标签:
Bag-of-words模型是信息检索领域常用的文档表示方法。在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。 也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。举个例子就好理解:
例如有如下两个文档:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “likes”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数。不过,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序。
Bag-of-words模型应用于图像表示:
为了表示一幅图像,我们可以将图像看作文档,即若干个“视觉词汇”的集合,同样的,视觉词汇相互之间没有顺序。
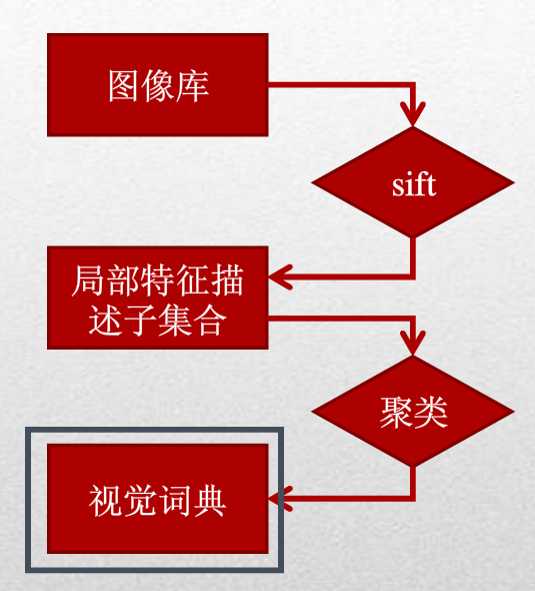
由于图像中的词汇不像文本文档中的那样是现成的,我们需要首先从图像中提取出相互独立的视觉词汇,这通常需要经过三个步骤:(1)特征检测,(2)特征表示,(3)单词本的生成。 下图是从图像中提取出相互独立的视觉词汇:

通过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛, 嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
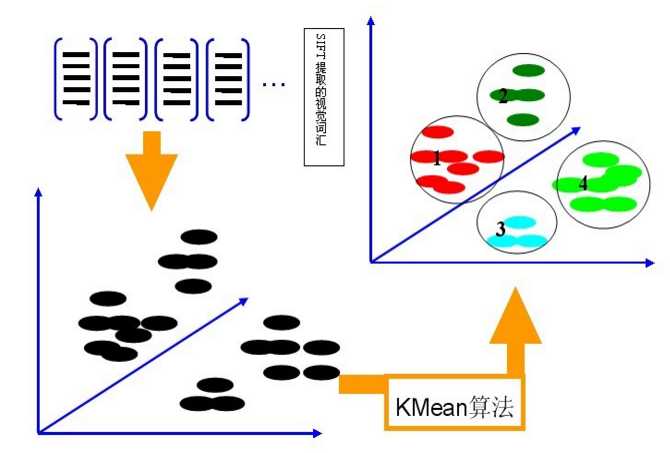
利用K-Means算法构造单词表。用K-means对第二步中提取的N个SIFT特征进行聚类,K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。聚类中心有k个(在BOW模型中聚类中心我们称它们为视觉词),码本的长度也就为k,计算每一幅图像的每一个SIFT特征到这k个视觉词的距离,并将其映射到距离最近的视觉词中(即将该视觉词的对应词频+1)。完成这一步后,每一幅图像就变成了一个与视觉词序列相对应的词频矢量。
假定我们将K设为4,那么单词表的构造过程如下图所示:
第三步:
利用单词表的中词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维数值向量。将这些特征映射到为码本矢量,码本矢量归一化,最后计算其与训练码本的距离,对应最近距离的训练图像认为与测试图像匹配。请看下图:
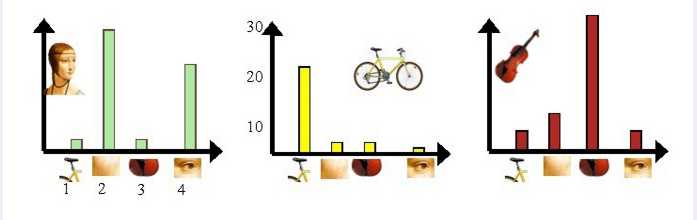
我们从人脸、自行车和吉他三个目标类图像中提取出的不同视觉词汇,而构造的词汇表中,会把词义相近的视觉词汇合并为同一类,经过合并,词汇表中只包含了四个视觉单词,分别按索引值标记为1,2,3,4。通过观察可以看到,它们分别属于自行车、人脸、吉他、人脸类。统计这些词汇在不同目标类中出现的次数可以得到每幅图像的直方图表示:
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]
其实这个过程非常简单,就是针对人脸、自行车和吉他这三个文档,抽取出相似的部分(或者词义相近的视觉词汇合并为同一类),构造一个词典,词典中包含4个视觉单词,即Dictionary = {1:”自行车”, 2. “人脸”, 3. “吉他”, 4. “人脸类”},最终人脸、自行车和吉他这三个文档皆可以用一个4维向量表示,最后根据三个文档相应部分出现的次数画成了上面对应的直方图。一般情况下,K的取值在几百到上千,在这里取K=4仅仅是为了方便说明。
第一步:利用SIFT算法从不同类别的图像中提取视觉词汇向量,这些向量代表的是图像中局部不变的特征点;
第二步:将所有特征点向量集合到一块,利用K-Means算法合并词义相近的视觉词汇,构造一个包含K个词汇的单词表;
第三步:统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个K维数值向量。
视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(1)
标签:
原文地址:http://www.cnblogs.com/zjiaxing/p/5548265.html