标签:style blog http color 使用 os strong io
本文旨在整理内核和应用层分别涉及到的数据结构,从基础数据结构的角度来为内核研究作准备,会在今后的研究中不断补充
目录
1. 进程相关数据结构 1) struct task_struct 2. 内核中的队列/链表对象 3. 内核模块相关数据结构 2) struct module
1. 进程相关数据结构
0x1: task_struct
我们知道,在windows中使用PCB(进程控制块)来对进程的运行状态进行描述,对应的,在linux中使用task_struct结构体存储相关的进程信息,task_struct在linux/sched.h文件里定义
struct task_struct { /* 1. state: 进程执行时,它会根据具体情况改变状态。进程状态是进程调度和对换的依据。Linux中的进程主要有如下状态: 1) TASK_RUNNING: 可运行 处于这种状态的进程,只有两种状态: 1.1) 正在运行 正在运行的进程就是当前进程(由current所指向的进程) 1.2) 正准备运行 准备运行的进程只要得到CPU就可以立即投入运行,CPU是这些进程唯一等待的系统资源 系统中有一个运行队列(run_queue),用来容纳所有处于可运行状态的进程,调度程序执行时,从中选择一个进程投 入运行 2) TASK_INTERRUPTIBLE: 可中断的等待状态 3) TASK_UNINTERRUPTIBLE: 不可中断的等待状态 处于该状态的进程正在等待某个事件(event)或某个资源,它肯定位于系统中的某个等待队列(wait_queue)中。Linux中处于等待状态的进程分为两种: 3.1) 可中断的等待状态 处于可中断等待态的进程可以被信号唤醒,如果收到信号,该进程就从等待状态进入可运行状态,并且加入到运行队列中,等待被调度 3.2) 不可中断的等待状态 处于不可中断等待态的进程是因为硬件环境不能满足而等待,例如等待特定的系统资源,它任何情况下都不能被打断,只能用特定的方式来唤醒它,例如唤醒函数wake_up()等 4) TASK_ZOMBIE: 僵死 进程虽然已经终止,但由于某种原因,父进程还没有执行wait()系统调用,终止进程的信息也还没有回收。顾名思义,处于该状态的进程就是死进程,这种进程实际上是系统中的垃圾,必须进行相应处理以释放其占用的资源。 5) TASK_STOPPED: 暂停 此时的进程暂时停止运行来接受某种特殊处理。通常当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或 SIGTTOU信号后就处于这种状态。例如,正接受调试的进程就处于这种状态 6) TASK_SWAPPING: 换入/换出 */ volatile long state; /* 2. stack 进程内核栈,进程通过alloc_thread_info函数分配它的内核栈,通过free_thread_info函数释放所分配的内核栈 */ void *stack; /* 3. usage 进程描述符使用计数,被置为2时,表示进程描述符正在被使用而且其相应的进程处于活动状态 */ atomic_t usage; /* 4. flags flags是进程当前的状态标志(注意和运行状态区分) 1) #define PF_ALIGNWARN 0x00000001: 显示内存地址未对齐警告 2) #define PF_PTRACED 0x00000010: 标识是否是否调用了ptrace 3) #define PF_TRACESYS 0x00000020: 跟踪系统调用 4) #define PF_FORKNOEXEC 0x00000040: 已经完成fork,但还没有调用exec 5) #define PF_SUPERPRIV 0x00000100: 使用超级用户(root)权限 6) #define PF_DUMPCORE 0x00000200: dumped core 7) #define PF_SIGNALED 0x00000400: 此进程由于其他进程发送相关信号而被杀死 8) #define PF_STARTING 0x00000002: 当前进程正在被创建 9) #define PF_EXITING 0x00000004: 当前进程正在关闭 10) #define PF_USEDFPU 0x00100000: Process used the FPU this quantum(SMP only) #define PF_DTRACE 0x00200000: delayed trace (used on m68k) */ unsigned int flags; /* 5. ptrace ptrace系统调用,成员ptrace被设置为0时表示不需要被跟踪,它的可能取值如下: linux-2.6.38.8/include/linux/ptrace.h 1) #define PT_PTRACED 0x00000001 2) #define PT_DTRACE 0x00000002: delayed trace (used on m68k, i386) 3) #define PT_TRACESYSGOOD 0x00000004 4) #define PT_PTRACE_CAP 0x00000008: ptracer can follow suid-exec 5) #define PT_TRACE_FORK 0x00000010 6) #define PT_TRACE_VFORK 0x00000020 7) #define PT_TRACE_CLONE 0x00000040 8) #define PT_TRACE_EXEC 0x00000080 9) #define PT_TRACE_VFORK_DONE 0x00000100 10) #define PT_TRACE_EXIT 0x00000200 */ unsigned int ptrace; unsigned long ptrace_message; siginfo_t *last_siginfo; /* 6. lock_depth 用于表示获取大内核锁的次数,如果进程未获得过锁,则置为-1 */ int lock_depth; /* 7. oncpu 在SMP上帮助实现无加锁的进程切换(unlocked context switches) */ #ifdef CONFIG_SMP #ifdef __ARCH_WANT_UNLOCKED_CTXSW int oncpu; #endif #endif /* 8. 进程调度 1) prio: 用于保存动态优先级 2) static_prio: 用于保存静态优先级,可以通过nice系统调用来进行修改 3) normal_prio: 它的值取决于静态优先级和调度策略 */ int prio, static_prio, normal_prio; /* 4) rt_priority: 用于保存实时优先级 */ unsigned int rt_priority; /* 5) sched_class: 结构体表示调度类,目前内核中有实现以下四种: 5.1) static const struct sched_class fair_sched_class; 5.2) static const struct sched_class rt_sched_class; 5.3) static const struct sched_class idle_sched_class; 5.4) static const struct sched_class stop_sched_class; */ const struct sched_class *sched_class; /* 6) se: 用于普通进程的调用实体 */ struct sched_entity se; /* 7) rt: 用于实时进程的调用实体 */ struct sched_rt_entity rt; #ifdef CONFIG_PREEMPT_NOTIFIERS /* 9. preempt_notifier preempt_notifiers结构体链表 */ struct hlist_head preempt_notifiers; #endif /* 10. fpu_counter FPU使用计数 */ unsigned char fpu_counter; #ifdef CONFIG_BLK_DEV_IO_TRACE /* 11. btrace_seq blktrace是一个针对Linux内核中块设备I/O层的跟踪工具 */ unsigned int btrace_seq; #endif /* 12. policy policy表示进程的调度策略,目前主要有以下五种: 1) #define SCHED_NORMAL 0 2) #define SCHED_FIFO 1: 先来先服务调度 3) #define SCHED_RR 2: 时间片轮转调度 4) #define SCHED_BATCH 3 5) #define SCHED_IDLE 5 只有root用户能通过sched_setscheduler()系统调用来改变调度策略 */ unsigned int policy; /* 13. cpus_allowed cpus_allowed用于控制进程可以在哪里处理器上运行 */ cpumask_t cpus_allowed; /* 14. RCU同步原语 */ #ifdef CONFIG_TREE_PREEMPT_RCU int rcu_read_lock_nesting; char rcu_read_unlock_special; struct rcu_node *rcu_blocked_node; struct list_head rcu_node_entry; #endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */ #if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT) /* 15. sched_info 用于调度器统计进程的运行信息 */ struct sched_info sched_info; #endif /* 16. tasks 通过list_head将当前进程的task_struct串联进内核的进程列表中,构建;linux进程链表 */ struct list_head tasks; /* 17. pushable_tasks limit pushing to one attempt */ struct plist_node pushable_tasks; /* 18. 进程地址空间 1) mm: 指向进程所拥有的内存描述符 2) active_mm: active_mm指向进程运行时所使用的内存描述符 对于普通进程而言,这两个指针变量的值相同。但是,内核线程不拥有任何内存描述符,所以它们的mm成员总是为NULL。当内核线程得以运行时,它的active_mm成员被初始化为前一个运行进程的active_mm值 */ struct mm_struct *mm, *active_mm; /* 19. exit_state 进程退出状态码 */ int exit_state; /* 20. 判断标志 1) exit_code exit_code用于设置进程的终止代号,这个值要么是_exit()或exit_group()系统调用参数(正常终止),要么是由内核提供的一个错误代号(异常终止) 2) exit_signal exit_signal被置为-1时表示是某个线程组中的一员。只有当线程组的最后一个成员终止时,才会产生一个信号,以通知线程组的领头进程的父进程 */ int exit_code, exit_signal; /* 3) pdeath_signal pdeath_signal用于判断父进程终止时发送信号 */ int pdeath_signal; /* 4) personality用于处理不同的ABI,它的可能取值如下: enum { PER_LINUX = 0x0000, PER_LINUX_32BIT = 0x0000 | ADDR_LIMIT_32BIT, PER_LINUX_FDPIC = 0x0000 | FDPIC_FUNCPTRS, PER_SVR4 = 0x0001 | STICKY_TIMEOUTS | MMAP_PAGE_ZERO, PER_SVR3 = 0x0002 | STICKY_TIMEOUTS | SHORT_INODE, PER_SCOSVR3 = 0x0003 | STICKY_TIMEOUTS | WHOLE_SECONDS | SHORT_INODE, PER_OSR5 = 0x0003 | STICKY_TIMEOUTS | WHOLE_SECONDS, PER_WYSEV386 = 0x0004 | STICKY_TIMEOUTS | SHORT_INODE, PER_ISCR4 = 0x0005 | STICKY_TIMEOUTS, PER_BSD = 0x0006, PER_SUNOS = 0x0006 | STICKY_TIMEOUTS, PER_XENIX = 0x0007 | STICKY_TIMEOUTS | SHORT_INODE, PER_LINUX32 = 0x0008, PER_LINUX32_3GB = 0x0008 | ADDR_LIMIT_3GB, PER_IRIX32 = 0x0009 | STICKY_TIMEOUTS, PER_IRIXN32 = 0x000a | STICKY_TIMEOUTS, PER_IRIX64 = 0x000b | STICKY_TIMEOUTS, PER_RISCOS = 0x000c, PER_SOLARIS = 0x000d | STICKY_TIMEOUTS, PER_UW7 = 0x000e | STICKY_TIMEOUTS | MMAP_PAGE_ZERO, PER_OSF4 = 0x000f, PER_HPUX = 0x0010, PER_MASK = 0x00ff, }; */ unsigned int personality; /* 5) did_exec did_exec用于记录进程代码是否被execve()函数所执行 */ unsigned did_exec:1; /* 6) in_execve in_execve用于通知LSM是否被do_execve()函数所调用 */ unsigned in_execve:1; /* 7) in_iowait in_iowait用于判断是否进行iowait计数 */ unsigned in_iowait:1; /* 8) sched_reset_on_fork sched_reset_on_fork用于判断是否恢复默认的优先级或调度策略 */ unsigned sched_reset_on_fork:1; /* 21. 进程标识符(PID) 在CONFIG_BASE_SMALL配置为0的情况下,PID的取值范围是0到32767,即系统中的进程数最大为32768个 #define PID_MAX_DEFAULT (CONFIG_BASE_SMALL ? 0x1000 : 0x8000) 在Linux系统中,一个线程组中的所有线程使用和该线程组的领头线程(该组中的第一个轻量级进程)相同的PID,并被存放在tgid成员中。只有线程组的领头线程的pid成员才会被设置为与tgid相同的值。注意,getpid()系统调用
返回的是当前进程的tgid值而不是pid值。 */ pid_t pid; pid_t tgid; #ifdef CONFIG_CC_STACKPROTECTOR /* 22. stack_canary 防止内核堆栈溢出,在GCC编译内核时,需要加上-fstack-protector选项 */ unsigned long stack_canary; #endif /* 23. 表示进程亲属关系的成员 1) real_parent: 指向其父进程,如果创建它的父进程不再存在,则指向PID为1的init进程 2) parent: 指向其父进程,当它终止时,必须向它的父进程发送信号。它的值通常与real_parent相同 */ struct task_struct *real_parent; struct task_struct *parent; /* 3) children: 表示链表的头部,链表中的所有元素都是它的子进程 4) sibling: 用于把当前进程插入到兄弟链表中 5) group_leader: 指向其所在进程组的领头进程 */ struct list_head children; struct list_head sibling; struct task_struct *group_leader; struct list_head ptraced; struct list_head ptrace_entry; struct bts_context *bts; /* 24. pids PID散列表和链表 */ struct pid_link pids[PIDTYPE_MAX]; /* 25. thread_group 线程组中所有进程的链表 */ struct list_head thread_group; /* 26. do_fork函数 1) vfork_done 在执行do_fork()时,如果给定特别标志,则vfork_done会指向一个特殊地址 2) set_child_tid、clear_child_tid 如果copy_process函数的clone_flags参数的值被置为CLONE_CHILD_SETTID或CLONE_CHILD_CLEARTID,则会把child_tidptr参数的值分别复制到set_child_tid和clear_child_tid成员。这些标志说明必须改变子
