标签:
FP树构造
FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对。为了达到这样的效果,它采用了一种简洁的数据结构,叫做frequent-pattern tree(频繁模式树)。下面就详细谈谈如何构造这个树,举例是最好的方法。请看下面这个例子:
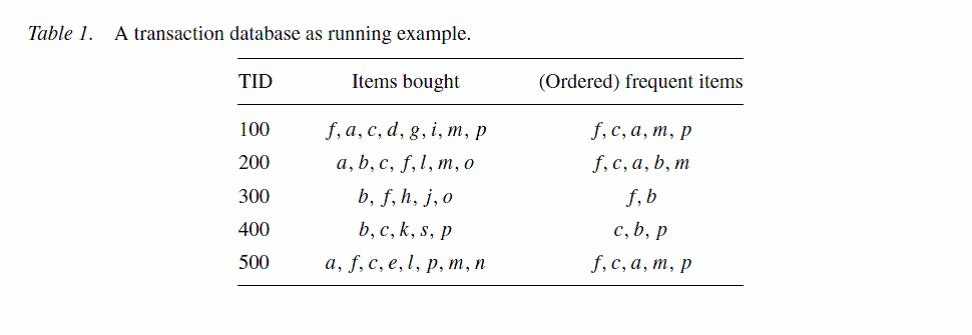
这张表描述了一张商品交易清单,abcdefg代表商品,(ordered)frequent items这一列是把商品按照降序重新进行了排列,这个排序很重要,我们操作的所有项目必须按照这个顺序来,这个顺序的确定非常简单,只要对数据库进行一次扫描就可以得到这个顺序。由于那些非频繁的项目在整个挖掘中不起任何作用,因此在这一列中排除了这些非频繁项目。我们在这个例子中设置最小支持阈值(minimum support threshold)为3。
我们的目标是为整个商品交易清单构造一颗树。我们首先定义这颗树的根节点为null,然后我们开始扫描整个数据库的每一条记录开始构造FP树。
第一步:扫描数据库的第一个交易,也就是TID为100的交易。那么就会得到这颗树的第一个分支<(f:1),(c:1),(a:1),(m:1),(p:1)>。注意这个分支一定是要按照降频排列的。
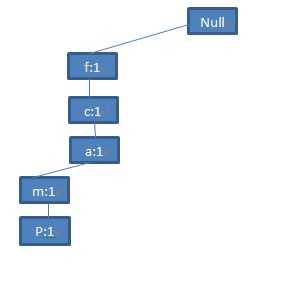
第二步:扫描第二条交易记录(TID=200),我们会有这么一个频繁项目集合<f,c,a,b,m>。仔细观察这个队列,你会发现这个集合的前3项<f,c,a>与第一步产生的路径<f,c,a,m,p>的前三项是相同的,也就是说他们可以共享一个前缀。于是我们在第一步产生的路径的基础上,把<f,c,a>三个节点的数目加1,然后将<(b:1),(m:1)>作为一个分支加在(a:2)节点的后面,成为它的子节点。看下图:
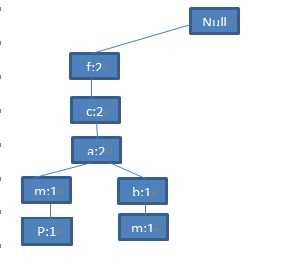
第三步:接着扫描第三条交易记录(TID=300),你会看到这条记录的集合是<f, b>,与已存在的路径相比,只有f是共有的前缀,那么f节点加1,同时再为f节点生成一个新的字节点(b:1).就会有下图:
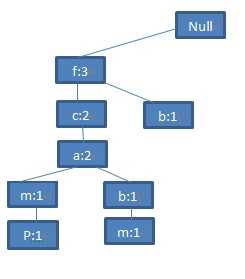
第四步:继续看第四条交易记录,它的集合是<c,b,p>,哦,这回不一样了。你会发现这个集合的第一个元素是c,与现存的已知路径的第一个节点f不一样,那就不用往下比了,没有任何公共前缀。直接将该集合作为根节点的子路径附加上去。就得到了下图(图1):
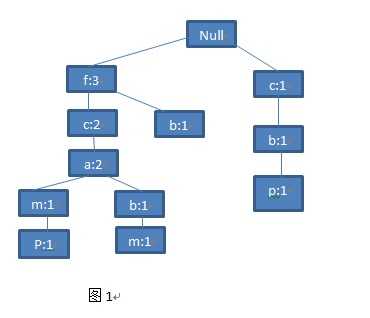
第五步:最后一条交易记录来了,你看到了一条集合<f,c,a,m,p>。你惊喜得发现这条路径和树现有最左边的路径竟然完全一样。那么,这整条路径都是公共前缀,那么这条路径上的所有点都加1好了。就得到了最终的图(图2)。
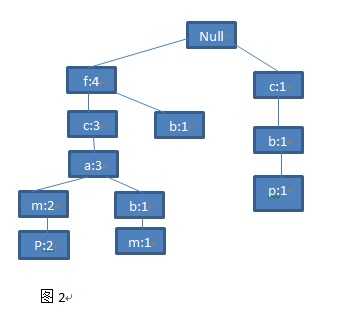
好了,一颗FP树就已经基本构建完成了。等等,还差一点。上述的树还差一点点就可以称之为一个完整的FP树啦。为了便于后边的树的遍历,我们为这棵树又增加了一个结构-头表,头表保存了所有的频繁项目,并且按照频率的降序排列,表中的每个项目包含一个节点链表,指向树中和它同名的节点。罗嗦了半天,可能还是不清楚,好吧直接上图,一看你就明白:
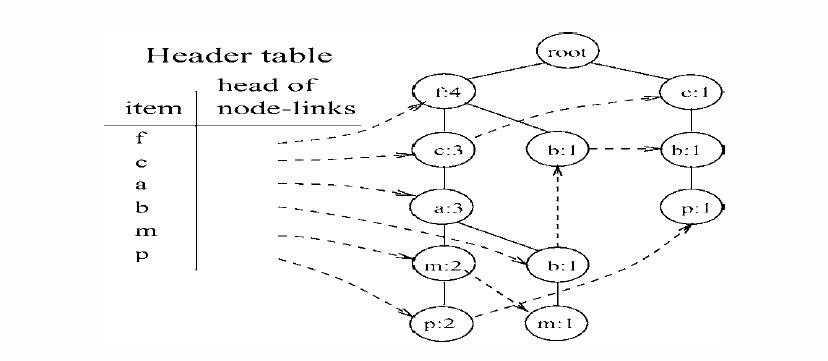
以上就是整个FP树构造的完整过程。聪明的读者一定不难根据上述例子归纳总结出FP树的构造算法。这里就不再赘述。
Frequent Pattern 挖掘之二(FP Growth算法)(转)
标签:
原文地址:http://www.cnblogs.com/xiaohua92/p/5516266.html