标签:
这周写的有点晚了,培训的作业写得头都大了,原来以为写2天就能写完,结果自己加了点功能居然搞了4天。。。
第二天的培训内容基本在第一天的博客里就有了,提前看了下视频做了点记录,就把第二天的培训内容要点写一些吧,所以这周的笔记应该不是很多。废话不说了,开整。
上周要点基本就讲了下列表、字典和运算符之类的。
本周亮点内容:
常量
常量顾名思义就是不会频繁变动的变量,为了便于别的程序员读懂你的代码,最好将常量定义以全部大写的方式来呈现,也可说业内潜规则吧,类似于变量的驼峰式和下划线命名规则。比如:
CHINA=‘中国‘
列表
列表中,字符串用引号表示,不带引号的为变量,print列表时,列表会将变量自动转化为变量对应的字符串:
name=‘ccorz‘ l1=[1,‘orz‘,name,‘python‘] print(l1)
结果:
[1, ‘orz‘, ‘ccorz‘, ‘python‘]
列表删除
除了list.remove(),还可用del ,del同样适用于变量,列表,字典等等,也可删多个:
name=‘ccorz‘ del name #可删变量 l1=[1,‘orz‘,name,‘python‘] print(l1)
结果:
Traceback (most recent call last): File "C:/Users/Shane/PycharmProjects/test/111111.py", line 71, in <module> l1=[1,‘orz‘,name,‘python‘] NameError: name ‘name‘ is not defined
同样删除列表中的元素:
name=‘ccorz‘ l1=[1,‘orz‘,name,‘python‘] print(l1) del l1[0] #删除单个元素 print(l1) del l1[0:2] #删除多个 print(l1)
结果:
[1, ‘orz‘, ‘ccorz‘, ‘python‘] [‘orz‘, ‘ccorz‘, ‘python‘] [‘python‘]
列表删除还有pop(),其中remove为删除元素,pop()为删除列表的索引:
name=‘ccorz‘ l1=[1,‘orz‘,name,‘python‘] print(l1) print(l1[:]) #list[:} 取列表中的所有元素 l1.pop() #pop()无指定的话,删除最后一个元素,同pop(-1) print(l1) l1.pop(1) print(l1) l1.remove(‘ccorz‘) print(l1)
结果:
[1, ‘orz‘, ‘ccorz‘, ‘python‘] [1, ‘orz‘, ‘ccorz‘, ‘python‘] [1, ‘orz‘, ‘ccorz‘] [1, ‘ccorz‘] [1]
pop比如:
name=‘ccorz‘ l1=[1,‘orz‘,name,‘python‘] l1.append(‘haha‘) print(l1) l1.insert(1,‘goo‘) print(l1)
结果:
[1, ‘orz‘, ‘ccorz‘, ‘python‘, ‘haha‘] [1, ‘goo‘, ‘orz‘, ‘ccorz‘, ‘python‘, ‘haha‘] [1, ‘goo‘, ‘orz‘, ‘ccorz‘, ‘python‘]
列表排序
sort()可将列表排序,但在py3中,数字和字符串同时出现在列表中时,是无法排序的
li=[1, ‘goo‘, ‘orz‘, ‘ccorz‘, ‘python‘, ‘haha‘,2,3,6] li.sort()
File "C:/Users/Shane/PycharmProjects/test/111111.py", line 79, in <module> li.sort() TypeError: unorderable types: str() < int()
其实sorted,http://blog.chinaunix.net/uid-20775448-id-4222915.html 这有具体的说明,慢慢研究
字符串的合并
都说是万恶的加号‘+’,能不用就不用,那就用join,对象可谓字符串,列表等等
a=‘x‘.join(‘abc‘) #前面是字符串连接字符或者符号,后面是字符串 print(a)
li=[‘goo‘, ‘orz‘, ‘ccorz‘, ‘python‘, ‘haha‘]
print(‘x‘.join(li))
axbxc
gooxorzxccorzxpythonxhaha
字典
dict.items() 数据量较大时比较耗时,故不推荐使用,需要注意的是,items() keys() values() 返回值都是一个列表
d1={‘name‘:‘ccorz‘,‘age‘:18,‘company‘:‘it‘}
d2=d1.items()
print(d1)
print(d2)
结果:
{‘company‘: ‘it‘, ‘age‘: 18, ‘name‘: ‘ccorz‘}
dict_items([(‘company‘, ‘it‘), (‘age‘, 18), (‘name‘, ‘ccorz‘)])
dic.setdefault(‘asdfsad’,’test‘) 如果没有key,设置一个对应value,如果存在,返回其key的值
d1={‘name‘:‘ccorz‘,‘age‘:18,‘company‘:‘it‘}
res=d1.setdefault(‘123‘)
print(res)
res2=d1.setdefault(‘xxxx‘,‘1111‘)
print(res2)
print(d1)
res3=d1.setdefault(‘name‘,‘shane‘)
print(res3)
结果:
None 1111 {‘company‘: ‘it‘, ‘xxxx‘: ‘1111‘, ‘age‘: 18, ‘name‘: ‘ccorz‘, ‘123‘: None} ccorz
dic.fromkeys([1,2,3,4],’test’) 只是借用字典这个导入,对原来字典并没什么卵用
d1={‘name‘:‘ccorz‘,‘age‘:18,‘company‘:‘it‘}
res=d1.fromkeys((1,2,3,1),‘test‘)
print(res) #只是借用字典的功能而已
print(d1) #结果并没改变原来的字典
结果:
{1: ‘test‘, 2: ‘test‘, 3: ‘test‘}
{‘name‘: ‘ccorz‘, ‘age‘: 18, ‘company‘: ‘it‘}
dic.pop(’testkey’) 删除key以及对应的值 等同于del dic(’testkey’)
d1={‘name‘:‘ccorz‘,‘age‘:18,‘company‘:‘it‘}
d1.pop(‘name‘)
print(d1)
结果:
{‘company‘: ‘it‘, ‘age‘: 18}
退出操作时,可用exit(‘bye!baby....‘)直接显示回显
exit(‘bye.11.....‘)
bye.11.....