进程用户态地址空间的child_tidptr所指向的变量的值。 */ struct completion *vfork_done; int __user *set_child_tid; int __user *clear_child_tid; /* 27. 记录进程的I/O计数(时间) 1) utime 用于记录进程在"用户态"下所经过的节拍数(定时器) 2) stime 用于记录进程在"内核态"下所经过的节拍数(定时器) 3) utimescaled 用于记录进程在"用户态"的运行时间,但它们以处理器的频率为刻度 4) stimescaled 用于记录进程在"内核态"的运行时间,但它们以处理器的频率为刻度 */ cputime_t utime, stime, utimescaled, stimescaled; /* 5) gtime 以节拍计数的虚拟机运行时间(guest time) */ cputime_t gtime; /* 6) prev_utime、prev_stime是先前的运行时间 */ cputime_t prev_utime, prev_stime; /* 7) nvcsw 自愿(voluntary)上下文切换计数 8) nivcsw 非自愿(involuntary)上下文切换计数 */ unsigned long nvcsw, nivcsw; /* 9) start_time 进程创建时间 10) real_start_time 进程睡眠时间,还包含了进程睡眠时间,常用于/proc/pid/stat, */ struct timespec start_time; struct timespec real_start_time; /* 11) cputime_expires 用来统计进程或进程组被跟踪的处理器时间,其中的三个成员对应着cpu_timers[3]的三个链表 */ struct task_cputime cputime_expires; struct list_head cpu_timers[3]; #ifdef CONFIG_DETECT_HUNG_TASK /* 12) last_switch_count nvcsw和nivcsw的总和 */ unsigned long last_switch_count; #endif struct task_io_accounting ioac; #if defined(CONFIG_TASK_XACCT) u64 acct_rss_mem1; u64 acct_vm_mem1; cputime_t acct_timexpd; #endif /* 28. 缺页统计 */ unsigned long min_flt, maj_flt; /* 29. 进程权能 */ const struct cred *real_cred; const struct cred *cred; struct mutex cred_guard_mutex; struct cred *replacement_session_keyring; /* 30. comm[TASK_COMM_LEN] 相应的程序名 */ char comm[TASK_COMM_LEN]; /* 31. 文件 1) fs 用来表示进程与文件系统的联系,包括当前目录和根目录 2) files 表示进程当前打开的文件 */ int link_count, total_link_count; struct fs_struct *fs; struct files_struct *files; #ifdef CONFIG_SYSVIPC /* 32. sysvsem 进程通信(SYSVIPC) */ struct sysv_sem sysvsem; #endif /* 33. 处理器特有数据 */ struct thread_struct thread; /* 34. nsproxy 命名空间 */ struct nsproxy *nsproxy; /* 35. 信号处理 1) signal: 指向进程的信号描述符 2) sighand: 指向进程的信号处理程序描述符 */ struct signal_struct *signal; struct sighand_struct *sighand; /* 3) blocked: 表示被阻塞信号的掩码 4) real_blocked: 表示临时掩码 */ sigset_t blocked, real_blocked; sigset_t saved_sigmask; /* 5) pending: 存放私有挂起信号的数据结构 */ struct sigpending pending; /* 6) sas_ss_sp: 信号处理程序备用堆栈的地址 7) sas_ss_size: 表示堆栈的大小 */ unsigned long sas_ss_sp; size_t sas_ss_size; /* 8) notifier 设备驱动程序常用notifier指向的函数来阻塞进程的某些信号 9) otifier_data 指的是notifier所指向的函数可能使用的数据。 10) otifier_mask 标识这些信号的位掩码 */ int (*notifier)(void *priv); void *notifier_data; sigset_t *notifier_mask; /* 36. 进程审计 */ struct audit_context *audit_context; #ifdef CONFIG_AUDITSYSCALL uid_t loginuid; unsigned int sessionid; #endif /* 37. secure computing */ seccomp_t seccomp; /* 38. 用于copy_process函数使用CLONE_PARENT标记时 */ u32 parent_exec_id; u32 self_exec_id; /* 39. alloc_lock 用于保护资源分配或释放的自旋锁 */ spinlock_t alloc_lock; /* 40. 中断 */ #ifdef CONFIG_GENERIC_HARDIRQS struct irqaction *irqaction; #endif #ifdef CONFIG_TRACE_IRQFLAGS unsigned int irq_events; int hardirqs_enabled; unsigned long hardirq_enable_ip; unsigned int hardirq_enable_event; unsigned long hardirq_disable_ip; unsigned int hardirq_disable_event; int softirqs_enabled; unsigned long softirq_disable_ip; unsigned int softirq_disable_event; unsigned long softirq_enable_ip; unsigned int softirq_enable_event; int hardirq_context; int softirq_context; #endif /* 41. pi_lock task_rq_lock函数所使用的锁 */ spinlock_t pi_lock; #ifdef CONFIG_RT_MUTEXES /* 42. 