标签:Lucene style blog http color java 使用 os
首先将下载解压后的solr-4.9.0的目录里面找到lucene-analyzers-smartcn-4.9.0.jar文件,
将它复制到solr的应用程序里面D:\apache-tomcat-7.0.54\webapps\solr\WEB-INF\lib,
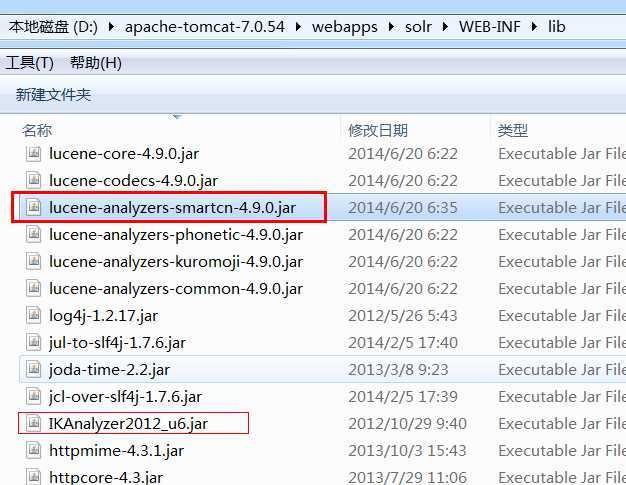
备注:网上很多文章使用IK中文分词器(IK_Analyzer2012_u6.jar)但是在solr-4.9.0版本中,我是一直没有配置成功。所以只能使用solr自带的中文分词器了。
在回到solr的应用程序目录(D:\Demos\Solr\collection1\conf)
修改schema.xml,让solr能够支持中文的分词。
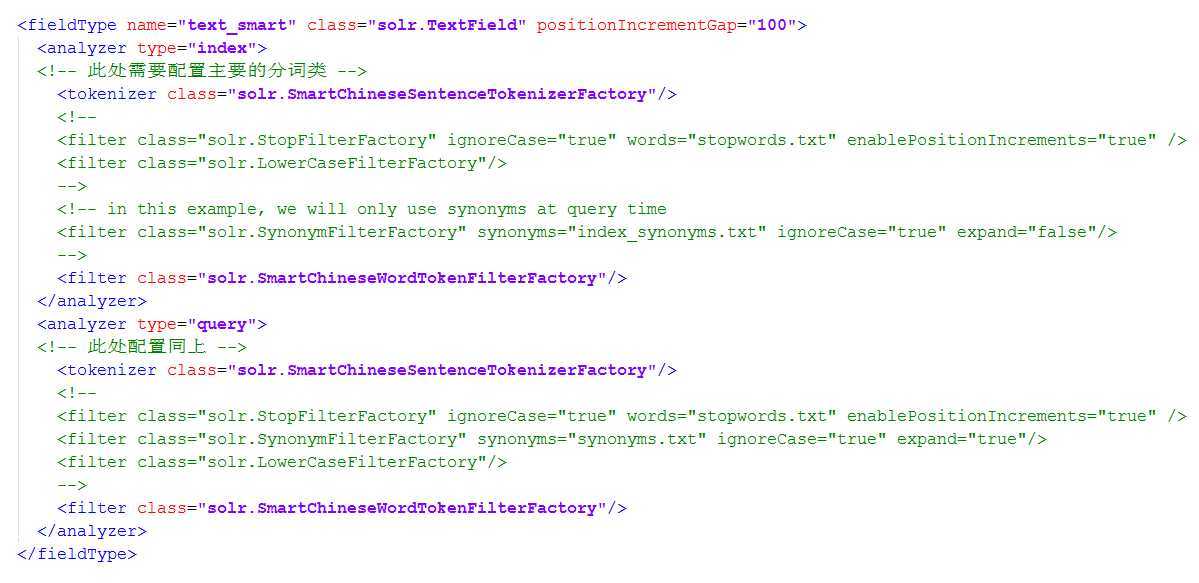

1 <fieldType name="text_smart" class="solr.TextField" positionIncrementGap="100"> 2 <analyzer type="index"> 3 <!-- 此处需要配置主要的分词类 --> 4 <tokenizer class="solr.SmartChineseSentenceTokenizerFactory"/> 5 <!-- 6 <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" /> 7 <filter class="solr.LowerCaseFilterFactory"/> 8 --> 9 <!-- in this example, we will only use synonyms at query time 10 <filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/> 11 --> 12 <filter class="solr.SmartChineseWordTokenFilterFactory"/> 13 </analyzer> 14 <analyzer type="query"> 15 <!