标签:
The results look OK, but how do you know that you aren’t missing something. Would
a more sophisticated model with more variables work even better? If you add enough
variables to a model, you can fit almost anything. However, you generally reach a
point of diminishing returns; at some point additional complexity starts reducing the
model’s quality. You need an Occam’s razor to find a balance between accuracy and
complexity. That “razor” is an integral part of Bayesian inference, which includes a
robust way to assess model quality called evidence that you can use to pick the best
model.
如果你加了足够的变量的一个模型,你可以适合几乎任何。然而,你一般都会到达
收益递减点;在某些点上附加的复杂性开始减少模型质量。你需要一个奥卡姆的剃刀,以找到一个平衡之间的精度和复杂性。“剃刀”是贝叶斯推理的一个组成部分,它包括可靠的方法来评估模型的质量,称为证据,你可以用以挑选最好的模型
本项目大大简化了概率规划问题,
A modelling API,简化了构建概率模型。即使是复杂的模型也只用几行代码来表示。
An inference engine,推理机,结合模型与你的观察,和处理指定变量的可能值,概率的复杂的数学
三个例子:
选择会议文件、多玩家游戏中的等级玩家(浓乳一些挑战需要等级差不多的玩家)、预测点击率(一些广告公司根据用户习惯来预测点记录表)
概率规划如何工作,用下面侦探小说来说明:
你回到你的村子和你的邻居在一个晚上的牌,只发现你的客人已被残忍地杀害了。你必须发现
罪犯。最初,你知道:
?有两个可能的罪魁祸首:管家和厨师。
?有三种可能的谋杀武器:一把屠刀,一把手枪,和一个壁炉铁棒。
起初,罪犯和杀人的武器是未知的。然而,概率推理和观察可以帮助确定可能的罪犯,并在过程中提供一个介绍概率规划的基础知识。
犯罪嫌疑人和杀人武器:是随机变量
需要一个变量来代表这个嫌疑人,值是有罪或无罪。无法确定到底是哪个值,除非嫌疑人坦白。然而可以预测每个嫌疑人是罪犯的概率。
随机变量有一个值域,bool是true,false double是一个范围如[0, 1] 或[-∞, ∞].每个随机变量都有一个联合概率分布,来指定每个可能值的概率。如a bool random variable could have a 70% probability of being true, and a 30% probability of being false
随机变量罪犯有两个可能的值:管家和厨师
随机变量武器有3个可能值:一把屠刀,一把手枪,和一个壁炉铁棒
概率分布:
罪犯和武器都是离散分布,因为实际值必定在这个分布内,因此每个值得概率总和为100%。
开始:先验分布
一个事先定义的变量在你之前的理解,已经做了观察。
对罪犯:管家是一个正直的人,为这个家庭忠诚地服务了多年。厨师受雇最近,有一个不光彩的过去的谣言。
从这个信息,你估计罪犯先验是: 管家= 20% 厨师= 80%。
调查:观察和后验分布
先验是一个有用的起点,但你可以提高你的理解,如果你在模型中观察一个或多个随机变量的实际值,他们不再是不确定的值。这让你能更好的估计其他变量的分布。
例如,你知道管家更可能使用了手枪,和厨师更容易使用刀或铁棒。你收到后验尸官的报告,你可以推断出一个新的罪魁祸首的分布,
如果杀人的武器是手枪,管家概率增加和厨师概率减少。观察并不能取代先验,它仍然是有效的,但可以用附加的信息来修正prior belief,以便如实反映所有的有效数据。新的分布称为后验分布 posterior distribution,或只是"posterior"。事实上,先验分布和后延分布的区别有时是模糊的。一个更一般的和有用的方法来看待先验和后验概率是:
prior 代表观察之前你对系统的理解。
posterior代表你做过观察之后,对系统的理解。
