标签:style blog http 使用 数据 2014 ar 算法
mysql 中的索引一般分为 B树索引,和哈希索引。就是 通过二叉树算法或者哈希算法来提高速度。
首先来看一下B树索引
如果我们有9个 数据分别是 1,2,3,4,5,6,7,8,9 如果我们要在其中找到7 按照普通的查找一个一个查找需要查找7次才能找到。如果使用B数索引就可以
快速找到。
二叉树算法的过程是 将 中间值找出来然后 必中间值大的放在右边,比中间值小的放在左边。然后再细分,我画了一个图可能不太好看。
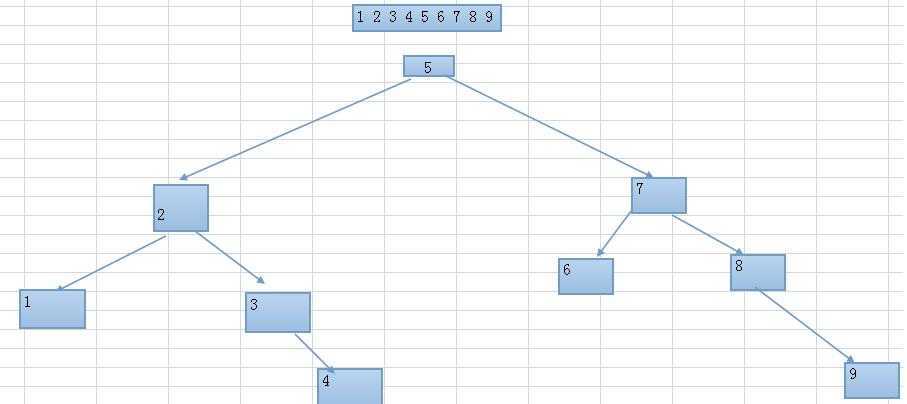
通过上面的图可以看出,找到7 需要2次查找 第一个找到5判断 7比5大,然后去5的右边查找,第二次就查找到7了,这个过程就是B树索引。
还有一种是哈希索引。哈希算法呢,是通过哈希运算将每个值计算出类似序列号的一个东东, 比如说 第一个为 0001 第二个为 0002 第三个为 0009 第四个为 0017,然后 会开辟一个空间 有 0001 到 0017 个内容 将值通过序列号 将值放入空间中,当我们要查找内容时,将查找的内容 通过哈希运算得到序列号,通过序列号理论上就可以一次找到内容。但是哈希排序是有缺点的,1.如果算去来的序列号不是连续的 中间就会有 空出的位置浪费空间,如果算出来的序列号有重复的就要二次处理。
普通索引 (index) 加快查询速度
唯一索引 (unique) 列内容不能重复
主键索引 (primary key)主键不能重复 主键不能重复 一个表只能有一个主键, 但是可以有多个唯一约束
全文索引 (fultext)
alter table 表明 add index/unique/fulltext [索引名](列名); 索引名可以不写默认为列明
主键索引:
alter table 表明 add primary key 列名。 主键索引 索引名为列明(必须)
show index from 表明;
alter table 表明 drop index 索引名。
alter table 表名 drop primary key;
1.一个表的索引太多,会浪费硬盘空间。
2.索引会是插入,修改,删除表内容是速度变慢,因为每操作一次,索引也会更新一次。
3.在移动数据库时,批量导入数据时应该将索引删除,在导入,导入成功后在条件索引,不然导入速度太慢。
4.不怎么 当搜索条件的字段就不要建立索引了,因为没用。
5.内容大都是重复的字段也不要索引了,比如性别的字段,建立索引干嘛呢?
标签:style blog http 使用 数据 2014 ar 算法
原文地址:http://www.cnblogs.com/phpshen/p/3880342.html