标签:
1.网站信息抽取:
网站信息抽取的方法有很多,取其中主流的三种:
webBrowser,httpwebrequest/webresponse,webclient
其中我们选取httpwebrequest/webresponse + htmlagilitypack作为实例去测试
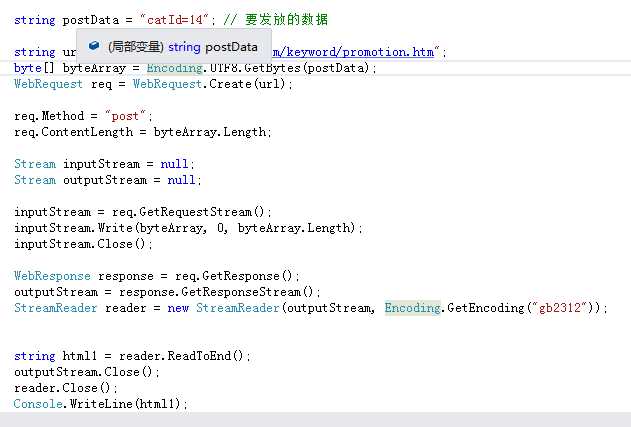
httpwebrequest/webresponse使用post/get方式携带postData向服务器提出请求,从而经过一定处理返回动态网页的全部内容源代码
用上此方法的原因是普通加载动态网站的方式只会返回网页的基本框架代码,很多发送请求后出现的内容无法出现
而htmlagilitypack可以对html代码进行Xpath方式的标签内容索引,得到我们想要的模块的数据从而写入数据库中,
2. 新闻专栏的内置搜索引擎
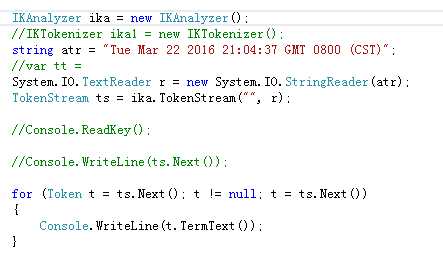
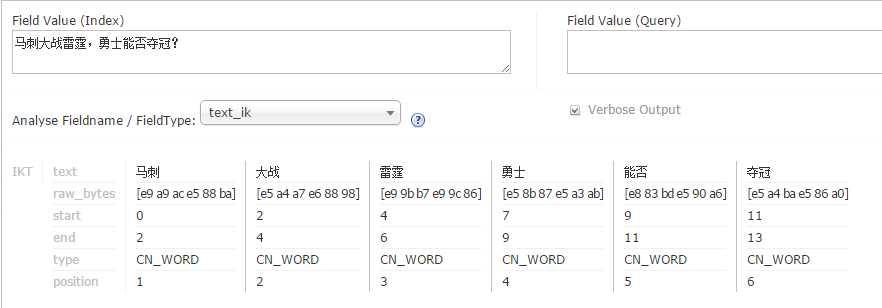
(1)分词器:使用IKanalyser分词代码,对用户的在新闻专栏的搜索内容进行智能分词(下图为内置分词程序结果)
(2)搜索内核(SolrNet+Solr全文检索器配置)
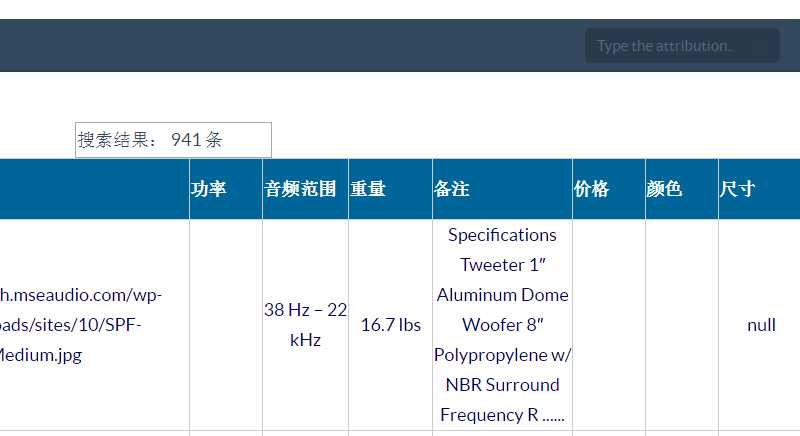
举例使用“Aluminum Dome Woofer”字符串去分词再检索(下图为结果941条中有89条含有分词之后的结果,点击可以查看内容详情)
通过使用while(true)实时检索新闻更新和新闻无更新的时候的sleep()函数去间隔时差抽取数据,可以使得新闻的抽取实现自动化(按照时间索引)
加上大部分当前新闻网站没有设置的内部搜索功能,可以使得浏览新闻更灵活
标签:
原文地址:http://www.cnblogs.com/harpu/p/5473538.html