标签:
一、python介绍
python 是Guido van Rossum创建与1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言,是ABC编程语言的继承。第一个公开发行版发行于1991年。python 是一种面向对象、直译式计算机程序设计语言,Python语法简捷而清晰,具有丰富和强大的类库。
python 特性
Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
Python 是交互式语言: 这意味着,您可以在一个Python提示符,直接互动执行写你的程序。
Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
python 排名
前10名编程语言的走势图:

编程语言排行榜 TOP 20 榜单:
由此可见,Python整体呈上升趋势,反映出Python应用越来越广泛并且也逐渐得到业内的认可!!!
python 解释器的种类
当我们从Python官方网站下载并安装好Python 后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
1、__future__模块
python3的一些特性可以同过future模块来导入,例如想要在python2.x中导入python3.x的print函数
from __future__ import print_function print(‘导入陈功。‘)
| feature | optional in | mandatory in | effect |
|---|---|---|---|
| nested_scopes | 2.1.0b1 | 2.2 | PEP 227: Statically Nested Scopes |
| generators | 2.2.0a1 | 2.3 | PEP 255: Simple Generators |
| division | 2.2.0a2 | 3.0 | PEP 238: Changing the Division Operator |
| absolute_import | 2.5.0a1 | 3.0 | PEP 328: Imports: Multi-Line and Absolute/Relative |
| with_statement | 2.5.0a1 | 2.6 | PEP 343: The “with” Statement |
| print_function | 2.6.0a2 | 3.0 | PEP 3105: Make print a function |
| unicode_literals | 2.6.0a2 | 3.0 | PEP 3112: Bytes literals in Python 3000 |
2、print函数
在python3.x 中 print 不再是语句,而是函数,书写方式由 print 改为 print()
python 2.x print ‘Hello World‘
python 3.x print(‘Hello World‘)
3、整除,原来1/2(两个整数相除)结果是0,现在是0.5了
python 2.x >>>1/2 0
python 3.x
>>> 1/2
0.5
4、python 3.x中没有旧式类,只有新式类
在Python 3中,没有旧式类,只有新式类,也就是说不用再像这样 class Foobar(object): pass 显式地子类化object,声明的都是新式类。
5、xrange重命名为range
python 3.x 中不存在 xrange 函数,而range 函数返回的就是迭代器对象,同时更改的还有一系列内置函数及方法, 都返回迭代器对象, 而不是列表或者 元组, 比如 filter, map, dict.items 等。
6、!=取代 < >
python 3.x中不再存在 <>符号,判断不等于的话,使用 !=号
7、long重命名为int
python3 废弃了 long 长整型表示方法,统一为 int , 支持高精度整数运算
8、except Exception, e变成except (Exception) as e
注意该写法,python 3.x中再使用之前的写法会报错
9、next()函数 和.next()方法
在python3.x中只有 next() 函数,废弃了.next()方法
10、字符串格式化 由原先的 % ,在py3.x中提倡是用 format函数
11、python3.x中某些类库做了调整
例如python 2.x中 urllib 和 urllib2 两个库 在python 3.x中合并成了一个库 urllib
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
全世界有上百种语言,日本不认可中文的编码,日本把日文编到Shift_JIS里,韩国也不认可中文的编码,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
Unicode就诞生了。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode 最常用的是用两个字节表示一个字符(部分偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
但是,如果都采用Unicode的编码的话,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,为了节约空间,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
到这里,编码的历史大概介绍了一遍,总结一下,在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
下图是编码存储与读取转换的过程
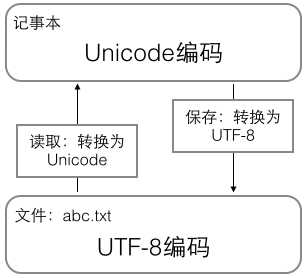
python2.x版本原生支持ASCII编码,后来添加了对Unicode的支持,以Unicode表示的字符串用u‘...‘表示。
python代码中包含中文的时候,在保存代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python # -*- coding: utf-8 -*-
第一行适用于类Unix系统,告诉系统使用什么解释器
第二行声明代码编码类型
变量的概念基本上和初中代数的方程变量是一致的,只是在计算机程序中,变量不仅可以是数字,还可以是任意数据类型。
变量在程序中就是用一个变量名表示了,变量名必须是大小写英文、数字和_的组合,且不能用数字开头。
在python中给变量赋值使用 = 号,python是弱类型的动态编程语言,在给变量赋值之前不需要声明变量的类型,同一个变量可以反复复制,而且可以是不同的类型。
例如:
>>> a = ‘abc‘ >>> a_ = 123 >>> a_123 = True
python把一个值赋值给变量,等于在内存中开辟了一块地址存储该值。
>>> a = ‘QWE’
执行上边的语句时,等于干了两件事情:
1、在内存中创建一个‘QWE’的字符串
2、在内存中创建一个名字为a的变量,并将他指向‘QWE’
>>> b = a
>>> a = ‘ASD‘
>>> print (a, ‘‘, b)
ASD QWE
当将变量a复制给变量b的时候,实际上是将变量b指向变量a的所指向的数据。
当再次给变量a赋值时,a指向了另一个变量空间。
python3.x中使用 input函数获取用户的输入,input的函数把用户的一切输入都当作是字符串。
#!/usr/bin/env python #_*_coding:utf-8_*_ user_input = input(‘input your name:‘ ) print (user_input)
输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法
#!/usr/bin/env python # -*- coding: utf-8 -*- import getpass # 将用户输入的内容赋值给 name 变量 pwd = getpass.getpass("请输入密码:") # 打印输入的内容 print(pwd)
“一切数据是对象,一切命名是引用” ,这是python数据类型的核心。
python有以下的数据类型
1、字符串
2、布尔类型
3、整数
