标签:
1 数据库索引(顺序、B-+、散列)
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
索引分为聚簇索引和非聚簇索引两种,还有覆盖索引,聚簇索引 是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
为什么要创建索引
创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?因为,增加索引也有许多不利的方面。
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
在哪建索引
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。一般来说,应该在这些列上创建索引:
在经常需要搜索的列上,可以加快搜索的速度;
在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少,不利于使用索引。
第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改操作远远多于检索操作时,不应该创建索引。
2 数据库事务的特征
数据库事务是指作为单个逻辑工作单元执行的一系列操作,这些操作要么全做要么全不做,是一个不可分割的工作单位。
数据库事务的四大特性(简称ACID)是:
(1) 原子性(Atomicity)
事务的原子性指的是,事务中包含的程序作为数据库的逻辑工作单位,它所做的对数据修改操作要么全部执行,要么完全不执行。这种特性称为原子性。
例如银行取款事务分为2个步骤(1)存折减款(2)提取现金。不可能存折减款,却没有提取现金。2个步骤必须同时完成或者都不完成。
(2)一致性(Consistency)
事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。这种特性称为事务的一致性。假如数据库的状态满足所有的完整性约束,就说该数据库是一致的。
例如完整性约束a+b=10,一个事务改变了a,那么b也应随之改变。
(3)分离性(亦称独立性Isolation)
分离性指并发的事务是相互隔离的。即一个事务内部的操作及正在操作的数据必须封锁起来,不被其它企图进行修改的事务看到。假如并发交叉执行的事务没有任何控制,操纵相同的共享对象的多个并发事务的执行可能引起异常情况。
(4)持久性(Durability)
持久性意味着当系统或介质发生故障时,确保已提交事务的更新不能丢失。即一旦一个事务提交,DBMS保证它对数据库中数据的改变应该是永久性的,即对已提交事务的更新能恢复。持久性通过数据库备份和恢复来保证。
3 数据库优化(详见http://blog.csdn.net/littlehorsebro/article/details/51546846)
单机:
(1)创建索引:在数据库设计的时候,要能够充分的利用索引带来的性能提升?如何建立索引?建立什么样的索引?在哪些字段上建立索引?见以上“数据库索引”
(2)sql语句:设计数据库的原则就是尽可能少的进行数据库写操作(插入,更新,删除等),查询越简单越好(单表查询 > inner join> 其他)。
(3)配置缓存:配置缓存可以有效的降低数据库查询读取次数,从而缓解数据库服务器压力,达到优化的目的。可配置的缓存包括索引缓存(key_buffer),排序缓存(sort_buffer),查询缓存(query_buffer),表描述符缓存(table_cache),
(4)切表:分表包括两种方式:横向分表和纵向分表,其中,横向分表比较有使用意义,故名思议,横向切表就是指把记录分到不同的表中,而每条记录仍旧是完整的(纵向切表后每条记录是不完整的),例如原始表中有100条记录,我要切成2个表,那么最简单也是最常用的方法就是ID取摸切表法,本例中,就把ID为1,3,5,7。。。的记录存在一个表中,ID为2,4,6,8,。。。的记录存在另一张表中。虽然横向切表可以减少查询强度,但是它也破坏了原始表的完整性,如果该表的统计操作比较多,那么就不适合横向切表。横向切表有个非常典型的用法,就是用户数据:每个用户的用户数据一般都比较庞大,但是每个用户数据之间的关系不大,因此这里很适合横向切表。最后,要记住一句话就是:分表会造成查询的负担,因此在数据库设计之初,要想好是否真的适合切表的优化
(5)日志分析:通过分析日志(查询吞吐量,数据量监控;慢查询分析:索引、IO、CPU),可以找到系统性能的瓶颈,从而进一步寻找优化方案
分布式数据库集群:这种分布式集群的技术关键就是“同步复制”

分布式数据库结构
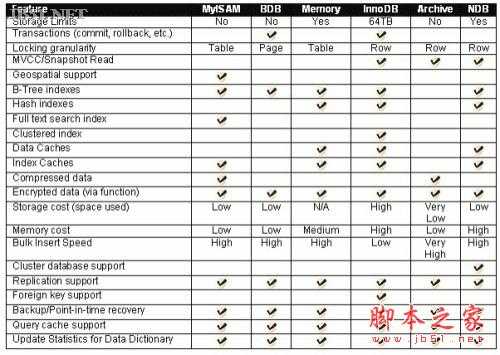
4 数据库引擎
使用MySQL插件式存储引擎体系结构,允许数据库专 业人员为特定的应用需求选择专门的存储引擎,完全不需要管理任何特殊的应用编码要求。采用MySQL服务器体系结构,由于在存储级别上提供了一致和简单的 应用模型和API,应用程序编程人员和DBA可不再考虑所有的底层实施细节。因此,尽管不同的存储引擎具有不同的能力,应用程序是与之分离的。
MySQL支持数个存储引擎作为对不同表的类型的处理器。MySQL存储引擎包括处理事务安全表的引擎和处理非事务安全表的引擎:标签:
原文地址:http://blog.csdn.net/littlehorsebro/article/details/51544525