标签:
变量
写三种定义变量的方法
第一种,大家常用的多是这种 user=‘wzc‘ passwd=‘ww‘ 第二种 user1,passwd1=‘wzc1‘,‘www‘ 第三种 #三个单引号或者三个双引号 ww=‘‘‘ sdsdsdsds:%s ‘‘‘%(user)
需要注意一点,我们有的时候会使用拼接,但是这样会比不使用拼接所用的内存要多

这样一个就是使用了三块内存
常量
常量在定义的时候需要注意大写,方便大家识别
#常量一般都是使用大写 MYSQL_CONNECTION="192.168.1.1"
模块
关于第三方库,这点需要说明一下,第三方库的安装命令是pip,豆瓣有镜像源。
需要注意,在安装的时候这个也会涉及到版本问题,所以大家要根据Python的版本来进行安装
pip install pandas
pyc是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。、
pyc在Python2和Python3是有区别的,Python2.X里面会自动把整形转化为长整型,而在Python3.X里面没有这个转换了
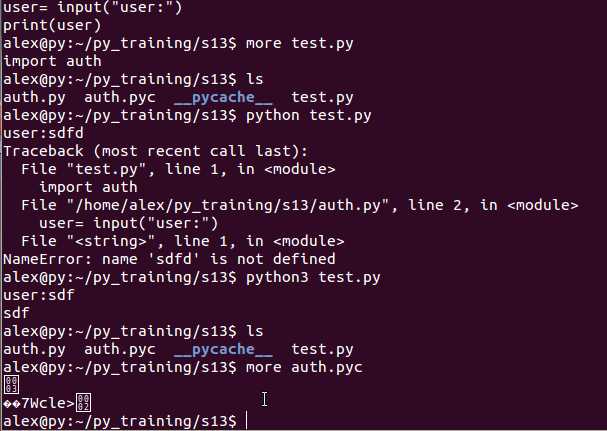
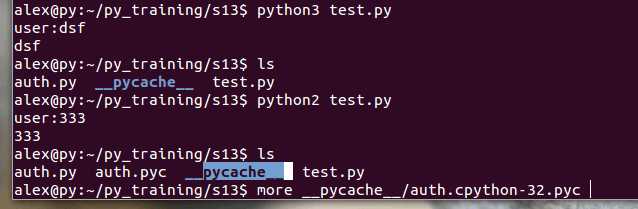
这样就能看出pyc的存储方式.如果auth.py进行了修改,在下次执行的时候,会对比auth.py和auth.pyc的时间
列表
#!/usr/bin/env python # -*- coding: utf-8 -*- # Author:wzc list=[‘sxl‘,‘wzc‘,‘lmd‘,‘yxy‘,‘lhl‘,‘mdq‘,‘lld‘,‘lcj‘] print(list) list.insert(4,‘ql‘) list.insert(5,‘hx‘) print(list) print(list[2:8]) list.remove(list[7]) print(list) del list[4:6]#这是一个全局变量 print(list) list[0]="sxl-zz" print(list) print(list[::2],)
执行结果如下:
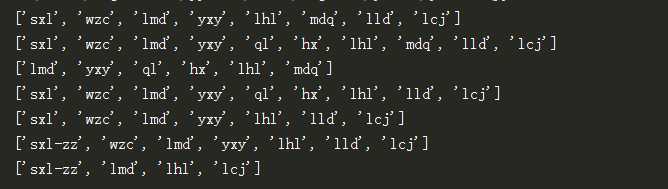
上面就是列表的一些操作,添加,切片,删除,修改,查找
需要注意最后一个是,每间隔一个进行显示。
list2=list.copy() print(list2)
这样复制就是浅copy,就是软链接,如果打算完整复制,需要使用deepcopy。
name="wzc1206fc"
name1="wzc,1206,fc"
print(name.isalnum())#是否是数字
print(name.endswith(‘fc‘))#结尾为fc
print(name.startswith(‘fc‘))#开头为fc
print(name.upper())#变为大写
print(name.lower())#变为小写
print(‘|‘.join(name1.split(",")))#,号换为|
print(name.center(40,‘#‘))#输出
print(name.find(‘1206‘))#查找
print("1206" in name1)#另一种方式的查找
print(name.capitalize())#开头大写
print("####")
w="hello {name},hahaha {age}"#一种print方法
print(w.format(name="wz",age=1))
w2="hahah{0},ddd{1}"#另一种
print(w2.format("wzc",22))
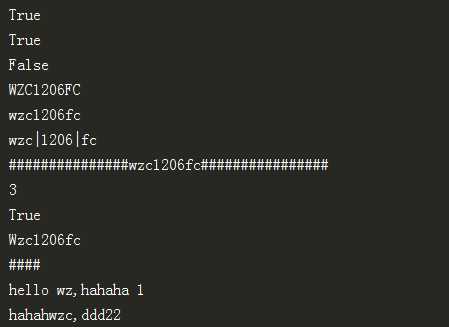
第一个是对应的程序,第二个是每条程序对应的执行结果
还有在执行程序的时候的一点小技巧

