标签:
一、对python中.pyc的理解
1).pyc文件可以理解为是python编译好的字节码文件,即只有python解释器才能读懂,类似于java中class文件
2)python运转过程:
当python程序运转时,编译的结果是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中
当程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如找到,则直接载入,否则就重复上面的过程。
总结:PyCodeObject和pyc文件关系,pyc文件其实是PyCodeObject的一种持久化方式
二、数据类型
1、数字
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-21478483548~2147483647
在64位机器上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~
long(长整形)
跟C语言不同的是,Python的长整数没有指定位宽,即:python没有限制长整数数值大小,但实际上由于机器内存的有限,我们使用的长整数数值不可能是无限大
注意:自从python2.2之后,如果整数发生溢出,python会自动将整数数据转换为长整数,所以如今长整数数据后面不加字母L也不会导致严重后果了

float(浮点型)
浮点数主要是用来处理实数,即带有小数的数字,类似C语言中的double类型,占8个字节(64位),其中52表示底,11位表示指数,剩下的一位表示一位表示符号。
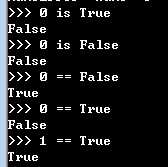
布尔值
真或假
1或0
字符串
“Hello World”
万恶的字符串拼接:
Python中的字符串在C语言中体现是为了一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空间,并且一旦开启需要修改字符串的话,就需要再次开辟空间,万恶的“+”号每次出现一次就会在内存中重新开辟一块空间。
一般字符串输出格式:
2、列表
写法:name_list = [‘dayi‘,‘daer‘,‘dasan‘] #列表必须是用[]
或者
name_list = list([‘dayi‘,‘daer‘,‘dasan‘])
AA = [32,45,6,7,8,975,3,5,65,6,62121,2,3,3,44,55,]
if 3 in AA:
num_of_ele = AA.count(3) #查找在列表中为3的元素
position_of_ele = AA.index(3) #利用索引找到为3元素的位置,并将为三的元素转换给变量position_of_ele
AA[position_of_ele] = ‘xiaoxiao‘ #对变量重新赋值
print("[%s] 3 is/are in AA,postion:[%s]"%( num_of_ele,position_of_ele))
print(AA)
for i in range(AA.count(3)): #for循环 查找列表中出现为3的元素,,
ele_index = AA.index(3) #并且找到为3元素的索引
AA[ele_index] = ‘99999‘ #再为3的元素进行重新赋值
print(AA)
#追加 extend:扩展新的列表 把两个列表合并
aa = [‘xiaoluo‘,‘lcj‘,‘ljk‘,‘62121‘]
AA.extend(aa) #将列表aa中的元素追加至列表AA列表中,如有元素有重复不影响
print(AA)
print(aa)
#reverse :翻转列表中各元素,不改变列表中的各个元素
AA.reverse()
print(AA)
#给列表排序 sort 注意:python3.0不支持列表中的字符串和数据混合排序,python2.0则支持
#先数字,在字符串,特殊符号、、、
# AA.sort()
# print(AA)
print(aa)
#pop方法:只默认删除列表中最后一位元素,也可指定列表中的元素
aa.pop()
print(aa)
aa.pop(‘lcj‘) #指定删除aa列表中的lcj元素
print(aa)
列表的基本操作:
1)索引:python中的索引又称下标(下标就是列表中各元素的排序序号,从0开始)
2)切片:即指定那些元素切换出来,不影响之前列表中各元素,即可层层切换出需要的元素[切1][切2][切2.2]

3)修改:对列表已知的元素进行修改,此时,用到变量,即是给需要修改的值进行重新赋值

3)插入(insert):,一次只能插入一个值,注意插入的符号为()

4)追加(append):一般列表最后追加一个元素

5)删除(remove):