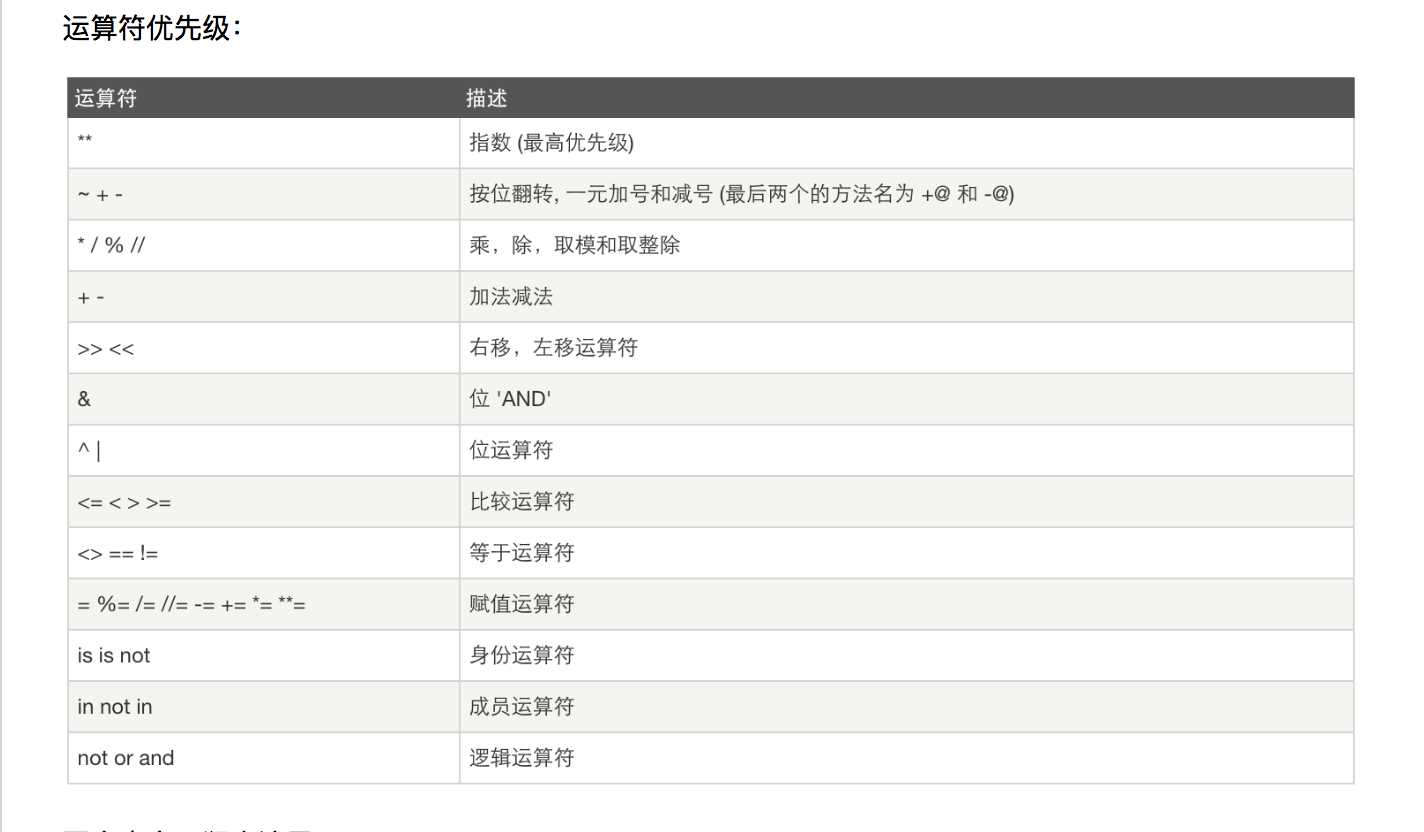
运算符优先级别:基本和数学算法类似,再不济我就加圆括号可好。。。。。。。,不抄了,直接扣图。。。。
最后有一个比较有趣的,记录下来,以后判断类型要用type,不能直接用变量或者字符串直接判断
a=[1,2,3,5,] print(a is list) print(type(a) is list) print(‘333‘ is str) print(type(‘333‘) is str)
注意看结果:
False
True
False
True
基本就这些了,打完,收工。。。。。
标签:
原文地址:http://www.cnblogs.com/ccorz/p/5510695.html