标签:
SQLite是一款轻量、快速、跨平台的嵌入式数据库,是遵守ACID(注:ACID指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability))的关系型数据库管理系统,它包含在一个相对小的C库中。
SQLite 的设计目标是简单,从这种意义上说,SQLite 和其他很多现代的 SQL 数据库都不相同。SQLite 力求简单,即使这导致了它的某些特征偶尔执行效率比较低。它可以很简单地维护、定制、操作、管理和嵌入到 C 应用程序中。它使用简单的技术实现了 ACID 特性。
SQLite 把所有文件存储在一个单一的普通本地文件里面,你可以把它放在本地系统的任何目录中。任何有读取该文件权限的用户都可以读取数据库里面的所有内容。任何一个有当前目录写入权限的用户,都可以对数据库做任何修改。SQLite 使用另一个单独的日志文件来保存事务恢复信息,用来防止事务中止或系统故障。你可以用程序指令来改变 SQLite 库的一些行为。
SQLite 允许多个应用同时连接同一个数据库。当然,它所支持的并发事务是有一定限制的:SQLite允许任何数量的并发读取事务在数据库上同时执行,但只允许一个写入事务独占执行。
本文从native和Frameworks两个层面的实现来说明Android系统中SQLite的实现。
SQlite动态库的软件架构如下图所示:
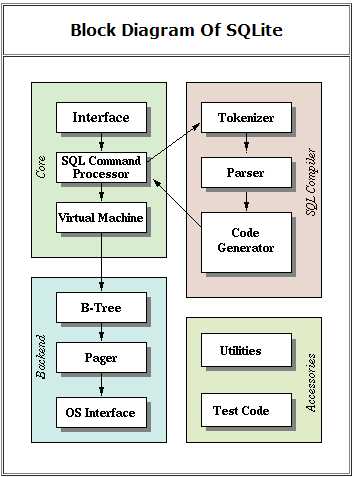
SQLite的实现大体上可以划分为前端和后端两大块。
前端:前端预处理应用程序输入的 SQL 语句和 SQLite 命令。它分析、优化这些语句(和命令),然后生成后端可以解析的 SQLite 内部字节码程序。前端实现了 sqlite3_prepare 接口方法。
(1)编程接口(Interface)
对数据库使用者提供的接口方法。
(2)词法分析器(The tokenizer)
分词器把输入的语句分割成记号。
(3)语法分析器(The parser)
词法分析器通过分析词法分析器产生的记号来确定语句的结构,并生成解析树。语法分析器还包括一个优化器来重构解析树,并生成一个可以产生高效率的字节码(bytecode)程序的等效的解析树。
(4)代码生成器(The code generator)
代码生成器遍历解析树,生成一个等效的字节码程序。
后端:后端是一个解释字节码(bytecode)程序的引擎。后端做实际的数据库读写工作。后端实现了 sqlite3_bind_*,sqlite3_step,sqlite3_column_*,sqlite3_reset 和 sqlite3_finalize 接口方法。
(1)虚拟机 (VM, The Virtual Machine)
虚拟机是内部字节码(bytecode)语言的解释程序。它运行字节码(bytecode)程序来执行 SQL 语句的操作。它是数据库数据的最终操作者。它把数据库看作表和索引的集合,而表或索引则是一系列数据记录的集合。
(2)B/B+-tree
B/B+ 树把每一个数据记录组织到一个有序的树形数据结构中;表和索引分别存放在 B+ 树和 B 树。此模块帮助 VM 在树中搜索、插入和删除数据记录。它也帮助 VM 创建新的树,删除旧的树。
(3)页面管理器(pager)
Pager 模块在文件系统顶部实现了面向页面的数据库文件抽象。它管理内存中的由 B/B+ 树使用的数据库页面缓存,另外,它也管理文件锁和日志记录,以便实现事务的 ACID 特性。
(4)操作系统接口
操作系统接口模块为不同的操作系统抽象出了统一的接口。
本节介绍SQLite各模块的实现方式。
SQLite把整个数据库存储在一个数据库文件中。
为了便于管理和读写数据库,SQLite 把每一个数据库(包括内存数据库(in-memory database))都划分为大小固定的页面(page),页面大小可以是512~32768字节(默认1024字节,在数据库文件创建之前可以通过pragma命令修改页大小)。数据库文件可以看作是页面的数组,页面的索引是从1开始,不是从0开始(页面0会被当作NULL页面,即不是一个实际存在的页面),页面索引最大是2^31-1。