4、浮点数
5、复数型
python使用单引号或者双引号表示字符串,两种表示功能方式相同
s = ‘test‘ s = "test"
还可使用‘‘‘三引号表示长段的字符串
s = ‘‘‘ this a test with a lot pf words which show the long string in Python ‘‘‘
布尔型
布尔型 其实是整型的子类型,布尔型数据只有两个取值:True和False,分别对应整型的1和0。
每一个Python对象都天生具有布尔值(True或False),进而可用于布尔测试(如用在if、while中)。
以下对象的布尔值都是False:
__nonzero__() 或 __len__(),并且这些方法返回0或False整型
Python语言的整型相当于C语言中的long型,在32位机器上,整型的位宽为32位,取值范围为-231~231-1,即-2147483648~2147483647;在64位系统上,整型的位宽通常为64位,取值范围为-263~263-1,即-9223372036854775808~9223372036854775807。
Python中的整数不仅可以用十进制表示,也可以用八进制和十六进制表示。当用八进制表示整数时,数值前面要加上一个前缀“0”;当用十六进制表示整数时,数字前面要加上前缀0X或0x。
长整型
在python 2.x中还存在长整型,跟C语言不同,Python的长整型没有指定位宽,也就是说Python没有限制长整型数值的大小,但是实际上由于机器内存有限,所以我们使用的长整型数值不可能无限大。
在使用过程中,我们如何区分长整型和整型数值呢?通常的做法是在数字尾部加上一个大写字母L或小写字母l以表示该整数是长整型的。
浮点型
浮点型用来处理实数,即带有小数的数字。Python的浮点型相当于C语言的双精度浮点型。实数有两种表示形式,一种是十进制数形式,它由数字和小数点组成,并且这里的小数点是不可或缺的,如1.23,123.0,0.0等;另一种是指数形式,比如789e3或789E3表示的都是789×103,字母e(或E)之前必须有数字,字母e(或E)之后可以有正负号,表示指数的符号,如果没有则表示正号;此外,指数必须为整数。
复数类型
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。注意,虚数部分的字母j大小写都可以,如5.6+3.1j,5.6+3.1J是等价的。
对于复数类型变量n,我们还可以用n.real来提取其实数部分,用n.imag来提取其虚数部分,用n.conjugate返回复数n的共轭复数。
条件判断
根据年龄打印不同的内容,在Python程序中,用if语句实现:
1 age = 20 2 if age >= 18: 3 print(‘your age is‘, age) 4 print(‘adult‘)
根据Python的缩进规则,如果if语句判断是True,就把缩进的两行print语句执行了,否则,什么也不做。
也可以给if添加一个else语句,意思是,如果if判断是False,不要执行if的内容,去把else执行了:
age = 3 if age >= 18: print(‘your age is‘, age) print(‘adult‘) else: print(‘your age is‘, age) print(‘teenager‘)
还可以用elif做更细致的判断:
age = 3 if age >= 18: print(‘adult‘) elif age >= 6: print(‘teenager‘) else: print(‘kid‘)
elif是else if的缩写,完全可以有多个elif,所以if语句的完整形式就是:
if <条件判断1>: <执行1> elif <条件判断2>: <执行2> elif <条件判断3>: <执行3> else: <执行4>
循环
for 循环
循环10次
for i in range(10): print("loop:", i )
输出
loop: 0 loop: 1 loop: 2 loop: 3 loop: 4 loop: 5 loop: 6 loop: 7 loop: 8 loop: 9
改变下条件,遇到小于5的循环次数就不走了,直接跳入下一次循环
for i in range(10): if i<5: continue #不往下走了,直接进入下一次loop print("loop:", i )
再次改变下条件,但是遇到大于5的循环次数就不走了,直接退出
for i in range(10): if i>5: break #不往下走了,直接跳出整个loop print("loop:", i )
name = raw_input("Please input your name:") age = int(raw_input("Please input your age:")) provice = raw_input("Please input your provice:") company = raw_input("Please input your company:") msg = ‘‘‘ Infomation of user %s ------------------------- name : %s age : %2f provice : %s company : %s -----------End----------- ‘‘‘ % (name,name,age,provice,company) print msg
Python的强大之处在于他有非常丰富和强大的标准库和第三方库
sys
import sys print(sys.argv) #输出 $ python test.py helo world [‘test.py‘, ‘helo‘, ‘world‘] #把执行脚本时传递的参数获取到了
os
import os os.system("df -h")
结合一下
import os,sys os.system(‘‘.join(sys.argv[1:])) #把用户的输入的参数当作一条命令交给os.system来执行
自己写个模块
自己编写模块之后将模块文件放到 /usr/local/lib/pythonx.x/site-packages/ 目录下
下面添加个自动不全模块

#!/usr/bin/env python # python startup file import sys import readline import rlcompleter import atexit import os # tab completion readline.parse_and_bind(‘tab: complete‘) # history file histfile = os.path.join(os.environ[‘HOME‘], ‘.pythonhistory‘) try: readline.read_history_file(histfile) except IOError: pass atexit.register(readline.write_history_file, histfile) del os, histfile, readline, rlcompleter for Linux
# python startup file for window import sys import readline import rlcompleter import atexit import os # tab completion readline.parse_and_bind(‘tab: complete‘) del os,readline, rlcompleter
import sys import readline import rlcompleter if sys.platform == ‘darwin‘ and sys.version_info[0] == 2: readline.parse_and_bind("bind ^I rl_complete") else: readline.parse_and_bind("tab: complete") # linux and python3 on mac
注:保存内容为tab.py,使用import tab命令引用该模块。该文件存放的位置就是 /usr/local/lib/pythonx.x/site-packages/
标签:
原文地址:http://www.cnblogs.com/9527chu/p/5487886.html