6)步长:[::2]每隔一个元素打印
练习:
#1、找出列表中有多少个9,把他改成9999
#2、同时找出所有的34,并把他删除
name = [34,45,43,34,34,34,3,3,45,5,76,9,6,9,34,34,3,2,3,9,12]
if 9 in name:
num_of_ele = name.count(9) #统计列表中为9的元素对的个数,没找到一个自增加1
position_of_ele = name.index(9) #查找元素9的索引
name[position_of_ele] = ‘99999‘ #对列表中元素通过变量重新赋值
print(‘[%s] 9 is/are name, postion:[%s]‘%(num_of_ele,position_of_ele))
print(name)
for i in range(name.count(9)): #通过for循环查找列表中9的元素
ele_index = name.index(9) #查询列表中9的索引
name[ele_index] = ‘9999‘
print(name)
for i in range(name.count(34)): #删除列表中34的元素
#ele_index2 = name.index(34)
name.remove(34)
print(name)
三、字典(dist)无序
创建字典格式:dist = {"dd","ff","gg","hh",43}
或
dist = ({"name":“mr.wu”,‘age‘:32})
字典中可嵌套数据:
shop = {‘家电类‘:[(‘电视‘,2999),(‘冰箱‘,3999),(‘洗衣机‘,2999),(‘热水器‘,5000)]}
1)、提取字典中某一个元素:print(dict[dict的key])
2)、修改字典中某一个元素:dict[key][‘value‘] = ‘新的值‘
3)、字典中插入某一个元素:dict[key][‘插入元素‘] = ‘值’
4)、字典中删除某一元素:dict[key].pop(‘values’)
5)、获取字典中的元素:get方法。例如:dict.get[‘values’]
6)、更新字典update方法:
将dict2中的元素更新至dict1中:dict1.update(dict2)
7)、字典for循环
方法一:for k,v in dict.items(): #效率低,当数据量大时,字典转换成列表耗时慢
print(k,v)
方法二:for key in dict.items(): #在列表中查找key值,并将key中的value值打印出
print(key,dict.[key])
dictionary_lcj = {
4210221990012215234:{
‘user_name‘:‘hhh‘,
‘age‘:22,
‘Address‘: ‘北京‘
},
4210221990012215233:{
‘user_name‘:‘jjj‘,
‘age‘:22,
‘Address‘: ‘上海‘
},
4210221990012215236:{
‘user_name‘:‘kkk‘,
‘age‘:22,
‘Address‘: ‘天津‘
}
}
user2 = {
4210221990012215236: {
‘user_name‘: ‘kkk‘,
‘Address‘: ‘天津‘
}}
# print(dictionary_lcj)
# print(dictionary_lcj[4210221990012215236]) #在字典中提取某一字典数据
# dictionary_lcj[4210221990012215236][‘Address‘] = ‘广州‘ #对字典中元素进行重新赋值,注意:字典格式为{},列表格式为[]
# print(dictionary_lcj)
# dictionary_lcj[4210221990012215236][‘qq‘] = 2132323 #在字典中插入新增加元素,先提取嵌套字典,在对新增加的元素进行赋值
# print(dictionary_lcj)
# dictionary_lcj[4210221990012215236].pop(‘Address‘) #删除字典中指定的元素,注意
# print(dictionary_lcj)
#获取字典中元素:get
# dictionary_lcj.get(4210221990012215236)
# v = dictionary_lcj[4210221990012215236] #将嵌套的字典赋予一个变量,打印变量
# print(v)
#update更新字典,将user2中的元素更新至dictionary_lcj
# dictionary_lcj.update(user2)
# print(dictionary_lcj)
#items元素:把字典变成为一个元祖或者一个列表,当数据量较多时不建议把字典转化为列表,
# print(dictionary_lcj)
# print(dictionary_lcj.items())
#元素:values----》将所有字典中values值
#print(dictionary_lcj.values())
#元素:keys------》打印字典中国所有的key值,
#print(dictionary_lcj.keys())
#判断一个某一个k是否存在于字典中
print(421022199001221523623 in dictionary_lcj)
#元素:setdefault,表示在字典中如果key值存在则打印,否则key值不存在,系统默认返回一个None值,也可在指定返回的值
#print(dictionary_lcj.setdefault(421022199001221523623),‘哈哈‘) #表示当k值不存在,则返回‘哈哈’
#fromkeys:把列表中每一个值当做字典中的 一个k,并把这个值赋值给这个K,大王说这是一个抗,还没说是啥抗
# print(dict.fromkeys([1,2,3,4],‘lcj‘)) #通过默认的字典调用者个列表
# print(dictionary_lcj.fromkeys([1,2,3,4],‘lcj‘))
# #popitem:随机删除字典中元素,当数据量较大时明显,python中一般不建议使用随机方法
# print(dictionary_lcj.popitem())
# print(dictionary_lcj)
#字典for循环
for k ,v in dictionary_lcj.items(): #效率低,有一个字典转换为一个列表的过程
print(k,v)
for key in dictionary_lcj: #查找dictionary_lcj中key值,再讲key中的值打印出
print(key,dictionary_lcj[key])
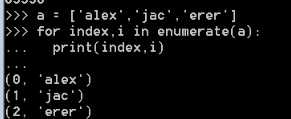
8、枚举方法:
方法:numerate,将数组a中的元素赋值为一个元祖,并把元祖的下标打印
四、元组
元组为不可变得列表: tuple一旦初始化就不能修改
ages = (12,33,22,45,67) 或 ages = tuple((21,32,43,54,74))
标签:
原文地址:http://www.cnblogs.com/lcj0703/p/5500010.html