基于PI协议的等待互斥锁,其中PI指的是priority inheritance/9优先级继承) */ struct plist_head pi_waiters; struct rt_mutex_waiter *pi_blocked_on; #endif #ifdef CONFIG_DEBUG_MUTEXES /* 43. blocked_on 死锁检测 */ struct mutex_waiter *blocked_on; #endif /* 44. lockdep, */ #ifdef CONFIG_LOCKDEP # define MAX_LOCK_DEPTH 48UL u64 curr_chain_key; int lockdep_depth; unsigned int lockdep_recursion; struct held_lock held_locks[MAX_LOCK_DEPTH]; gfp_t lockdep_reclaim_gfp; #endif /* 45. journal_info JFS文件系统 */ void *journal_info; /* 46. 块设备链表 */ struct bio *bio_list, **bio_tail; /* 47. reclaim_state 内存回收 */ struct reclaim_state *reclaim_state; /* 48. backing_dev_info 存放块设备I/O数据流量信息 */ struct backing_dev_info *backing_dev_info; /* 49. io_context I/O调度器所使用的信息 */ struct io_context *io_context; /* 50. CPUSET功能 */ #ifdef CONFIG_CPUSETS nodemask_t mems_allowed; int cpuset_mem_spread_rotor; #endif /* 51. Control Groups */ #ifdef CONFIG_CGROUPS struct css_set *cgroups; struct list_head cg_list; #endif /* 52. robust_list futex同步机制 */ #ifdef CONFIG_FUTEX struct robust_list_head __user *robust_list; #ifdef CONFIG_COMPAT struct compat_robust_list_head __user *compat_robust_list; #endif struct list_head pi_state_list; struct futex_pi_state *pi_state_cache; #endif #ifdef CONFIG_PERF_EVENTS struct perf_event_context *perf_event_ctxp; struct mutex perf_event_mutex; struct list_head perf_event_list; #endif /* 53. 非一致内存访问(NUMA Non-Uniform Memory Access) */ #ifdef CONFIG_NUMA struct mempolicy *mempolicy; /* Protected by alloc_lock */ short il_next; #endif /* 54. fs_excl 文件系统互斥资源 */ atomic_t fs_excl; /* 55. rcu RCU链表 */ struct rcu_head rcu; /* 56. splice_pipe 管道 */ struct pipe_inode_info *splice_pipe; /* 57. delays 延迟计数 */ #ifdef CONFIG_TASK_DELAY_ACCT struct task_delay_info *delays; #endif /* 58. make_it_fail fault injection */ #ifdef CONFIG_FAULT_INJECTION int make_it_fail; #endif /* 59. dirties FLoating proportions */ struct prop_local_single dirties; /* 60. Infrastructure for displayinglatency */ #ifdef CONFIG_LATENCYTOP int latency_record_count; struct latency_record latency_record[LT_SAVECOUNT]; #endif /* 61. time slack values,常用于poll和select函数 */ unsigned long timer_slack_ns; unsigned long default_timer_slack_ns; /* 62. scm_work_list socket控制消息(control message) */ struct list_head *scm_work_list; /* 63. ftrace跟踪器 */ #ifdef CONFIG_FUNCTION_GRAPH_TRACER int curr_ret_stack; struct ftrace_ret_stack *ret_stack; unsigned long long ftrace_timestamp; atomic_t trace_overrun; atomic_t tracing_graph_pause; #endif #ifdef CONFIG_TRACING unsigned long trace; unsigned long trace_recursion; #endif };
http://oss.org.cn/kernel-book/ch04/4.3.htm http://www.eecs.harvard.edu/~margo/cs161/videos/sched.h.html http://memorymyann.iteye.com/blog/235363 http://blog.csdn.net/hongchangfirst/article/details/7075026 http://oss.org.cn/kernel-book/ch04/4.4.2.htm http://blog.csdn.net/npy_lp/article/details/7335187 http://blog.csdn.net/npy_lp/article/details/7292563
1. singly-linked lists 2. singly-linked tail queues 3. doubly-linked lists 4. doubly-linked tail queues
1. 尽可能的代码重用,化大堆的链表设计为单个链表 2. 在后面的学习中我们会发现,内核中大部分都是"双向循环链表",因为"双向循环链表"的效率是最高的,找头节点,尾节点,直接前驱,直接后继时间复杂度都是O(1) ,而使用单链表,单向循环链表或其他形式的链表是不能完成的。 3. 如果需要构造某类对象的特定列表,则在其结构中定义一个类型为"list_head"指针的成员
linux-2.6.32.63\include\linux\list.h struct list_head { struct list_head *next, *prev; }; 通过这个成员将这类对象连接起来,形成所需列表,并通过通用链表函数对其进行操作(list_head内嵌在原始结构中就像一个钩子,将原始对象串起来) 在这种架构设计下,内核开发人员只需编写通用链表函数,即可构造和操作不同对象的列表,而无需为每类对象的每种列表编写专用函数,实现了代码的重用。 4. 如果想对某种类型创建链表,就把一个list_head类型的变量嵌入到该类型中,用list_head中的成员和相对应的处理函数来对链表进行遍历
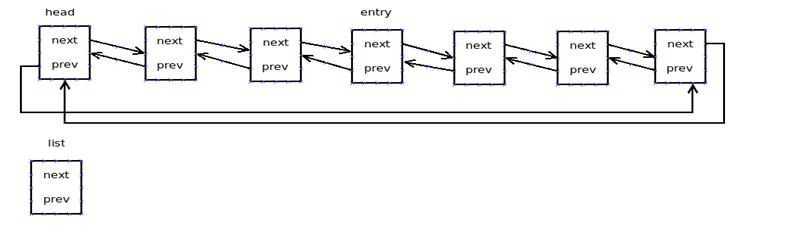
现在我们知道内核中链表的基本元素数据结构、也知道它们的设计原则以及组成原理,接下来的问题是在内核是怎么初始化并使用这些数据结构的呢?那些我们熟知的一个个链表都是怎么形成的呢?
