标签:
C语言有丰富的数据类型,因此它很适合用来编写数据库,如DB2、Oracle都是C语言写的。
C语言的数据类型大致可以分为下图中的几类:
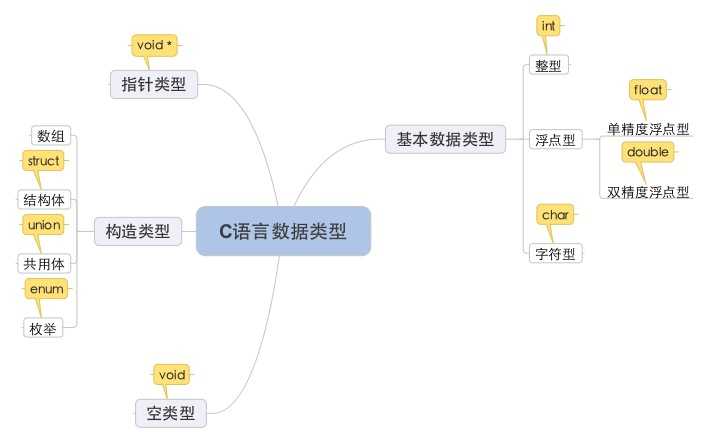
跟其他语言一样,C语言中用变量来存储计算过程使用的值,任何变量都必须先定义类型再使用。为什么一定要先定义呢?因为变量的类型决定了变量占用的存储空间,所以定义变量类型,就是为了给该变量分配适当的存储空间,以便存放数据。比如你是char类型,我就只给你分配1个字节就够了,没必要分配2个字节、3个字节乃至更多的存储空间。
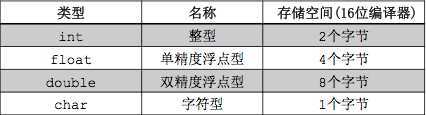
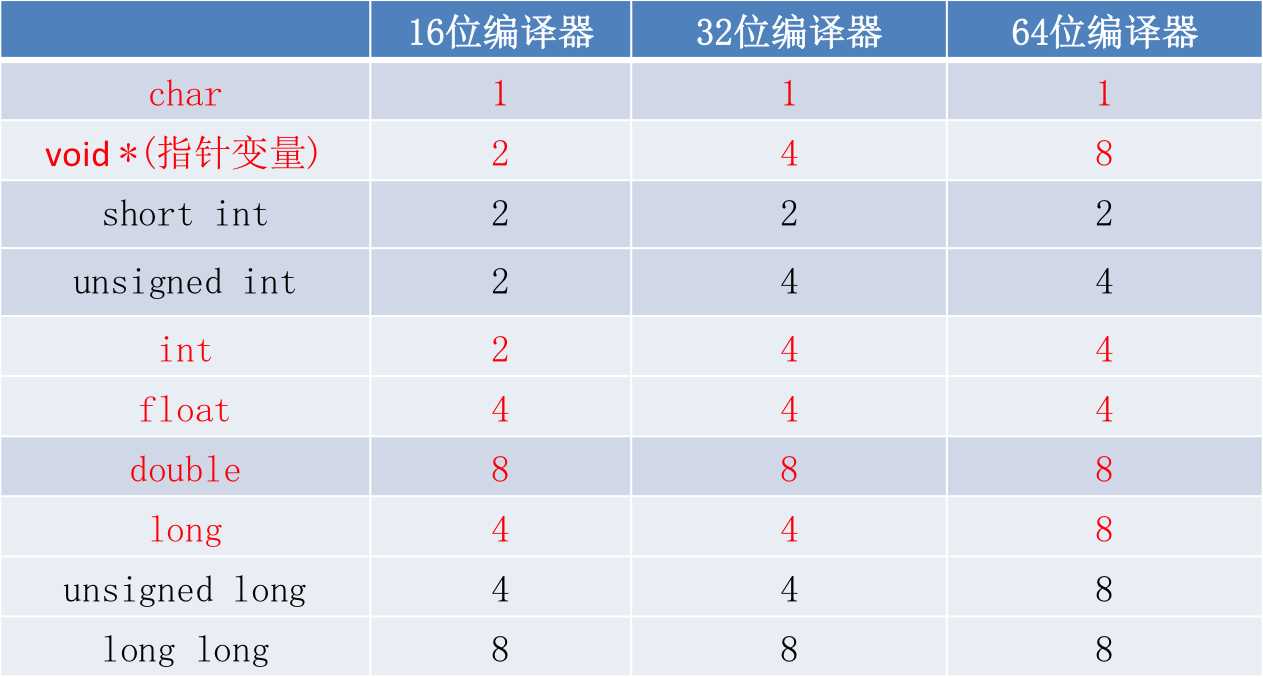
下面的表格描述了在16位编译器环境下,基本数据类型所占用的存储空间,了解这些细节,对以后学习指针和数组时是很有帮助的
需要注意的是:
1> 在Java中,你声明了一个局部变量后,如果没有经过初始化赋值就使用该变量,编译器直接报错

第9行报错了,因为变量a没有初始化
2> 在C语言中,你声明看一个局部变量后,没有经过初始化赋值是可以使用的

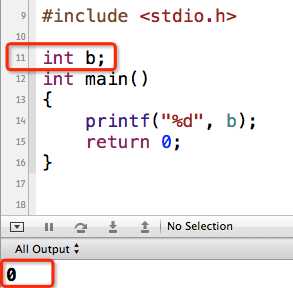
1 #include <stdio.h>
2
3 int main()
4 {
5 int b;
6 printf("%d", b);
7 return 0;
8 }
但这是很危险的,不建议这样做。大多数人应该觉得变量b打印出来应该是0,其实不是。因为系统会随意给变量b赋值,得到的是垃圾数据。
上述代码的打印结果是: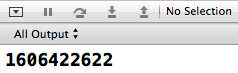 因此,局部变量还是必须先进行初始化赋值,然后再使用,这样才是最安全的做法。
因此,局部变量还是必须先进行初始化赋值,然后再使用,这样才是最安全的做法。
* 如果是全局的int类型变量,系统会默认赋值为0
于是,使用char存储大写字母A有2种赋值方式:
// 方式1
char c = ‘A‘;
// 方式2
char c = 65;
上面两种方式是等效的,因为大写字母A的ASCII码值刚好为65。点击查看ASCII码表的所有值。
汉字或者字符串需要用字符数组来存储,因为一个汉字占了2个字符,一个字符串是由一个或者多个字符组成的。
因此,下面的写法都是错误的:
char c1 = ‘我‘;
char c2 = ‘123‘;
char c3 = "123";
