标签:
解 题目 Leetcode 28 Implement strStr()时,查阅和整理了关于KMP算法的资料。
The complexity of the getnext() algorithm is O(k), where k is the length of patterns(模式串/needles)。
next数组的构建的时间复杂度是O(k)
The search portion of the Knuth–Morris–Pratt algorithm has complexity O(n), where n is the length of S and the O is big-O notation.
KMP算法搜索部分的时间复杂度是O(n)
Since the two portions of the algorithm have, respectively, complexities of O(k) and O(n), the complexity of the overall algorithm is O(n + k).
所以KMP算法的时间复杂度是O(n + k).
本部分内容转自:阮一峰-字符串匹配的KMP算法
字符串匹配是计算机的基本任务之一。
举例来说,有一个字符串”BBC ABCDAB ABCDABCDABDE”,我想知道,里面是否包含另一个字符串”ABCDABD”?
许多算法可以完成这个任务,Knuth-Morris-Pratt算法(简称KMP)是最常用的之一。它以三个发明者命名,起头的那个K就是著名科学家Donald Knuth。
下面,我用自己的语言,试图写一篇比较好懂的KMP算法解释。
1.

首先,字符串”BBC ABCDAB ABCDABCDABDE”的第一个字符与搜索词”ABCDABD”的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把”搜索位置”移到已经比较过的位置,重比一遍。
7.
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是”ABCDAB”。KMP算法的想法是,设法利用这个已知信息,不要把”搜索位置”移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.

怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
9.
已知空格与D不匹配时,前面六个字符”ABCDAB”是匹配的。查表可知,最后一个匹配字符B对应的”部分匹配值”为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2(”AB”),对应的”部分匹配值”为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.

因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
14.

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:”前缀”和”后缀”。 “前缀”指除了最后一个字符以外,一个字符串的全部头部组合;”后缀”指除了第一个字符以外,一个字符串的全部尾部组合。
15.
“部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度。以”ABCDABD”为例,
-
16.
“部分匹配”的实质是,有时候,字符串头部和尾部会有重复。比如,”ABCDAB”之中有两个”AB”,那么它的”部分匹配值”就是2(”AB”的长度)。搜索词移动的时候,第一个”AB”向后移动4位(字符串长度-部分匹配值),就可以来到第二个”AB”的位置。
/**
* next[]: the length of the longest possible proper initial segment
* @param needle patterns 模式串
* @return
*/
private int[] getNext(String needle){
int next[] = new int[needle.length()];
next[0] = 0;
int i = 1, j = 0;
while ( i<needle.length() ) {
while( j>0 && needle.charAt(i)!=needle.charAt(j) )
j = next[j-1];
if(needle.charAt(i)==needle.charAt(j))
j++;
next[i] = j;
i++;
}
return next;
} 现在我着重讲解一下while循环所做的工作:
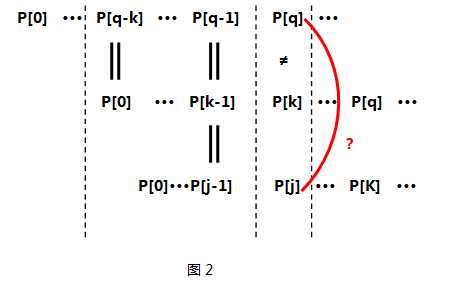
关键如果不等呢???那么我们应该利用已经得到的next[0]···next[k-1]来求P[0]···P[k-1]这个子串中最大相同前后缀,可能有同学要问了——为什么要求P[0]···P[k-1]的最大相同前后缀呢???是啊!为什么呢?
原因在于P[k]已经和P[q]失配了,而且P[q-k] ··· P[q-1]又与P[0]
···P[k-1]相同,看来P[0]···P[k-1]这么长的子串是用不了了,那么我要找个同样也是P[0]打头、P[k-1]结尾的子串即P[0]···Pj-1,看看它的下一项P[j]是否能和P[q]匹配。如图2所示

附代码-java:
private int KMP(String haystack, String needle){
int next[] = getNext(needle);
int i=0, j=0;
while( i<haystack.length() && j<needle.length() ){
if( j==-1 || haystack.charAt(i) == needle.charAt(j) ){
i++;
j++;
}
else{
if(j<1)
j = -1;
else
j = next[j-1];
}
}
if(j==needle.length()){
return i-needle.length();
}
return -1;
}
/**
* next[]: the length of the longest possible proper initial segment
* @param needle patterns 模式串
* @return
*/
private int[] getNext(String needle){
int next[] = new int[needle.length()];
next[0] = 0;
int i = 1, j = 0;
while ( i<needle.length() ) {
while( j>0 && needle.charAt(i)!=needle.charAt(j) )
j = next[j-1];
if(needle.charAt(i)==needle.charAt(j))
j++;
next[i] = j;
i++;
}
return next;
}标签:
原文地址:http://blog.csdn.net/muyu709287760/article/details/51377930