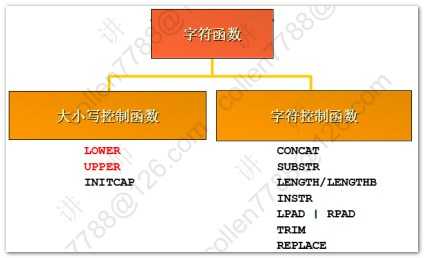
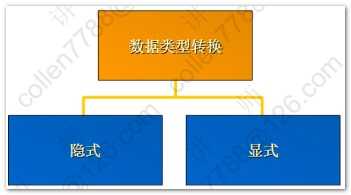
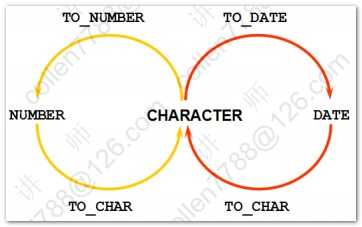
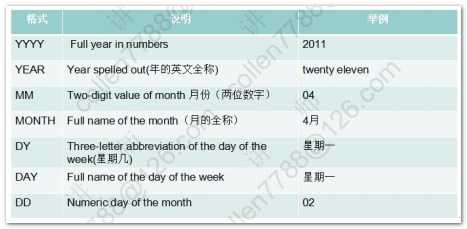
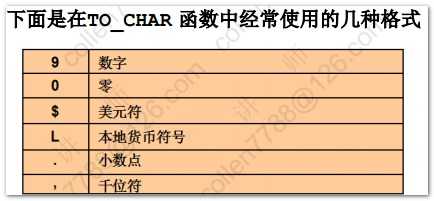
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 | --字符函数select lower('Hello WOrld') 转小写,upper('Hello WOrld') 转大写,initcap('hello world') 首字母大写 from dual;--substr(a,b) 从a中,第b位开始取select substr('Hello World',3) 子串 from dual;--substr(a,b,c) 从a中,第b位开始取,取c位select substr('Hello World',3,4) 子串 from dual;--length 字符数 lengthb 字节数(英文字符数和字节数相同,中文一个字符两个字节)select length('Hello World') 字符,lengthb('Hello World') 字节 from dual;--instr(a,b) 在a中,查找bselect instr('Hello World','ll') 位置 from dual;--lpad 左填充 rpad右填充-- abcd填充后共10位,左边右边分别填充特定符号select lpad('abcd',10,'*') 左,rpad('abcd',10,'*') 右 from dual;--trim 去掉前后指定的字符select trim('H' from 'Hello WorldH') from dual;--replaceselect replace('Hello World','l','*') from dual;--四舍五入select round(45.926,2) 一,round(45.926,1) 二,round(45.926,0) 三,round(45.926,-1) 四,round(45.926,-2) 五 from dual;--结果 一 二 三 四 五 ---------- ---------- ---------- ---------- ---------- 45.93 45.9 46 50 0 --截断函数select trunc(45.926,2) 一,trunc(45.926,1) 二,trunc(45.926,0) 三,trunc(45.926,-1) 四,trunc(45.926,-2) 五 from dual--查询当前时间select sysdate from dual;--将当前时间转换成特定格式select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;--系统的时间戳(将一秒划分成100,0000份)select to_char(systimestamp,'yyyy-mm-dd hh24:mi:ss:ff') from dual;--昨天 今天 明天select (sysdate-1) 昨天,sysdate 今天,(sysdate+1) 明天 from dual;--计算员工的工龄:天 星期 月 年select ename,hiredate,(sysdate-hiredate) 天,(sysdate-hiredate)/7 星期,(sysdate-hiredate)/30 月,(sysdate-hiredate)/365 年 from emp;--months_between(第一个参数如果比第二个参数小,就会计算出负数)select ename,hiredate,(sysdate-hiredate)/30 一,months_between(sysdate,hiredate) 二 from emp;--73个月后select add_months(sysdate,73) from dual;--last_day(月份中的最后一天)select last_day(sysdate) from dual;--next_day(下一个指定的日期:星期几)select next_day(sysdate,'星期二') from dual;--对日期四舍五入('month',看日期在一个月的前一半还是后一半舍入,年也是如此)select round(sysdate,'month'),round(sysdate,'year') from dual;--隐式转换的前提:被转换对象是可以转换的-显式转换SP2-0042: 未知命令 "-显式转换" - 其余行忽略。