我们还可以在基本数据类型的前面加一些修饰符,也有人称之为限定符,一样的意思。
有以下4种类型修饰符:
这些修饰符最常是用来修饰int类型(可以省略int)
1 // 下面两种写法是等价的
2 short int s1 = 1;
3 short s2 = 1;
4
5 // 下面两种写法是等价的
6 long int l1 = 2;
7 long l2 = 2;
8
9 // 可以连续使用2个long
10 long long ll = 10;
11
12 // 下面两种写法是等价的
13 signed int si1 = 3;
14 signed si2 = 3;
15
16 // 下面两种写法是等价的
17 unsigned int us1 = 4;
18 unsigned us2 = 4;
19
20 // 也可以同时使用2种修饰符
21 signed short int ss = 5;
22 unsigned long int ul = 5;
1> short和long可以提供不同长度的整型数,也就是可以改变整型数的取值范围,比如short的取值范围是-32768~32767,long的取值范围就是-2147483648~2147483647
2> 当然,数据的存储长度也会跟着变化。比如,在64位编译器环境下,short占2个字节(16位),int占4个字节(32位),long占8个字节(64位)。世界上的编译器林林总总,不同编译器环境下,取值范围和占用的长度是不一样的,不过幸运的是,ANSI \ ISO制定了以下规则:
* short跟int至少为16位(2字节)
* long至少为32位(4字节)
* short的长度不能大于int,int的长度不能大于long
* char一定为为8位(1字节),毕竟char是我们编程能用的最小数据类型
1> signed代表有符号,包括正数、负数和0;unsigned代表无符号,只包括正数和0。比如,signed的取值范围是-32768~32767,那么unsigned的取值范围是0~65535,当然,不同的编译器有不同的取值范围
2> 其实,signed和unsigned的区别就是它们的最高位是否要当做符号位,并不会像short和long那样改变数据的长度,即所占的字节数,
unsigned char c1 = 10;
signed char c2 = -10;
long double d1 = 12.0;
红色的代表常用的数据类型
标签:
原文地址:http://www.cnblogs.com/LiLihongqiang/p/5544506.html