标签:
一、架构方案如下图:
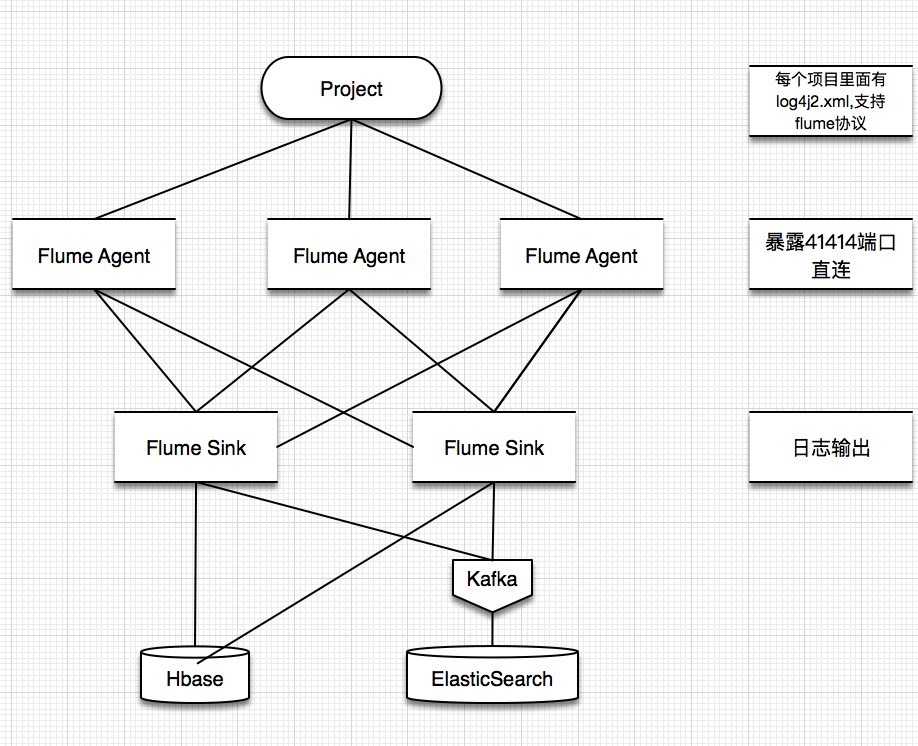
二、各个组件的安装方案如下:
1)、zookeeper+kafka
http://www.cnblogs.com/super-d2/p/4534323.html
2)hbase
http://www.cnblogs.com/super-d2/p/4755932.html
3)flume安装:
Flume 运行系统要求1.6以上的Java 运行环境,从oracle网站下载JDK 安装包,解压安装:
$tar zxvf jdk-8u65-linux-x64.tar.gz $mv jdk1.8.0_65 java 设置Java 环境变量:
JAVA_HOME=/opt/java PATH=$PATH:$JAVA_HOME/bin export JAVA_HOME PATH 从官网下载Flume 二进制安装包,解压安装:
tar zxvf apache-flume-1.6.0-bin.tar.gz mv apache-flume-1.6.0-bin flume cd flume source 使用 necat 类型,sink 采用 file_roll 类型, 从监听端口获取数据,保存到本地文件。 拷贝配置模板:
cp conf/flume-conf.properties.template conf/flume-conf.properties 编辑配置如下:
# The configuration file needs to define the sources, # the channels and the sinks. # Sources, channels and sinks are defined per agent, # in this case called ‘agent‘ agent.sources = r1 agent.channels = c1 agent.sinks = s1 # For each one of the sources, the type is defined agent.sources.r1.type = netcat agent.sources.r1.bind = localhost agent.sources.r1.port = 8888 # The channel can be defined as follows. agent.sources.r1.channels = c1 # Each sink‘s type must be defined agent.sinks.s1.type = file_roll agent.sinks.s1.sink.directory = /tmp/log/flume #Specify the channel the sink should use agent.sinks.s1.channel = c1 # Each channel‘s type is defined. agent.channels.c1.type = memory # Other config values specific to each type of channel(sink or source) # can be defined as well # In this case, it specifies the capacity of the memory channel agent.channels.c1.capacity = 100 1.建立输出目录
mkdir -p /tmp/log/flume 2.启动服务
bin/flume-ng agent --conf conf -f conf/flume-conf.properties -n agent& 运行日志位于logs目录,或者启动时添加-Dflume.root.logger=INFO,console 选项前台启动,输出打印日志,查看具体运行日志,服务异常时查原因。
3.发送数据
telnet localhost 8888输入hello world! hello Flume!
4.查看数据文件 查看 /tmp/log/flume 目录文件:
cat /tmp/log/flume/1447671188760-2 hello world! hello Flume! Flume 可以灵活地与Kafka 集成,Flume侧重数据收集,Kafka侧重数据分发。 Flume可配置source为Kafka,也可配置sink 为Kafka。 配置sink为kafka例子如下
agent.sinks.s1.type = org.apache.flume.sink.kafka.KafkaSink agent.sinks.s1.topic = mytopic agent.sinks.s1.brokerList = localhost:9092 agent.sinks.s1.requiredAcks = 1 agent.sinks.s1.batchSize = 20 agent.sinks.s1.channel = c1 Flume 收集的数据经由Kafka分发到其它大数据平台进一步处理。
对应于我们的架构方案:
flume的配置如下:
# Flume test file
# Listens via Avro RPC on port 41414 and dumps data received to the log
agent.channels = ch-1
agent.sources = src-1
agent.sinks = sink-1
agent.channels.ch-1.type = memory
agent.channels.ch-1.capacity = 10000000
agent.channels.ch-1.transactionCapacity = 1000
agent.sources.src-1.type = avro
agent.sources.src-1.channels = ch-1
agent.sources.src-1.bind = 0.0.0.0
agent.sources.src-1.port = 41414
agent.sinks.sink-1.type = logger
agent.sinks.sink-1.channel = ch-1
agent.sinks.sink-1.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.sink-1.topic = avro_topic
agent.sinks.sink-1.brokerList = ip:9092
agent.sinks.sink-1.requiredAcks = 1
agent.sinks.sink-1.batchSize = 20
agent.sinks.sink-1.channel = ch-1
agent.sinks.sink-1.channel = ch-1
agent.sinks.sink-1.type = hbase
agent.sinks.sink-1.table = logs
agent.sinks.sink-1.batchSize = 100
agent.sinks.sink-1.columnFamily = flume
agent.sinks.sink-1.znodeParent = /hbase
agent.sinks.sink-1.zookeeperQuorum = ip:2181
agent.sinks.sink-1.serializer = org.apache.flume.sink.hbase.RegexHbaseEventSerializer
备注flume到hbase要把 相关的包拷贝到flume下面
demo:
https://github.com/super-d2/flume-log4j-example
参考:
https://mos.meituan.com/library/41/how-to-install-flume-on-centos7/
标签:
原文地址:http://www.cnblogs.com/super-d2/p/5486739.html