get返回none,另一个会使程序报错,在写程序的时候尽量使用第一个。
字典
字典是无须的,但是有的时候我们需要序号来表示其对应关系,这里我们可以使用enumerate,这样就可以得到对应的id号了
dic = {"name":“wzc”,"age":27,"addr":"ww"}
for key,v in dic.items() #效率低,因为有一个dic to list的过程
#最好使用:
for key in dic:
print(key,dic[key])
>>> info[‘name‘] #查看key为’name’的value
‘alex‘
>>> info[‘job‘] = ‘Boss‘ #将key 的value 改为’Boss’
>>> info
{‘age‘: 29, ‘job‘: ‘Boss‘, ‘company‘: ‘AUTOHOME‘, ‘name‘: ‘alex‘}
>>> info[‘city‘] = ‘BJ‘ #如果dict中有key为’city’,就将其值改为’BJ’,如果没有这个key,就创建一条新 纪录
>>> info
{‘age‘: 29, ‘job‘: ‘Boss‘, ‘company‘: ‘AUTOHOME‘, ‘name‘: ‘alex‘, ‘city‘: ‘BJ‘}
>>> info.pop(‘age‘) #删除key为’age’的数据,跟del info[‘age’] 一样
>>> info
{‘job‘: ‘Boss‘, ‘company‘: ‘AUTOHOME‘, ‘name‘: ‘alex‘, ‘city‘: ‘BJ‘}
>>> info.popitem() #随机删除一条数据,dict为空时用此语法会报错
(‘job‘, ‘Boss‘)
>>> info.items() #将dict的key,value转换成列表的形式显示
[(‘company‘, ‘AUTOHOME‘), (‘name‘, ‘alex‘), (‘city‘, ‘BJ‘)]
>>> info.has_key(‘name‘) #判断字典中是否有个叫’name’的key
True
>>> info[‘age‘] #查找一个不存在的key报错,因为’age’刚才已经删除了,所以报错 Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: ‘age‘
>>> info.get(‘age‘) #查找key,如果存在则返回其value,否则则返回None
>>> info.get(‘name‘)
‘alex‘
>>> info.clear() #清空dict
>>> info
{}
>>> info.fromkeys([‘a‘,‘b‘,‘c‘],‘Test‘) #根据列表[‘a’,’b’,’c’]来创建dict里的key,后面 的’Test’是默认value,如果不指定的话则为None
{‘a‘: ‘Test‘, ‘c‘: ‘Test‘, ‘b‘: ‘Test‘}
>>> info
{}
>>> info =info.fromkeys([‘a‘,‘b‘,‘c‘],‘Test‘)
>>> info
{‘a‘: ‘Test‘, ‘c‘: ‘Test‘, ‘b‘: ‘Test‘}
>>> info.setdefault(‘d‘,‘Alex‘) #找一个key为’d’的纪录,如果这个key不存在,那就创建一个叫’d’的key, 并且将其value设置为’Alex’, 如果这个key存在,就直接返回这个key的value,见下一条
‘Alex‘
>>> info.setdefault(‘c‘,‘Alex‘)
‘Test‘
>>> info
{‘a‘: ‘Test‘, ‘c‘: ‘Test‘, ‘b‘: ‘Test‘, ‘d‘: ‘Alex‘}
>>> dict2 = {‘e‘:‘fromDict2‘,‘a‘:‘fromDict2‘} #创建一个新字典
>>> info.update(dict2) #拿这个新字典去更新info,注意dict2中有一个key值’a’与dict info相冲突,这 时dict2的值会覆盖info中的a,如果dict2的key在info中不存在,则创建相应的纪录
>>> info
{‘a‘: ‘fromDict2‘, ‘c‘: ‘Test‘, ‘b‘: ‘Test‘, ‘e‘: ‘fromDict2‘, ‘d‘: ‘Alex‘}
增删改查
dic={
123:{"2":"50", },
234:{"1":"100", }
}
dic2={
345:{"3":"100", },
234:{"4":"100" }
}
dic.update(dic2)
print(dic)
这个直接把字典二中添加到字典一中,如果两个字典有相同的,则会被括号内的字典覆盖
#返回值 该方法没有任何返回值
#以下实例展示了 setdefault()函数的使用方法:
#!/usr/bin/python
dict = {‘Name‘: ‘Zara‘, ‘Age‘: 7}
print("Value : %s" % dict.setdefault(‘Age‘, None))
print ("Value : %s" % dict.setdefault(‘Sex‘, None))
#以上实例输出结果为:
Value : 7
Value : None
print(dic.setdefault("addr":"jl")) #取一个key的值,如果没有就设置一个
dic.setdefault()
很实用的一个功能

items这个是把字典转为列表,当字典数据很多的时候,不要做这个操作

第一个只能用于2.X版本的Python,第二条等于has_key()
标签:
原文地址:http://www.cnblogs.com/wlzhc/p/5514729.html