假如你拿出一个额外的观察:当谋杀发生后,一个新的验尸报告给出了一个估计。在收到第2份报告前,你的理解是阅读第1份报告后的posterior,在逻辑上是prior 对于新的报告(第二次观察),这种类型的推理是增量的性质,被称为在线学习。或者你回到原来的prior belief,并重新考虑所有的证据从零开始。
你的证据越多,你的prior belief 越不重要。确凿的证据应该推翻任何先前的prior belief ,但是如果你没有足够的证据来工作,prior belief 就更重要了。
量化的问题:条件的,联合的,和边缘分布
Quantify the Problem: Conditional, Joint, and Marginal Distributions
前面的讨论使得一些一般性的争论关于如何推断最有可能的罪魁祸首,但实际数字有点模糊。本节量化讨论。
条件分布
推断posterior,你必须首先构造一个数学模型的谋杀情景。您已经指定了一个先验的罪魁祸首。你也知道:
?管家保存了老韦布利的手枪在上锁的抽屉,但厨师不拥有手枪。男管家更可能使用了手枪。
?厨师有足够锋利的屠刀供应及禁止管家要踏上厨房。管家不太可能用那把刀。
?管家比厨师老多了,已经有点虚弱。专职管家不太可能使用一种对身体要求的武器铁棒。
构建模型的最简单的方法是估计概率,嫌疑人使用了可能的谋杀武器。这被称为条件分布conditional distribution,,将凶器的分布,由一个特定的值的条件对罪犯。
Pistol Knife Poker
Cook 5% 65% 30% = 100%
Butler 80% 10% 10% = 100%
每个嫌疑犯必须使用一个可能的武器,所以每个条件分布的和是100%
联合分布
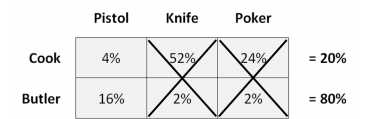
你可以使用罪犯的prior ,及从上一节对侦探小说构建模型的条件分布,这是一个已知的联合分布。
它包含了你对谋杀现场的完整理解,在作任何观察之前。
Pistol Knife Poker
Cook 4% 52% 24% =80%
Butler 16% 2% 2% =20%
因为武器和嫌疑人的组合必须是这六种可能性之一,它们总和为100%。
在本文档中所使用的方法基本上是因果关系的,罪犯选择武器,并使用它犯下谋杀罪。
?罪魁祸首是变量,我们感兴趣的,我们要推断posterior ,所以我们定义了一个prior 变量。
?凶器是变量,我们可以观察到,所以我们定义该变量的条件分布。
因果关系通常是最简单的方法构造一个概率模型,即使你想在相反的方向推断原因,如谋杀武器知识的基础上推断嫌疑人。
边际分布Marginal Distributions
可以使用联合分布来询问各种问题。假设我们想知道手枪是杀人武器的概率。你可以从联合分配的概率来计算 ,厨师使用的手枪和管家用手枪的可能性。你可以做同样的计算,为刀和铁棒。在你“总结”后仍然保持的分布,但联合分布中的一个变量,是剩余变量的边缘分布或更普遍些只是边际。
Pistol Knife Poker
Cook 4% 52% 24%
Butler 16% 2% 2%
= 20% = 54% = 26%
到目前为止,这些边际基本上告诉你你已经知道的东西。更有趣的是,你做了观察之后,并添加一些新的信息的混合。
Whodunit: Infer a Posterior
当验尸官的报告到来时,你可以使用凶器的观察来推断罪魁祸首的posterior ,它应该包含一个改进的疑犯估计。
posterior 是一个有条件边缘,罪犯的边缘,通过观察发现凶器是手枪的条件。在这种简单的情况下,可以从联合分布表中获得posterior
验尸官的报告意味着你可以从表格消除刀和扑克。手枪的剩余值表示每个嫌疑犯的有罪。然而,它们并不是一个适当的分布;数字不加1。概率
完成计算,将每手枪的边际值除以(0.20)。归一化值和产生的后验分布的权重表,
结果并不完全确定,但它看起来对管家不利!
在实践中,模型通常要比在这个例子更复杂,使计算后验概率更困难。应用“真实世界”情景的概率规划需要一个更为复杂的方法,对于模型构建和推理。
接下来是什么:一个更为先进(复杂)的方法
在前一节的联合分布是一个非常简单的模型,只有2变量和一小部分可能的值。而对谋杀的观察武器有力地表明,管家可能是罪魁祸首,还有一种可能性那个厨师有罪。一个更复杂的模型,可以处理更广泛的范围观测可以提供更多的确定性。然而,更多的计算后验概率复杂的模型相对更难。
更复杂的模型:
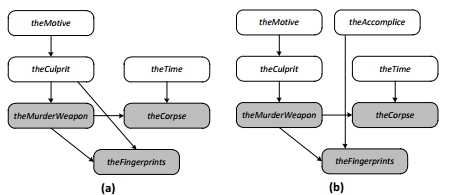
您可以通过扩展联合分布以处理其他变量图2。然而,对于多个变量或变量与许多可能的值表迅速变得不可收拾。此外,表是有用的仅用于离散分布。如果你想为谋杀定义一个时间的分布,它必须代表一个连续的值范围,一张表格无法表示。
