标签:
一: 作用域
对于变量的作用域,只要内存中存在,该变量就可以使用。
二:三元运算
name = 值1 if 条件 else 值2
如果条件为真:result = 值1
如果条件为假:result = 值2
方式一:
name = ‘ccc‘
if 1==1:
name = ‘sb‘
else:
name = ‘sb‘
方式二:
name = ‘sb‘ if 1==1 else ‘2b‘
实例:
name = raw_input(‘your name: ‘)
reslut = ‘sb‘ if name == ‘alex‘ else ‘nice‘
print reslut
三:进制
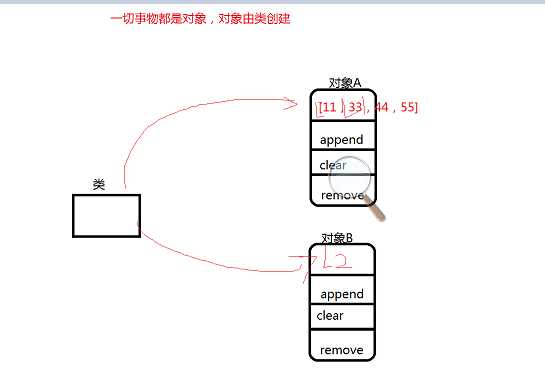
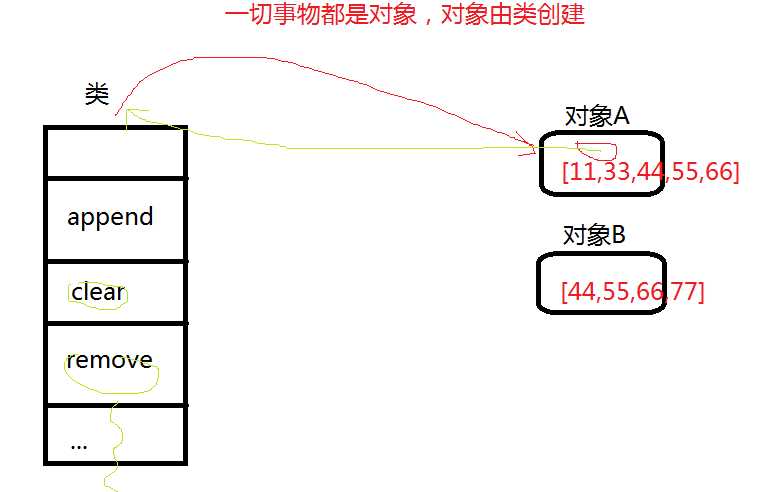
python的一切事物都是对象。对象是基于类创建的。
查看list这个类有哪些方法
dir(类型名)
help(类型名)
把详细的内容显示出来
help(类型名.功能名)
通过type()查看对象的类型
实例:
print dir(list)
print help(list)
print help(list.append)
类中的方法分为带下划线和不带下划线的。
带下划线的是内置方法,可能有多种执行方法;
不带下划线的是非内置方法,只有一种执行方法;对象.方法
对于上面那句话的理解
一:数字
i = 10
i1 = int(10)
i2 = int("10",2)
后面的数字表示进制,前面的是进制下对应的值
下面是int中的部分方法

1 #比较大小 2 3 age = 18 4 print age.__cmp__(19) 5 print age.__cmp__(18) 6 print age.__cmp__(17) 7 print cmp(18,19) 8 #取绝对值 9 a = -9 10 print a.__abs__() 11 #相加 12 b = 9 13 print b.__add__(8) 14 #强制生成一个元组 15 c = 7 16 print c.__coerce__(6) 17 #取商和余数,计算分页使用 18 d = 98 19 print d.__divmod__(10) 20 #取商 21 e = 9 22 print e.__div__(3) 23 #转换为浮点类型 24 f = 7 25 f1 = f.__float__() 26 27 print type(f1) 28 29 #哈希值用于在字典中快速找到他的键
二:字符串(str)
1 str_1 = "alex"
2 str_2 = str("alex")
3 #首字母变大写
4
5 print str_2.capitalize()
6
7 #将内容显示在中间;总长度是20;以*填充
8
9 print str_2.center(20)
10 print str_2.center(20,"*")
11 #子序列个数;d的个数;从0-10的位置找
12 name = "dfghjdfghjdfghdfghdfg"
13 print name.count(‘d‘)
14 print name.count(‘d‘,0,10)
###############################################################
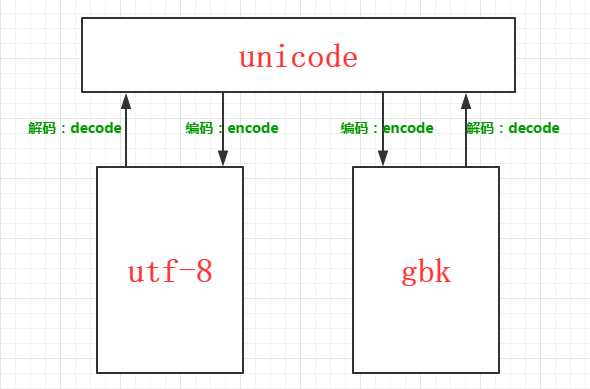
编码的转化 gbk==>unicode==>utf-8
encode:编码
decode:解码
1 >>> ‘我靠‘ 2 3 ‘\xce\xd2\xbf\xbf‘ 4 >>> str1 = ‘\xce\xd2\xbf\xbf‘ 5 >>> print str1 6 我靠 7 >>> str1.decode(‘gbk‘) 8 u‘\u6211\u9760‘ 9 >>> str1.decode(‘gbk‘).encode(‘utf-8‘) 10 ‘\xe6\x88\x91\xe9\x9d\xa0‘ 11 >>> print str1.decode(‘gbk‘).encode(‘utf-8‘) 12 13 鎴戦潬
编码解释
###############################################################
1 #以什么结尾;是在返回true
2 str_1 = "alex"
