标签:
环境:Mac OSX
终端工具:iTerm2
1. 例---显示baidu源码
import urllib2 request = urllib2.Request("http://www.baidu.com") response = urllib2.urlopen(request) print response.read()
2. 有关headers
#爬虫中添加headers为了模拟浏览器的工作,否则有的页面不允许直接访问#
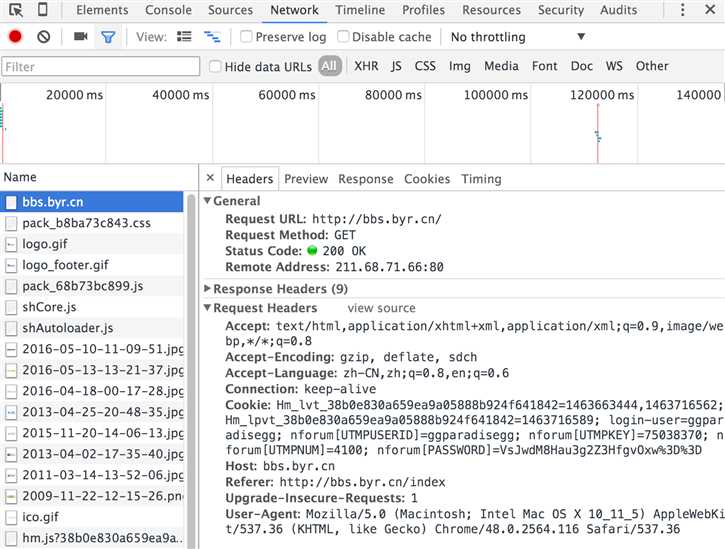
MacOS下查看headers方法:
Chrome:视图-开发者-开发者工具,右侧点击Network,然后单击url(bbs.byr.cn),右边选Headers即可
加入headers的示例:
#coding:utf-8 import urllib import urllib2 url = ‘http://bbs.byr.cn/index‘ user_agent = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36‘ values = {‘username‘ : ‘xxxxxx‘, ‘password‘ : ‘6666666‘ } headers = { ‘User-Agent‘ : user_agent } data = urllib.urlencode(values) request = urllib2.Request(url, data, headers) response = urllib2.urlopen(request) page = response.read() print (page.decode(‘gbk‘).encode(‘utf-8‘))
注意编码问题,Python默认编码为ASCII,所以前面要加上#coding:utf-8。查看网页html源码可以发现<meta>标签中编码为GBK,所以打印的时候需要decode+encode操作,否则汉字将显示乱码。将python2中汉字会出现乱码的事一次性说清楚
标签:
原文地址:http://www.cnblogs.com/buptowl/p/5511640.html