一个更灵活和强大的方法是建立一个联合分布的概率模型,以图的形式表示系统的随机变量之间的关系
。图6显示了2个例子,其中(一)为图侦探小说,和(b)延伸图来处理额外的随机变量
该模型表示随机变量之间的关系,如下:
?每个方块代表一个随机变量。
?箭头表示随机变量之间的因果关系。
?阴影框表示可观测的随机变量。
?非阴影框表示不可观测的随机变量,我们希望推断。
对于模型(a),模型是:罪犯选择一个杀人的武器。你观察这个杀人的武器,并用模型和观察来推断出可能的罪犯。即使这个模型表示因果关系,这被称为生成模型,你可以使用它在任何方向推断原因。例如:你知道这个罪犯,你可以用这个观察来推断出最有可能的杀人武器。
模型(b)是一个更复杂的模型,采用了额外的随机变量的谋杀时间,尸体的状态等几个可观察到的。你可以使用这个模型结合多个随机变量的观测计算后验概率,也许证明管家是无辜的,也许产生压倒性的证据,他不得不承认。
更复杂的推理
侦探小说,你可以用简单的算法来推断后从表图2。当你添加变量,这种方法变得更加困难-----特别是如果他们有大量的可能的值----变量表示一个连续的可能值的变量而不工作。更现实的模型需要一个更复杂的方式来推断后验概率
图6中的概念模型实际上是一个图形化的表示形式联合分布的数学表达式。概率程序可以使用这个和贝叶斯推断的后验概率的数学表达任意复杂图,包括有连续变量的图分布。你甚至可以用数学表示来直接定义不能以图形方式表示的模型。
How to Pick the Best Model
模型(a)提供了一个可能的罪犯的估计,但可能不足以定罪。一个更复杂和更先进的模型可能更有说服力。然而,添加更多的变量不一定产生一个更好的模型。通常有一个收益递减的点,超过了该模型的附加复杂度,或者实际上使它变得更糟。
例如,当你将一个多项式拟合为一组数据点时,你可以通过向多项式中添加足够的元素来获得精确的拟合。然而,一个多项式完全适合每个数据点通常摆荡在每个点之间,现象称为过拟合,可能在一定程度上是准确的,但不是很有用。一个多项式与较少的元素,往往可以拟合数据,以及提供了一个更有用的和现实的模型。
你想要的是一个快乐的媒介:一个模型,适合的数据合理,而不过于复杂。简而言之,你需要应用奥卡姆的剃刀,最好的模型是充分符合数据的最简单的一个-----可能模型中的。
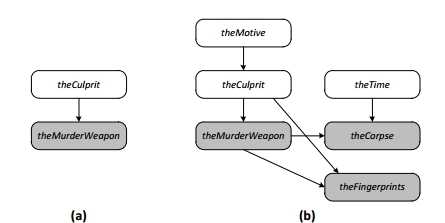
这两者在不同的方式中存在指纹的存在:
?模型(a),罪犯在犯罪现场留下的指纹。
?模型(B),罪犯对于留下指纹很小心,但帮凶也可能留下。
你通常无法确定哪一个模型是最优的。然而,与概率规划,你可以把证据作为一个随机变量,并推断出变量的分布。分配给你每个模型都是最优的概率,并且你可以使用该信息来选择最佳的模型。例如,如果证据为模型(乙)的概率只有15%,共犯的可能增加了不必要的复杂性。因此,你可以用简单的解释:“管家”。
infer.net概率规划
概率规划是一个一般的概念,并且可以在各种各样的方法。使用infer.net有什么优势?总之,infer.net提供在代码中表示图形化模型的简单方法,包括一个推理引擎inference engine处理posteriors的复杂数学推导。本节介绍了infer.net功能,以及它们如何快速帮助你,轻松实现强大的概率方案。
强大而灵活的模式构建
创造一个好的概念模型是困难的,而在infer.net范围。。API 实现了一个广泛的模型,包括标准模型如,Bayes point machine, latent Dirichlet allocation, factor analysis, and principal component analysis通常只有几行代码
可扩展和可组合模型
infer.net建模的API是可组合的,这样就可以实现从简单到复杂的积木概念模型。然而,你不必立即执行整个模型。例如,你可以从一个简化的开始概念模型,捕捉的基本特征。当你工作的时候琐碎的问题,你可以设置在多个阶段的模型和数据,如果需要,直到你有一个完全实现的模型,可以处理真实数据集。infer.net模型也被缩小了计算。你可以开始小数据集和规模,以处理更大量的数据,包括应用并行计算
内置推理机
计算后验概率,通常是相当困难的,而且需要一个深入的了解贝叶斯推理与数值分析。infer.net包括推理为您处理此任务的引擎。与infer.net,您的应用程序的构建一个模型,观察一个或多个变量,然后查询推理机的后延概率。该查询只需要一行代码。推理机
使用任何有支持的算法中的所有数值重举—并返回请求的后验概率。
infer.net 入门2 用一个侦探故事来讲解,通俗易懂
标签:
原文地址:http://www.cnblogs.com/zkp2010/p/5510772.html
.jpg)
.jpg)
.jpg)