-- 此处配置同上 --> 16 <tokenizer class="solr.SmartChineseSentenceTokenizerFactory"/> 17 <!-- 18 <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" /> 19 <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> 20 <filter class="solr.LowerCaseFilterFactory"/> 21 --> 22 <filter class="solr.SmartChineseWordTokenFilterFactory"/> 23 </analyzer> 24 </fieldType>
保存之后,重起tomcat服务器,在地址栏中输入网址:http://localhost:8080/solr/访问solr
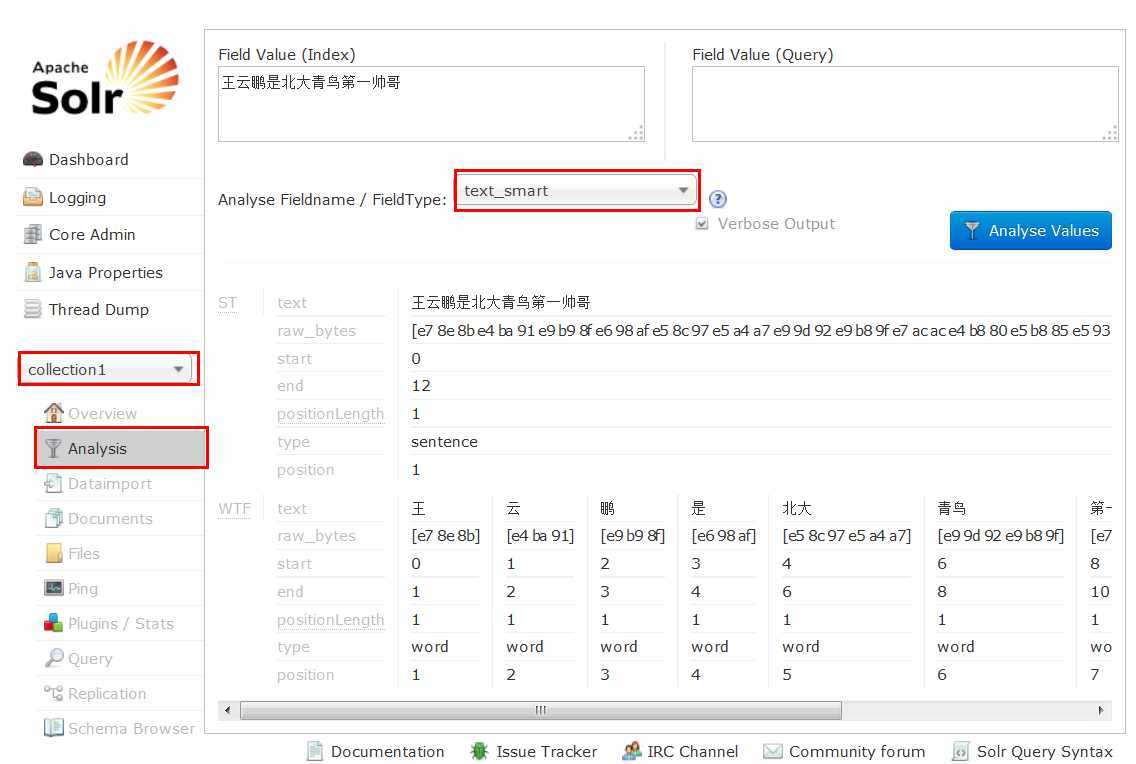
看到上面这个界面就说明配置中文分词成功啦。。。再次强调一下,java的配置真的很麻烦!希望这种图文并茂的教程在网上能够真心多一点,搞了好几天才搞定中文分词的配置。遗憾的是网上说的使用IK中文分词还是没有在solr-4.9.0中搞定。
Windows下面安装和配置Solr 4.9(三)支持中文分词器,布布扣,bubuko.com
Windows下面安装和配置Solr 4.9(三)支持中文分词器
标签:Lucene style blog http color java 使用 os
原文地址:http://www.cnblogs.com/qiyebao/p/3888181.html