--显式转换--2015-04-14 15:28:12今天是星期二select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss"今天是"day') from dual;--查询员工薪水:两位小数 千位符 本地货币代码select to_char(sal,'L9,999.99') from emp;--nvl2(a,b,c) 当a=null时候,返回c;否则返回bselect sal*12+nvl2(comm,comm,0) from emp;--nullif(a,b) -- 当a=b时候,返回null;否则返回aselect nullif('abc','abc') 值 from dual;--coalesce 从左到右找到第一个不为null的值select comm,sal,coalesce(comm,sal) "第一个不为null的值" from emp;--条件表达式--涨工资,总裁1000 经理800 其他400set linesize 200select * from emp;--sql99方式select ename,job,sal 涨前, case job when 'PRESIDENT' then sal+1000 when 'MANAGER' then sal+800 else sal+400 end 涨后 from emp;--oracle方式select ename,job,sal 涨前, decode(job,'PRESIDENT',sal+1000, 'MANAGER',sal+800, sal+400) 涨后 from emp; |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 | -- 工资的总额select sum(sal) from emp; --人数select count(*) from emp; --平均工资select sum(sal)/count(*) 一,avg(sal) 二 from emp; --平均奖金(count(*)包含了comm为空的记录)select sum(comm)/count(*) 一,sum(comm)/count(comm) 二,avg(comm) 三 2 from emp;--结果 一 二 三 ---------- ---------- ---------- 157.142857 550 550 select count(*),count(comm) from emp; COUNT(*) COUNT(COMM) ---------- ----------- 14 4 --null 值 5.多行函数会自动滤空,可以嵌套滤空函数来屏蔽他的滤空功能;SQL> select count(*),count(nvl(comm,0)) from emp; --分组数据--group by--求部门的平均工资select deptno,avg(sal) from emp group by deptno; -- 多个列的分组select deptno,job,sum(sal) from emp group by deptno,job order by 1; --求平均工资大于2000的部门select deptno,avg(sal) from emp group by deptno having avg(sal)>2000; --where和having的区别:where后面不能使用多行函数--where和having通用--查询10号部门的平均工资select deptno,avg(sal) from emp group by deptno having deptno=10; /*group by 的增强select deptno,job,sum(sal) from emp group by deptno,job+select deptno,sum(sal) from emp group by deptno+select sum(sal) from emp====select deptno,job,sum(sal) from emp group by rollup(deptno,job)抽象group by rollup(a,b)=group by a,b+group by a+group by null*/--实现报表查询的功能select deptno,job,sum(sal) from emp group by rollup(deptno,job);--结果 DEPTNO JOB SUM(SAL) ---------- --------- ---------- 10 CLERK 1300 10 MANAGER 2450 10 PRESIDENT 5000 10 8750 20 CLERK 1900 20 ANALYST 6000 20 MANAGER 2975 20 10875 30 CLERK 950 30 MANAGER 2850 30 SALESMAN 5600 30 9400 29025 --break on表示取出重复,skip2表示不同列别之间跳过两行break on deptno skip 2select deptno,job,sum(sal) from emp group by rollup(deptno,job);--结果 DEPTNO JOB SUM(SAL) ---------- --------- ---------- 10 CLERK 1300 MANAGER 2450 PRESIDENT 5000 8750 20 CLERK 1900 ANALYST 6000 MANAGER 2975 10875 30 CLERK 950 MANAGER 2850 SALESMAN 5600 9400 29025 --取消去重和跳行设置break on null |
