标签:blog http java os strong io 数据 for
“Shard” 这个词英文的意思是”碎片”,而作为数据库相关的技术用语,似乎最早见于大型多人在线角色扮演游戏(MMORPG)中。”Sharding” 姑且称之为”分片”。
Sharding 不是一门新技术,而是一个相对简朴的软件理念。如您所知,MySQL 5 之后才有了数据表分区功能,那么在此之前,很多 MySQL 的潜在用户都对 MySQL 的扩展性有所顾虑,而是否具备分区功能就成了衡量一个数据库可扩展性与否的一个关键指标(当然不是唯一指标)。数据库扩展性是一个永恒的话题,MySQL 的推广者经常会被问到:如在单一数据库上处理应用数据捉襟见肘而需要进行分区化之类的处理,是如何办到的呢? 答案是:Sharding。
Sharding 不是一个某个特定数据库软件附属的功能,而是在具体技术细节之上的抽象处理,是水平扩展(Scale Out,亦或横向扩展、向外扩展)的解决方案,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。
说起数据库扩展性,这是个非常大的话题。目前的商业数据都有自己的扩展性解决方案,在过去相对来说比较成熟,但是随着互联网的高速发展,不可避免的 会带来一些计算模式上的演变,这样很多主流商业系统也难免暴露出一些不足之处。比如 Oracle 的 RAC 是采用共享存储机制,对于 I/O 密集型的应用,瓶颈很容易落在存储上,这样的机制决定后续扩容只能是 Scale Up(向上扩展) 类型,对于硬件成本、开发人员的要求、维护成本都相对比较高。
Sharding 基本上是针对开源数据库的扩展性解决方案,很少有听说商业数据库进行 Sharding 的。目前业界的趋势基本上是拥抱 Scale Out,逐渐从 Scale Up 中解放出来。
任何技术都是在合适的场合下能发挥应有的作用。 Sharding 也一样。联机游戏、IM、BSP 都是比较适合 Sharding 的应用场景。其共性是抽象出来的数据对象之间的关联数据很小。比如IM ,每个用户如果抽象成一个数据对象,完全可以独立存储在任何一个地方,数据对象是 Share Nothing 的;再比如 Blog 服务提供商的站点内容,基本为用户生成内容(UGC),完全可以把不同的用户隔离到不同的存储集合,而对用户来说是透明的。
这个 “Share Nothing” 是从数据库集群中借用的概念,举例来说,有些类型的数据粒度之间就不是 “Share Nothing” 的,比如类似交易记录的历史表信息,如果一条记录中既包含卖家信息与买家信息,如果随着时间推移,买、卖家会分别与其它用户继续进行交易,这样不可避免的 两个买卖家的信息会分布到不同的 Sharding DB 上,而这时如果针对买卖家查询,就会跨越更多的 Sharding ,开销就会比较大。
Sharding 并不是数据库扩展方案的银弹,也有其不适合的场景,比如处理事务型的应用就会非常复杂。对于跨不同DB的事务,很难保证完整性,得不偿失。所以,采用什么样的 Sharding 形式,不是生搬硬套的。
有的时候,Sharding 也被近似等同于水平分区(Horizontal Partitioning),网上很多地方也用 水平分区来指代 Sharding,但我个人认为二者之间实际上还是有区别的。的确,Sharding 的思想是从分区的思想而来,但数据库分区基本上是数据对象级别的处理,比如表和索引的分区,每个子数据集上能够有不同的物理存储属性,还是单个数据库范围 内的操作,而 Sharding 是能够跨数据库,甚至跨越物理机器的。(见对比表格)
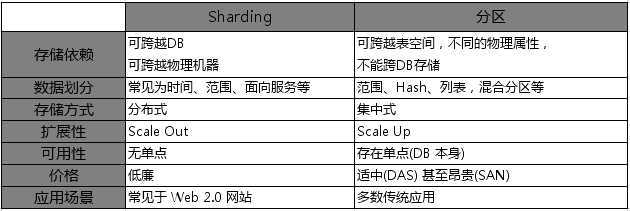
数据 Sharding 的策略与分区表的方式有很多类似的地方,有基于表、ID 范围、数据产生的时间或是SOA 下理念下的基于服务等众多方式可选择。而与传统的表分区方式不同的是,Sharding 策略和业务结合的更为紧密,成功的 Sharding 必须对自己的业务足够熟悉,进行众多可行性分析的基础上进行,”业务逻辑驱动”。
作为风头正劲的 Web 2.0 网站之一的 Digg.com, 虽然用户群庞大,但网站数据库数据并非海量,去年同期主数据大约只有 30GB 的样子,现在应该更大一些,但应该不会出现数量级上增长,数据库软件采用 MySQL 5.x。Digg.com的 IO 压力非常大,而且是读集中的应用(98%的 IO 是读请求)。因为提供的是新闻类服务,这类数据有其自身特点,最近时间段的数据往往是读压力最大的部分。