页面的类型可以分为4种:leaf、internal、overflow和free。
第1页一定是internal类型的,而且第1页的前100字节固定存放文件头信息,它描述了整个数据库的属性。文件头的格式如下:
|
Offset |
Size |
Description |
|
0 |
16 |
The header string: "SQLite format 3\000" |
|
16 |
2 |
The database page size in bytes. Must be a power of two between 512 and 32768 inclusive, or the value 1 representing a page size of 65536. |
|
18 |
1 |
File format write version. 1 for legacy; 2 for WAL. |
|
19 |
1 |
File format read version. 1 for legacy; 2 for WAL. |
|
20 |
1 |
Bytes of unused "reserved" space at the end of each page. Usually 0. |
|
21 |
1 |
Maximum embedded payload fraction. Must be 64. |
|
22 |
1 |
Minimum embedded payload fraction. Must be 32. |
|
23 |
1 |
Leaf payload fraction. Must be 32. |
|
24 |
4 |
File change counter. |
|
28 |
4 |
Size of the database file in pages. The "in-header database size". |
|
32 |
4 |
Page number of the first freelist trunk page. |
|
36 |
4 |
Total number of freelist pages. |
|
40 |
4 |
The schema cookie. |
|
44 |
4 |
The schema format number. Supported schema formats are 1, 2, 3, and 4. |
|
48 |
4 |
Default page cache size. |
|
52 |
4 |
The page number of the largest root b-tree page when in auto-vacuum or incremental-vacuum modes, or zero otherwise. |
|
56 |
4 |
The database text encoding. A value of 1 means UTF-8. A value of 2 means UTF-16le. A value of 3 means UTF-16be. |
|
60 |
4 |
The "user version" as read and set by the user_version pragma. |
|
64 |
4 |
True (non-zero) for incremental-vacuum mode. False (zero) otherwise. |
|
68 |
4 |
The "Application ID" set by PRAGMA application_id. |
|
72 |
20 |
Reserved for expansion. Must be zero. |
|
92 |
4 |
|
|
96 |
4 |
注:考虑到跨平台,数据库文件的字节序是大头(big-endian)的。
SQLite数据库文件格式详情参见https://www.sqlite.org/fileformat2.html。