linux内核为这些链表数据结构配套了相应的"操作宏"、以及内嵌函数
1. 链表初始化 1.1 LIST_HEAD_INIT #define LIST_HEAD_INIT(name) { &(name), &(name) } LIST_HEAD_INIT这个宏的作用是初始化当前链表节点,即将头指针和尾指针都指向自己 1.2 LIST_HEAD #define LIST_HEAD(name) struct list_head name = LIST_HEAD_INIT(name) 从代码可以看出,LIST_HEAD这个宏的作用是定义了一个双向链表的头,并调用LIST_HEAD_INIT进行"链表头初始化",将头指针和尾指针都指向自己,因此可以得知在Linux中用头指针的next是否指向自己来判断链表是否为空 1.3 INIT_LIST_HEAD(struct list_head *list) 除了LIST_HEAD宏在编译时静态初始化,还可以使用内嵌函数INIT_LIST_HEAD(struct list_head *list)在运行时进行初始化 static inline void INIT_LIST_HEAD(struct list_head *list) { list->next = list; list->prev = list; } 无论是采用哪种方式,新生成的链表头的指针next,prev都初始化为指向自己 2. 判断一个链表是不是为空链表 2.1 list_empty(const struct list_head *head) static inline int list_empty(const struct list_head *head) { return head->next == head; } 2.2 list_empty_careful(const struct list_head *head) 和list_empty()的差别在于: 函数使用的检测方法是判断表头的前一个结点和后一个结点是否为其本身,如果同时满足则返回0,否则返回值为1。 这主要是为了应付另一个cpu正在处理同一个链表而造成next、prev不一致的情况。但代码注释也承认,这一安全保障能力有限:除非其他cpu的链表操作只有list_del_init(),否则仍然不能保证安全,也就是说,还是需要加
锁保护 static inline int list_empty_careful(const struct list_head *head) { struct list_head *next = head->next; return (next == head) && (next == head->prev); } 3. 链表的插入操作 3.1 list_add(struct list_head *new, struct list_head *head) 在head和head->next之间加入一个新的节点。即表头插入法(即先插入的后输出,可以用来实现一个栈) static inline void list_add(struct list_head *new, struct list_head *head) { __list_add(new, head, head->next); } 3.2 list_add_tail(struct list_head *new, struct list_head *head) 在head->prev(双向循环链表的最后一个结点)和head之间添加一个新的结点。即表尾插入法(先插入的先输出,可以用来实现一个队列) static inline void list_add_tail(struct list_head *new, struct list_head *head) { __list_add(new, head->prev, head); } #ifndef CONFIG_DEBUG_LIST static inline void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next) { next->prev = new; new->next = next; new->prev = prev; prev->next = new; } #else extern void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next); #endif 4. 链表的删除 4.1 list_del(struct list_head *entry) #ifndef CONFIG_DEBUG_LIST static inline void list_del(struct list_head *entry) { /* __list_del(entry->prev, entry->next)表示将entry的前一个和后一个之间建立关联(即架空中间的元素) */ __list_del(entry->prev, entry->next); /* list_del()函数将删除后的prev、next指针分别被设为LIST_POSITION2和LIST_POSITION1两个特殊值,这样设置是为了保证不在链表中的节点项不可访问。对LIST_POSITION1和LIST_POSITION2的访问都将引起
"页故障" */ entry->next = LIST_POISON1; entry->prev = LIST_POISON2; } #else extern void list_del(struct list_head *entry); #endif 4.2 list_del_init(struct list_head *entry) /* list_del_init这个函数首先将entry从双向链表中删除之后,并且将entry初始化为一个空链表。 要注意区分和理解的是: list_del(entry)和list_del_init(entry)唯一不同的是对entry的处理,前者是将entry设置为不可用,后者是将其设置为一个空的链表的开始。 */ static inline void list_del_init(struct list_head *entry) { __list_del(entry->prev, entry->next); INIT_LIST_HEAD(entry); } 5. 链表节点的替换 结点的替换是将old的结点替换成new 5.1 list_replace(struct list_head *old, struct list_head *new) list_repleace()函数只是改变new和old的指针关系,然而old指针并没有释放 static inline void list_replace(struct list_head *old, struct list_head *new) { new->next = old->next; new->next->prev = new; new->prev = old->prev; new->prev->next = new; } 5.2 list_replace_init(struct list_head *old, struct list_head *new) static inline void list_replace_init(struct list_head *old, struct list_head *new) { list_replace(old, new); INIT_LIST_HEAD(old); } 6. 分割链表 6.1 list_cut_position(struct list_head *list, struct list_head *head, struct list_head *entry) 函数将head(不包括head结点)到entry结点之间的所有结点截取下来添加到list链表中。该函数完成后就产生了两个链表head和list static inline void list_cut_position(struct list_head *list, struct list_head *head, struct list_head *entry) { if (list_empty(head)) return; if (list_is_singular(head) && (head->next != entry && head != entry)) return; if (entry == head) INIT_LIST_HEAD(list); else __list_cut_position(list, head, entry); } static inline void __list_cut_position(struct list_head *list, struct list_head *head, struct list_head *entry) { struct list_head *new_first = entry->next; list->next = head->next; list->next->prev = list; list->prev = entry; entry->next = list; head->next = new_first; new_first->prev = head; } 7. 内核链表的遍历操作(重点) 7.1 list_entry Linux链表中仅保存了数据项结构中list_head成员变量的地址,可以通过list_entry宏通过list_head成员访问到作为它的所有者的的起始基地址(思考结构体的成员偏移量的概念,只有知道了结构体基地址才能通过offset得到