 |  |
 |
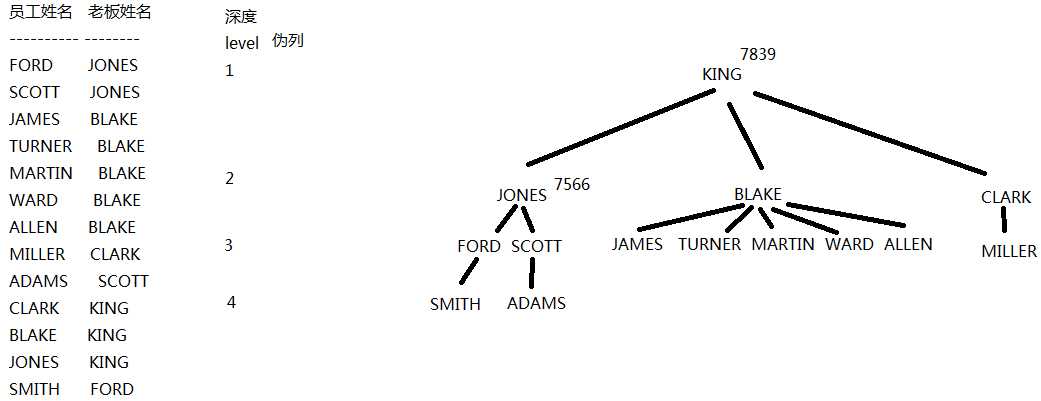
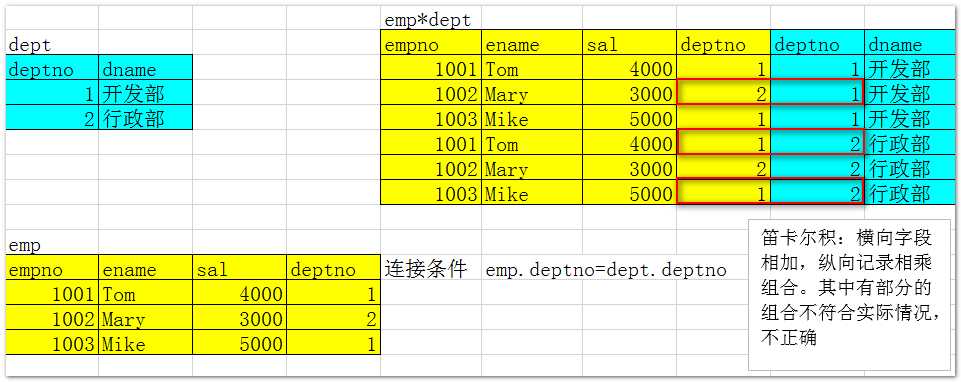
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | --等值连接--查询员工信息:员工号 姓名 月薪 部门名称select e.empno,e.ename,e.sal,d.dname from emp e,dept d where e.deptno=d.deptno;--不等值连接--查询员工信息:员工号 姓名 月薪 工资级别select e.empno,e.ename,e.sal,s.grade from emp e,salgrade s where e.sal between s.losal and s.hisal;--外连接--按部门统计员工人数:部门号 部门名称 人数/*希望: 对于某些不成立的记录,任然希望包含在最后的结果中左外连接:where e.deptno=d.deptno不成立的时候,等号左边的表任然被包含 写法: where e.deptno=d.deptno(+)右外连接:where e.deptno=d.deptno不成立的时候,等号右边的表任然被包含 写法:where e.deptno(+)=d.deptno*/select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数 from emp e,dept d where e.deptno(+)=d.deptno group by d.deptno,d.dname;--自连接(通过别名的方式实现)--查询员工信息:员工的姓名 老板的姓名--自连接:通过表的别名,将同一张表视为多张表select e.ename 员工姓名, b.ename 老板姓名 from emp e,emp b where e.mgr=b.empno;-- 自连接不适合操作大表(笛卡尔积最小为n的平方)--层次查询(适合具有树状层次关系的查询)--根节点没有父节点,连接条件是当前节点的老板id等于上级节点的员工id,伪列必须写出来select level,empno,ename,mgr from emp connect by prior empno=mgr start with mgr is null order by 1;--结果 LEVEL EMPNO ENAME MGR ---------- ---------- ---------- ---------- 1 7839 KING 2 7566 JONES 7839 2 7698 BLAKE 7839 2 7782 CLARK 7839 3 7902 FORD 7566 3 7521 WARD 7698 3 7900 JAMES 7698 3 7934 MILLER 7782 3 7499 ALLEN 7698 3 7788 SCOTT 7566 3 7654 MARTIN 7698 LEVEL EMPNO ENAME MGR ---------- ---------- ---------- ---------- 3 7844 TURNER 7698 4 7876 ADAMS 7788 4 7369 SMITH 7902 |
 |  |
 |  |
 |
 |  |
 |  |
 |  |
(1)尽量使用列名代替*,效率更高
(2)where 解析的顺序: 右 --> 左,因此可以在and语句时将最可能错误的放在右边,在or语句时将最可能正确的放在右边
(3)尽量使用where,因为where在分组前就进行了过滤,效率更高(尤其是数据量大的时候)
(4)理论上,尽量使用多表查询
(5)尽量不要使用集合运算,集合运算效率低
(1)包含null的表达式都为null
(2)null!=null(需要使用is null或者is not null判断是否为空)
(3)如果集合中含有null,不能使用not in;但可以使用in(为什么?因为not in做的是与操作所以就得不到任何结果(null!=null),而in 做的是或操作)
(4)null的排序,默认情况下null最大
(5)多行函数会自动滤空;
1. 分布式数据库
2. 快照snapshot
参考: 27-分布式数据库.avi
标签:
原文地址:http://www.cnblogs.com/duanmublog/p/5470509.html