操作系统接口抽象层是SQLite实现跨平台的关键模块,也叫虚拟文件系统(VFS),它对上层提供操作文件系统的统一接口方法,底层调用对应操作系统的接口方法实现具体的文件操作。
Pager是唯一访问底层数据库文件和日志(journal)文件的模块。它本身既不解析,也不修改页面内容,而是把数据库文件抽象成了基于页面的可随机访问的缓存。上层模块(B+-tree)总是使用Pager的提供接口方法读写数据库文件,而不会直接访问数据库文件或日志文件。
Pager的主要职责是管理页面缓存,负责从数据库读入需要的页面(为了减少内存使用,页面只在需要时读入)。此外,为了支持对上层透明的数据库读写操作,Pager还封装了其他职责,包括:事务管理、数据管理、日志管理和文件锁管理。总的来说,Pager保证了数据库存储的持久性和事务操作的原子性。如下:
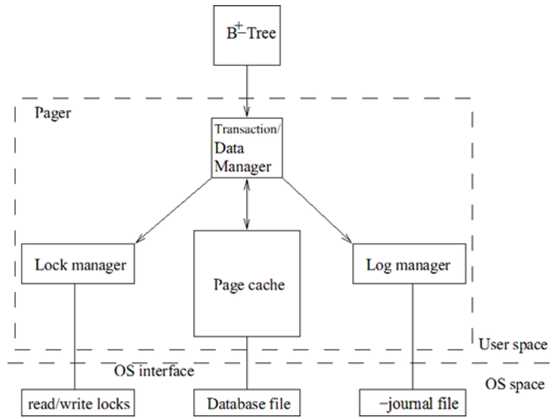
在上层模块(B+-tree)看来,数据库操作就是一系列的事务的执行,而不需要关心事务的事务执行是如何实现的,Pager会把事务执行细分为获取文件锁、记录日志、读写数据库文件等操作,下面对Pager的这几个模块的实现分别简要介绍一下。
当SQLite打开一个数据库,就会创建一个Pager来管理页面缓存,如果同一个线程打开多次数据库,只会创建一个页面缓存,如果多个线程打开同一个数据库,则每个线程会创建一个页面缓存。
Pager通过一个哈希表来管理页面缓存,哈希表开始时是空的,随着数据库的访问Pager会不断往里面插入新的页面,页面缓存的结构如下:
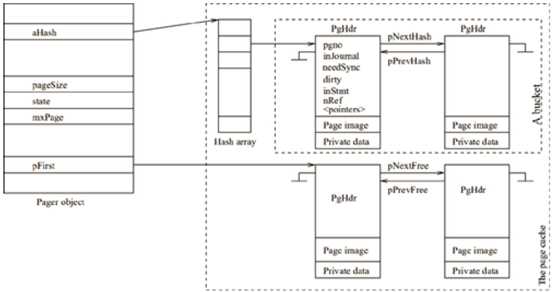
Pager管理页面缓存的原则是"按需读取"和"延迟写入"。
页面缓存中缓存的页面数量是有限的,当从数据库文件读取数据到页面缓存而没有空闲页面时,Pager会根据LRU策略回收一个页面(如果页面有脏数据,会先写入数据库文件),然后再读取数据到空闲出来的页面中。
事务管理是保证数据库同步的关键,SQLite依赖文件锁和日志来实现数据库事务的ACID属性,SQLite数据库只支持串行事务,不支持事务的嵌套和存储点(savepoint)。
SQLite执行的每一条SQL语句都必须放在事务中,读取数据操作放在读写事务(read-or-write-transaction)中,写入数据操作放在写事务(write-transaction)中。应用程序并不需要为每一条SQL语句启动一个事务,SQLite会为自动每一条独立执行的SQL语句创建对应的事务并执行,这种由SQLite自动创建事务称为原子事务,或者系统级事务。
创建系统级事务的代价是比较昂贵的,尤其是对频繁写数据库的场景,原因是以下几点:
提高读写效率的办法是使用用户级事务,即显示的启动一个事务,再执行多条SQL语句,最后提交事务。
SQLite只支持串行的事务,所以应用程序在一个数据库连接上只能执行一个事务,在事务内部再次启动事务会得到一个错误。
日志是一个信息库,用来在事务放弃(abort)、应用程序异常或者系统异常时恢复数据库数据,它只能用来回滚事务操作。SQLite为每个数据库文件使用一个日志文件,文件名前缀和数据库文件名相同并以-journal结尾。
SQLite同一时刻只允许一个写事务执行,它会在执行时创建日志文件,在提交后删除日志文件。在事务修改一个页面之前,SQLite会把正在被修改的页面写入日志文件,以备将来回复使用,日志记录的格式如下:

SQLite使用锁机制来保证事务的串行执行,它在事务开始执行时获取锁,在事务执行完毕或者放弃后释放锁。SQLite使用的是数据库级别的锁,而不是行、表或页面级别的锁。
在事务看来,数据库文件有五种锁状态:NOLOCK(未锁定),SHARED(共享只读),RESERVED(正在读取,即将写入,可以获取SHARED锁,只能有一个),PENDING(等待写入,禁止获取SHARED锁,只能有一个),EXLUSIVE(只能写入,禁止获取SHARED锁,只能有一个)。
各种锁状态的转换时序如下:
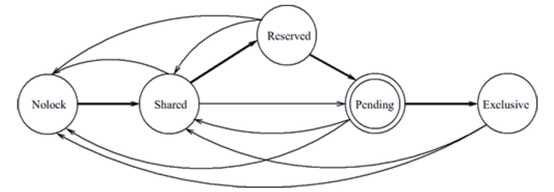
如果有多个线程同时申请RESERVED锁(它们已经持有SHARED锁),得到RESERVED锁的线程会等待其他线程释放SHARED锁才能继续获取EXLUSIVE锁,此时另一个线程如果等待获取RESERVED锁可能会引起死锁。SQLite为避免这种死锁,使用的方式是非阻塞方式获取锁,即另一个线程尝试获取几次RESERVED锁,如果获取不到就会放弃,并返回SQLITE_BUSY错误。
锁的具体实现依赖操作系统提供的文件锁接口。
在Pager提供的面向页面的数据缓存基础上,SQLite使用B+-tree来组织所有数据记录,每一张表对应一个B+-tree。而数据库表的索引则被存放在B-tree中。
B-tree也叫多路搜索树,B-tree的B代表是的是"balanced",balanced的意思就是所有叶子节点都在同一层次。B-tree的所有搜索信息和数据都可以保存在中间节点和叶子节点,它一般用于组织索引信息,使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快查找速度。
B+-tree是B-tree的变体,它的叶子节点只用来存放数据,它的中间节点只存放搜索信息和子节点指针。
这两种树结构的中间节点可以保存的子节点指针数量是可变的,且中间节点的数据遵循如下原则:
B+-tree中间节点的数据结构如下:

SQLite中的B+-tree是通过分配根节点来创建的,根节点不能重复分配,每个B+-tree都是通过其根节点的页面编号来标识的。页面编号存放在主目录表中,主目录表(master catalog table)的根节点存放在数据库文件的第1个页面中。
B+-tree的结构如下:
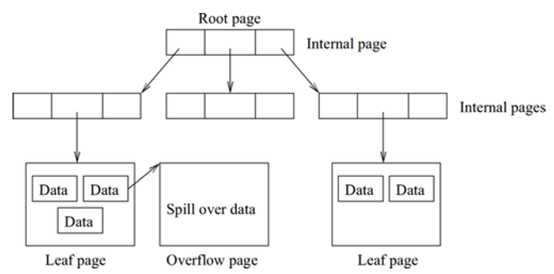
SQLite把各树节点存(包括中间节点和叶子节点)放在不同的页面中,一个页面存放一个节点。每个节点存放数据负载(payload)的空间大小是固定的,如果数据负载超出了节点的大小,那么超出的部分会存放到附加页面(overflow page)中,中间节点和叶子节点都可以有附加页面存放超出的数据负载。页面的结构如下:

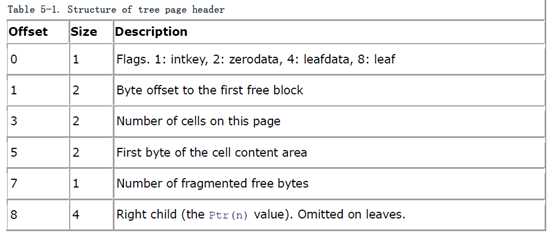
页面的header结构定义如下:
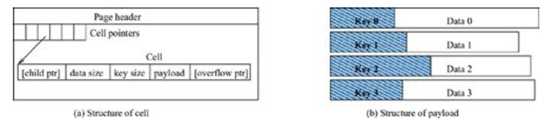
每个页面都被划分为若干个数据单元(cell),每个数据单元(cell)保存一份数据负载(或数据负载的一部分)。数据单元的header定义如下:

数据单元(cell)是大小可变的字节数组,一个数据单元(cell)保存一份数据负载(payload)。
每个页面可以存储的数据单元数量不能少于最低单元数量,也不能多余最大单元数量,它们分别由数据库文件头中的"Maximum embedded payload fraction"和"Minimum embedded payload fraction"决定,数据负载超出的部分会被放到附加页面中,多个附加页面会通过链表组织起来。
总结,SQLite会把数据库中的表和索引通过B/B+-tree组织起来,B/B+tree会在插入或删除节点时做自动调整以保持平衡,并且会自动回收和重用空闲页面。B/B+-tree提供的查询、插入和删除操作的时间复杂度是O(logn),遍历记录的时间复杂度是O(1)。
SQLite后端的顶层组件是虚拟机,它是前端和后端的接口,虚拟机在本地系统的的上层又抽象出了一个虚拟的机器。虚拟机执行的是SQLite内部定义的字节码(bytecode)编程语言,这个编程语言是为执行数据库搜索、读取和修改特别设计的。虚拟机接收和执行字节码程序,再通过B+-tree具体执行数据库操作并返回操作结果。
一个字节码(bytecode)程序是由sqlite3_stmt类型的对象封装的,由前端的命令解析器在解析SQL命令后生成。
1.《Inside SQLite》
标签:
原文地址:http://www.cnblogs.com/supersand/p/5559119.html