成员地址,之后才能继续遍历) 这里的ptr是一个链表的头结点,这个宏就是取的这个链表"头结点(注意不是第一个元素哦,是头结点,要得到第一个元素还得继续往下走一个)"所指结构体的首地址 #define list_entry(ptr, type, member) container_of(ptr, type, member) 7.2 list_first_entry 这里的ptr是一个链表的头结点,这个宏就是取的这个链表"第一元素"所指结构体的首地址 #define list_first_entry(ptr, type, member) list_entry((ptr)->next, type, member) 7.3 list_for_each(pos, head) 得到了链表的第一个元素的基地址之后,才可以开始元素的遍历 #define list_for_each(pos, head) /* prefetch()的功能是预取内存的内容,也就是程序告诉CPU哪些内容可能马上用到,CPU预先其取出内存操作数,然后将其送入高速缓存,用于优化,是的执行速度更快 */ for (pos = (head)->next; prefetch(pos->next), pos != (head); pos = pos->next) 7.4 __list_for_each(pos, head) __list_for_each没有采用pretetch来进行预取 #define __list_for_each(pos, head) for (pos = (head)->next; pos != (head); pos = pos->next) 7.5 list_for_each_prev(pos, head) 实现方法与list_for_each相同,不同的是用head的前趋结点进行遍历。实现链表的逆向遍历 #define list_for_each_prev(pos, head) for (pos = (head)->prev; prefetch(pos->prev), pos != (head); pos = pos->prev) 7.6 list_for_each_entry(pos, head, member) 用链表外的结构体地址来进行遍历,而不用链表的地址进行遍历 #define list_for_each_entry(pos, head, member) for (pos = list_entry((head)->next, typeof(*pos), member); prefetch(pos->member.next), &pos->member != (head); pos = list_entry(pos->member.next, typeof(*pos), member))
#include <linux/module.h> #include <linux/kernel.h> #include <linux/init.h> #include <linux/version.h> #include <linux/list.h> MODULE_LICENSE("Dual BSD/GPL"); struct module *m = &__this_module; static void list_module_test(void) { struct module *mod; list_for_each_entry(mod, m->list.prev, list) printk ("%s\n", mod->name); } static int list_module_init (void) { list_module_test(); return 0; } static void list_module_exit (void) { printk ("unload listmodule.ko\n"); } module_init(list_module_init); module_exit(list_module_exit);
Makefile
# # Variables needed to build the kernel module # name = mod_ls obj-m += $(name).o all: build .PHONY: build install clean build: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules CONFIG_DEBUG_SECTION_MISMATCH=y install: build -mkdir -p /lib/modules/`uname -r`/kernel/arch/x86/kernel/ cp $(name).ko /lib/modules/`uname -r`/kernel/arch/x86/kernel/ depmod /lib/modules/`uname -r`/kernel/arch/x86/kernel/$(name).ko clean: [ -d /lib/modules/$(shell uname -r)/build ] && make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
编译并加载运行,使用dmesg tail命令可以看到我们的内核代码使用list_for_each_entry将当前系统内核中的"LKM内核模块双链表"给遍历出来了
#include <linux/module.h> #include <linux/init.h> #include <linux/list.h> #include <linux/sched.h> #include <linux/time.h> #include <linux/fs.h> #include <asm/uaccess.h> #include <linux/mm.h> MODULE_AUTHOR( "Along" ) ; MODULE_LICENSE( "GPL" ) ; struct task_struct * task = NULL , * p = NULL ; struct list_head * pos = NULL ; struct timeval start, end; int count = 0; /*function_use表示使用哪一种方法测试, * 0:三个方法同时使用, * 1:list_for_each, * 2:list_for_each_entry, * 3:for_each_process */ int function_use = 0; char * method; char * filename= "testlog" ; void print_message( void ) ; void writefile( char * filename, char * data ) ; void traversal_list_for_each( void ) ; void traversal_list_for_each_entry( void ) ; void traversal_for_each_process( void ) ; static int init_module_list( void ) { switch ( function_use) { case 1: traversal_list_for_each( ) ; break ; case 2: traversal_list_for_each_entry( ) ; break ; case 3: traversal_for_each_process( ) ; break ; default : traversal_list_for_each( ) ; traversal_list_for_each_entry( ) ; traversal_for_each_process( ) ; break ; } return 0; } static void exit_module_list( void ) { printk( KERN_ALERT "GOOD BYE!!