标签:
1、获取数据
从 QQ 消息管理器中导出消息记录,保存的文本类型选择 txt 文件。这里获取的是某群从 2016-04-18 到 2016-05-07 期间的聊天记录,记录样本如下所示。
消息记录(此消息记录为文本格式,不支持重新导入) ================================================================ 消息分组:我的QQ群 ================================================================ 消息对象:QQGroup ================================================================ 2016-04-18 20:04:00 谁来弄死我(1122334455) ip 主机名 2016-04-18 20:04:20 我来弄死谁(66554432) 这个我配了 2016-04-18 20:04:29 我来弄死谁(66554432) hadoop集群是正常的 2016-04-18 20:05:07 谁来弄死我(1122334455) 自己找吧 2016-04-18 20:05:20 我来弄死谁(66554432) spark集群运行作业的时候就抱这错了 2016-04-18 20:05:29 我来弄死谁(66554432) 我都找了好几天了
2、数据预处理
打开 R 软件,先通过 File—>Change dir 切换到聊天文件所在目录。
引入包:
library(stringr)
library(plyr)
library(lubridate)
library(ggplot2)
library(reshape2)
library(igraph)
没有的包要通过命令 install.packages(”扩展包名”) 安装。
读取聊天记录文件到内存:
qqsrcdata<-readLines("QQGroup.txt",encoding="UTF-8")
这里我们不关心聊天内容,只看时间和发言人,所以,我们把类似 “2016-04-18 20:04:20 我来弄死谁(66554432)” 这样的内容提取出来。这里要用到正则表达式,对此不懂的可参考 正则表达式30分钟入门教程。对 R 语言的 grep、sub、gregexpr 等字符串处理函数不熟的,网上搜一下,资料多的是。
srcdata<-qqsrcdata[grep("^\\d{4}-\\d{2}-\\d{2} \\d+:\\d{2}:\\d{2} .+$",qqsrcdata)]
看看 srcdata 内容,就已经全是发言时间和发言人信息了,没有其它闲杂数据。
然后再从 srcdata 中提取发言时间和发言人信息,分别存到列表 data 的 time 和 id 中。对发言人信息的提取很简单:
data={} # 创建一个空的 list
data$id<-sub("\\d{4}-\\d{2}-\\d{2} \\d+:\\d{2}:\\d{2} ", "", srcdata)
对发言时间的提取要稍麻烦些,因为时间字符串的长度不一样,有些是 18 位,如 “2016-04-18 7:36:32”,有些是 19 位,如 “2016-04-18 19:24:01”,所以,在提取时间时,需先用 gregexpr 确定时间字符串的起始和结束位置,然后再用 substring 提取出相应的时间,注意 substring 和 sub 是不同的函数。
getcontent <- function(s,g){ substring(s,g,g+attr(g,‘match.length‘)-1) # 读取 s 中的数据 } gg<-gregexpr("\\d{4}-\\d{2}-\\d{2} \\d+:\\d{2}:\\d{2}",srcdata,perl=TRUE) for(j in 1:length(gg)) { data$time[j]<-getcontent(srcdata[j],gg[[j]]) }
现在时间和发言人信息都读到 data 的 time 和 id 中了,可以确认下提取内容:data、data$id、data$time。
还没完,时间还是字符串,还需要继续处理:
# 数据整理 # 将字符串中的日期和时间划分为不同变量 temp1 <- str_split(data$time,‘ ‘) result1 <- ldply(temp1,.fun=NULL) names(result1) <- c(‘date‘,‘clock‘) #分离年月日 temp2 <- str_split(result1$date,‘-‘) result2 <- ldply(temp2,.fun=NULL) names(result2) <- c(‘year‘,‘month‘,‘day‘) # 分离小时分钟 temp3 <- str_split(result1$clock,‘:‘) result3 <- ldply(temp3,.fun=NULL) names(result3) <- c(‘hour‘,‘minutes‘,‘second‘) # 合并数据 newdata <- cbind(data,result1,result2,result3) # 转换日期为时间格式 newdata$date <- ymd(newdata$date) # 提取星期数据 newdata$wday <- wday(newdata$date) # 转换数据格式 newdata$month <- ordered(as.numeric(newdata$month) ) newdata$year <- ordered(newdata$year) newdata$day <- ordered(as.numeric(newdata$day)) newdata$hour <- ordered(as.numeric(newdata$hour)) newdata$wday <- ordered(newdata$wday)
至此,数据预处理完成,时间和发言人数据都已合适地存到 newdata 中,可以开始任性地分析了~
3、数据分析
先来看一星期中每天合计的聊天记录次数,可以看到该 QQ 群的聊天兴致随星期的分布。
qplot(wday,data=newdata,geom=‘bar‘)
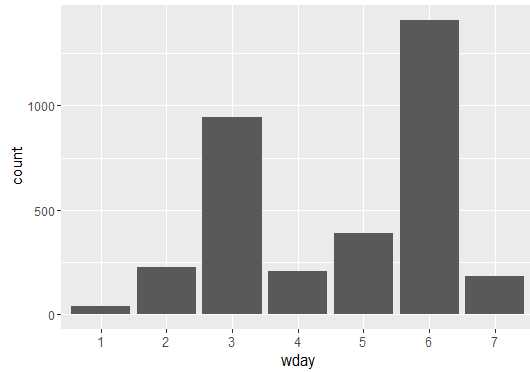
周三是工作日,还这么活跃,周六话最多,周日估计出去玩了,周一专心上班。
再来看看聊天兴致在一天中的分布。
qplot(hour,data=newdata,geom=‘bar‘)
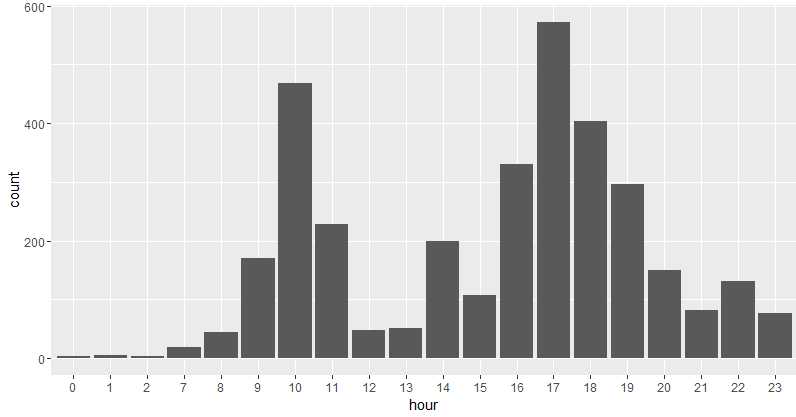
这群一天中聊得最嗨的是上午 10 点和下午 17 点,形成两个高峰。
参考资料:
[1] 正则表达式30分钟入门教程
[2] http://blog.csdn.net/stdcoutzyx/article/details/37568225
标签:
原文地址:http://www.cnblogs.com/NaughtyBaby/p/5497714.html