根据业务特点,Digg.com 根据时间范围对主要的业务数据做 Sharding,把不到 10% 的”热”数据有效隔离开来,同时对这部分数据用以更好的硬件,提供更好的用户体验。而另外 90% 的数据因用户很少访问,所以尽管访问速度稍慢一点,对用户来说,影响也很小。通过 Sharding,Digg 达到了预期效果。
现在 Sharding 相关的软件实现其实不少,基于数据库层、DAO 层、不同语言下也都不乏案例。限于篇幅,作一下简要的介绍。
MySQL Proxy + HSCALE
一套比较有潜力的方案。其中 MySQL Proxy (http://forge.mysql.com/wiki/MySQL_Proxy) 是用 Lua 脚本实现的,介于客户端与服务器端之间,扮演 Proxy 的角色,提供查询分析、失败接管、查询过滤、调整等功能。目前的 0.6 版本还做不到读、写分离。HSCALE 则是针对 MySQL Proxy 插件,也是用 Lua 实现的,对 Sharding 过程简化了许多。需要指出的是,MySQL Proxy 与 HSCALE 各自会带来一定的开销,但这个开销与集中式数据处理方式单条查询的开销还是要小的。
Hibernate Shards
这是 Google 技术团队贡献的项目(http://www.hibernate.org /414.html),该项目是在对 Google 财务系统数据 Sharding 过程中诞生的。因为是在框架层实现的,所以有其独特的特性:标准的 Hibernate 编程模型,会用 Hibernate 就能搞定,技术成本较低;相对弹性的 Sharding 策略以及支持虚拟 Shard 等。
Spock Proxy
这也是在实际需求中产生的一个开源项目。Spock(http://www.spock.com/)是一个人员查找的 Web 2.0 网站。通过对自己的单一 DB 进行有效 Sharding化 而产生了Spock Proxy(http://spockproxy.sourceforge.net/ ) 项目,Spock Proxy 算得上 MySQL Proxy 的一个分支,提供基于范围的 Sharding 机制。Spock 是基于 Rails 的,所以Spock Proxy 也是基于 Rails 构建,关注 RoR 的朋友不应错过这个项目。
HiveDB
上面介绍了 RoR 的实现,HiveDB (http://www.hivedb.org/)则是基于Java 的实现,另外,稍有不同的是,这个项目背后有商业公司支持。
PL/Proxy
前面几个都是针对 MySQL 的 Sharding 方案,PL/Proxy 则是针对 PostgreSQL 的,设计思想类似 Teradata 的 Hash 机制,数据存储对客户端是透明的,客户请求发送到 PL/Proxy 后,由这里分布式存储过程调用,统一分发。 PL/Proxy 的设计初衷就是在这一层充当”数据总线”的职责,所以,当数据吞吐量支撑不住的时候,只需要增加更多的 PL/Proxy 服务器即可。大名鼎鼎的 Skype 用的就是 PL/Proxy 的解决方案。
Pyshards
http://code.google.com/p/pyshards/wiki/Pyshards
这是个基于 Python的解决方案。该工具的设计目标还有个 Re-balancing 在里面,这倒是个比较激进的想法。目前只支持 MySQL 数据库。
Sharding 是一项仍处于高速发展中的”老”技术,随着 Web 2.0 的发展,Sahrding逐渐从比较”虚”的概念变成比较”实”的运用思路,开放源代码软件大潮也给 Sharding 注入新的活力,相信会有越来越多的项目采用 Sharding 技术,也会有更多成熟的 Sharding 方案和数据库附加软件涌现。
你的站点 Sharding 了么?
开源数据库 Sharding 技术 (Share Nothing),布布扣,bubuko.com
开源数据库 Sharding 技术 (Share Nothing)
标签:blog http java os strong io 数据 for
原文地址:http://www.cnblogs.com/kaleidoscope/p/3880521.html