/n" ) ; } module_init( init_module_list ) ; module_exit( exit_module_list ) ; module_param( function_use, int , S_IRUGO) ; void print_message( void ) { char * str1 = "the method is: " ; char * str2 = "系统当前共 " ; char * str3 = " 个进程/n" ; char * str4 = "开始时间: " ; char * str5 = "/n结束时间: " ; char * str6 = "/n时间间隔: " ; char * str7 = "." ; char * str8 = "ms" ; char data[ 1024] ; char tmp[ 50] ; int cost; printk( "系统当前共 %d 个进程!!/n" , count ) ; printk( "the method is : %s/n" , method) ; printk( "开始时间:%10i.%06i/n" , ( int ) start. tv_sec, ( int ) start. tv_usec) ; printk( "结束时间:%10i.%06i/n" , ( int ) end. tv_sec, ( int ) end. tv_usec) ; printk( "时间间隔:%10i/n" , ( int ) end. tv_usec- ( int ) start. tv_usec) ; memset ( data, 0, sizeof ( data) ) ; memset ( tmp, 0, sizeof ( tmp) ) ; strcat ( data, str1) ; strcat ( data, method) ; strcat ( data, str2) ; snprintf( tmp, sizeof ( count ) , "%d" , count ) ; strcat ( data, tmp) ; strcat ( data, str3) ; strcat ( data, str4) ; memset ( tmp, 0, sizeof ( tmp) ) ; /* * 下面这种转换秒的方法是错误的,因为sizeof最终得到的长度实际是Int类型的 * 长度,而实际的妙数有10位数字,所以最终存到tmp中的字符串也就只有三位 * 数字 * snprintf(tmp, sizeof((int)start.tv_sec),"%d",(int)start.tv_usec ); */ /*取得开始时间的秒数和毫秒数*/ snprintf( tmp, 10, "%d" , ( int ) start. tv_sec ) ; strcat ( data, tmp) ; snprintf( tmp, sizeof ( str7) , "%s" , str7 ) ; strcat ( data, tmp) ; snprintf( tmp, 6, "%d" , ( int ) start. tv_usec ) ; strcat ( data, tmp) ; strcat ( data, str5) ; /*取得结束时间的秒数和毫秒数*/ snprintf( tmp, 10, "%d" , ( int ) end. tv_sec ) ; strcat ( data, tmp) ; snprintf( tmp, sizeof ( str7) , "%s" , str7 ) ; strcat ( data, tmp) ; snprintf( tmp, 6, "%d" , ( int ) end. tv_usec ) ; strcat ( data, tmp) ; /*计算时间差,因为可以知道我们这个程序花费的时间是在 *毫秒级别的,所以计算时间差时我们就没有考虑秒,只是 *计算毫秒的差值 */ strcat ( data, str6) ; cost = ( int ) end. tv_usec- ( int ) start. tv_usec; snprintf( tmp, sizeof ( cost) , "%d" , cost ) ; strcat ( data, tmp) ; strcat ( data, str8) ; strcat ( data, "/n/n" ) ; writefile( filename, data) ; printk( "%d/n" , sizeof ( data) ) ; } void writefile( char * filename, char * data ) { struct file * filp; mm_segment_t fs; filp = filp_open( filename, O_RDWR| O_APPEND| O_CREAT, 0644) ; ; if ( IS_ERR( filp) ) { printk( "open file error.../n" ) ; return ; } fs = get_fs( ) ; set_fs( KERNEL_DS) ; filp->f_op->write(filp, data, strlen ( data) , &filp->f_pos); set_fs( fs) ; filp_close( filp, NULL ) ; } void traversal_list_for_each( void ) { task = & init_task; count = 0; method= "list_for_each/n" ; do_gettimeofday( & start) ; list_for_each( pos, &task->tasks ) { p = list_entry( pos, struct task_struct, tasks ) ; count++ ; printk( KERN_ALERT "%d/t%s/n" , p->pid, p->comm ) ; } do_gettimeofday( & end) ; print_message( ) ; } void traversal_list_for_each_entry( void ) { task = & init_task; count = 0; method= "list_for_each_entry/n" ; do_gettimeofday( & start) ; list_for_each_entry( p, & task->tasks, tasks ) { count++ ; printk( KERN_ALERT "%d/t%s/n" , p->pid, p->comm ) ; } do_gettimeofday( & end) ; print_message( ) ; } void traversal_for_each_process( void ) { count = 0; method= "for_each_process/n" ; do_gettimeofday( & start) ; for_each_process( task) { count++; printk( KERN_ALERT "%d/t%s/n" , task->pid, task->comm ) ; } do_gettimeofday( & end) ; print_message( ) ; }
Makefile
# ## Variables needed to build the kernel module # # name = trave_process obj-m += $(name).o all: build .PHONY: build install clean build: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules CONFIG_DEBUG_SECTION_MISMATCH=y install: build -mkdir -p /lib/modules/`uname -r`/kernel/arch/x86/kernel/ cp $(name).ko /lib/modules/`uname -r`/kernel/arch/x86/kernel/ depmod /lib/modules/`uname -r`/kernel/arch/x86/kernel/$(name).ko clean: [ -d /lib/modules/$(shell uname -r)/build ] && make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
编译、加载并运行后,可以根据进程链表(task_struct链表)遍历出当前系统内核中存在的进程
http://blog.csdn.net/tigerjibo/article/details/8299599 http://www.cnblogs.com/chengxuyuancc/p/3376627.html http://blog.csdn.net/tody_guo/article/details/5447402
