标签:
1,引言
在《Python即时网络爬虫项目: 内容提取器的定义》一文我们定义了一个通用的python网络爬虫类,期望通过这个项目节省程序员一半以上的时间。本文将用一个实例讲解怎样使用这个爬虫类。我们将爬集搜客老版论坛,是一个用Drupal做的论坛。
2,技术要点
我们在多个文章都在说:节省程序员的时间。关键是省去编写提取规则的时间,尤其是调试规则的正确性很花时间。在《1分钟快速生成用于网页内容提取的xslt》演示了怎样快速生成提取规则,接下来我们再通过GooSeeker的api接口实时获得提取规则,对网页进行抓取。本示例主要有如下两个技术要点:
3,python源代码
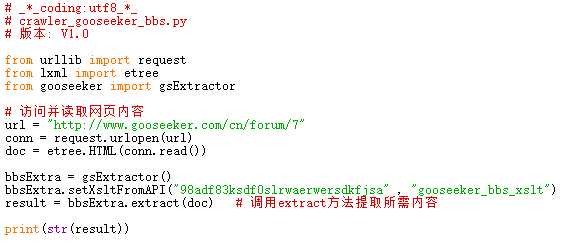
源代码下载位置请看文章末尾的GitHub源。
4,抓取结果
运行上节的代码,即可在控制台打印出提取结果,是一个xml文件,如果加上换行缩进,内容如下图:
5,相关文档
1, Python即时网络爬虫项目: 内容提取器的定义
6,集搜客GooSeeker开源代码下载源
1, GooSeeker开源Python网络爬虫GitHub源
7,文档修改历史
1,2016-06-07:V1.0
2,2016-06-07:V2.0
3,2016-06-07:V2.1,增加GitHub下载源
标签:
原文地址:http://www.cnblogs.com/gooseeker/p/5566379.html