3. 内核模块相关数据结构
0x1: struct module
结构体struct module在内核中代表一个内核模块,通过insmod(实际执行init_module系统调用)把自己编写的内核模块插入内核时,模块便与一个 struct module结构体相关联,并成为内核的一部分,也就是说在内核中,以module这个结构体代表一个内核模块(和windows下kprocess、kthread的概念很类似),从这里也可以看出,在内核领域,windows和linux在很多地方是异曲同工的
struct module { /* enum module_state { MODULE_STATE_LIVE, //模块当前正常使用中(存活状态) MODULE_STATE_COMING, //模块当前正在被加载 MODULE_STATE_GOING, //模块当前正在被卸载 }; load_module函数中完成模块的部分创建工作后,把状态置为 MODULE_STATE_COMING sys_init_module函数中完成模块的全部初始化工作后(包括把模块加入全局的模块列表,调用模块本身的初始化函数),把模块状态置为MODULE_STATE_LIVE 使用rmmod工具卸载模块时,会调用系统调用delete_module,会把模块的状态置为MODULE_STATE_GOING 这是模块内部维护的一个状态 */ enum module_state state; /* list是作为一个列表的成员,所有的内核模块都被维护在一个全局链表中,链表头是一个全局变量struct module *modules。任何一个新创建的模块,都会被加入到这个链表的头部 struct list_head { struct list_head *next, *prev; }; 这里,我们需要再次理解一下,链表是内核中的一个重要的机制,包括进程、模块在内的很多东西都被以链表的形式进行组织,因为是双向循环链表,我们可以任何一个modules->next遍历并获取到当前内核中的任何链表元素,这
在很多的枚举场景、隐藏、反隐藏的技术中得以应用 */ struct list_head list; /* name是模块的名字,一般会拿模块文件的文件名作为模块名。它是这个模块的一个标识 */ char name[MODULE_NAME_LEN]; /* 该成员是一个结构体类型,结构体的定义如下: struct module_kobject { /* kobj是一个struct kobject结构体 kobject是组成设备模型的基本结构。设备模型是在2.6内核中出现的新的概念,因为随着拓扑结构越来越复杂,以及要支持诸如电源管理等新特性的要求,向新版本的内核明确提出了这样的要求:需要有一个对系统的一般性抽
象描述。设备模型提供了这样的抽象 kobject最初只是被理解为一个简单的引用计数,但现在也有了很多成员,它所能处理的任务以及它所支持的代码包括:对象的引用计数;sysfs表述;结构关联;热插拔事件处理。下面是kobject结构的定义: struct kobject { /* k_name和name都是该内核对象的名称,在内核模块的内嵌kobject中,名称即为内核模块的名称 */ const char *k_name; char name[KOBJ_NAME_LEN]; /* kref是该kobject的引用计数,新创建的kobject被加入到kset时(调用kobject_init),引用计数被加1,然后kobject跟它的parent建立关联时,引用计数被加1,所以一个新创建的kobject,其引用计数总是为2 */ struct kref kref; /* entry是作为链表的节点,所有同一子系统下的所有相同类型的kobject被链接成一个链表组织在一起 */ struct list_head entry; /* parent指向该kobject所属分层结构中的上一层节点,所有内核模块的parent是module */ struct kobject *parent; /* 成员kset就是嵌入相同类型结构的kobject集合。下面是struct kset结构体的定义: struct kset { struct subsystem *subsys; struct kobj_type *ktype; struct list_head list; spinlock_t list_lock; struct kobject kobj; struct kset_uevent_ops * uevent_ops; }; */ struct kset *kset; /* ktype则是模块的属性,这些属性都会在kobject的sysfs目录中显示 */ struct kobj_type *ktype; //dentry则是文件系统相关的一个节点 struct dentry *dentry; }; */ struct kobject kobj; /* mod指向包容它的struct module成员 */ struct module *mod; }; */ struct module_kobject mkobj; struct module_param_attrs *param_attrs; const char *version; const char *srcversion; /* Exported symbols */ const struct kernel_symbol *syms; unsigned int num_syms; const unsigned long *crcs; /* GPL-only exported symbols. */ const struct kernel_symbol *gpl_syms; unsigned int num_gpl_syms; const unsigned long *gpl_crcs; unsigned int num_exentries; const struct exception_table_entry *extable; int (*init)(void); /* 初始化相关 */ void *module_init; void *module_core; unsigned long init_size, core_size; unsigned long init_text_size, core_text_size; struct mod_arch_specific arch; int unsafe; int license_gplok; #ifdef CONFIG_MODULE_UNLOAD struct module_ref ref[NR_CPUS]; struct list_head modules_which_use_me; struct task_struct *waiter; void (*exit)(void); #endif #ifdef CONFIG_KALLSYMS Elf_Sym *symtab; unsigned long num_symtab; char *strtab; struct module_sect_attrs *sect_attrs; #endif void *percpu; char *args; };
知道了struct module这个结构体是在内核中用于标识模块的结构体变量,也知道可以通过循环双链表的方式进行枚举,还有一个问题是我们从哪里切入进行枚举呢?即我们怎么获取到这个链表中的某一项的呢?这就要谈到宏THIS_MODULE,它的定义
#define THIS_MODULE (&__this_module)
__this_module是一个struct module变量,代表"当前模块"(跟current有几分相似),可以通过THIS_MODULE宏来引用模块的struct module结构
从struct module结构体可以看出,在内核态,我们如果要枚举当前模块列表,可以使用list、kobj这两个成员域进行枚举
Relevant Link:
http://lxr.free-electrons.com/source/include/linux/module.h http://www.cs.fsu.edu/~baker/devices/lxr/http/source/linux/include/linux/module.h http://blog.chinaunix.net/uid-9525959-id-2001630.html http://blog.csdn.net/linweig/article/details/5044722
Copyright (c) 2014 LittleHann All rights reserved
linux内核数据结构学习总结(undone),布布扣,bubuko.com
标签:style blog http color 使用 os strong io
原文地址:http://www.cnblogs.com/LittleHann/p/3865490.html