3 print str_1.endswith(‘x‘)
4 #将tab转换成空格,默认一个tab转换成8个空格;转换成1个
5 name = ‘ale x‘
6 print name.expandtabs()
7 print name.expandtabs(1)
8 #寻找子序列的位置;-1表示没有找到
9 print str_1.find(‘e‘)
10 print str_1.find(‘le‘)
11 print str_1.find(‘s‘)
12 #找到第一个
13 str2 = "alexa"
14 print str2.find(‘a‘)
15 #字符串格式化
16 ##按照下标(有序的)
17 name = "i am {0},age {1}"
18 print name.format("cgt",24)
19 ##使用列表的方式
20 name_list = ["cgt",24]
21 print name.format(*name_list)
22 ##按照名称(无序的)
23 name = "i am {aa},age {bb}"
24 print name.format(aa="cgt",bb=24)
25 print name.format(bb=24,aa="cgt")
26 ##使用字典的方式
27 name_dict = {‘aa‘:‘cgt‘,‘bb‘:24}
28 print name.format(**name_dict)
29 #使用index来查找;找不到就报错,而find是返回-1
30 name = "alex"
31 print name.index(‘a‘)
32 #是否是数字和字母
33 print name.isalnum()
34 #是否是字母
35 print name.isalpha()
36 #是否是数字
37 print name.isalnum()
38 #是否是小写
39 print name.islower()
40 #是否是空格
41 print name.isspace()
42 #是不是标题istitle(标题的格式就是单词的首字母大写)
43 print name.istitle()
44 #设置为标题的格式title
45 print name.title()
46 #是不是大写isupper
47 print name.isupper()
48 #连接join
49 print ‘__‘.join(name)
50 #内容左对齐ljust(宽度,填充)
51 print name.ljust(20,‘*‘)
52 #内容右对齐rjust(宽度,填充)
53 print name.ljust(20,‘&‘)
54 #变成小写lower
55 print name.lower()
56 #变成大写upper
57 print name.upper()
58 #大小写交换swapcase
59 name = "AleX"
60 print name.swapcase()
61 #移除左边的空白lstrip
62 print name.lstrip()
63 #分隔partition(前,中,后)
64 name = "hello cgt"
65 print name.partition("ll")
66 #替换replace(old,new)
67 name = ‘alex‘
68 print name.replace(‘a‘,‘b‘)
69 #从右边开始找rfind
70 print name.rfind(‘e‘)
71 #以什么开始
72 print name.startswith(‘a‘)
三:列表(list)
1 #定义一个列表 2 3 li = [11,22,33,11] 4 #append添加 5 print li.append(12) 6 #count出现的次数 7 print li.count(11) 8 #extend扩展 9 print li.extend([‘ccc‘,‘ggg‘]) 10 #index返回第一个匹配的值的下标,不存在,报错 11 12 print li.index(11) 13 14 #insert插入,在指定位置插入(位置,内容) 15 16 li.insert(4,‘aa‘) 17 18 #pop删除并返回指定下标的值,如果没有指定在返回最后一个的值 19 li = [11,22,33,11,‘alex‘] 20 name = li.pop(11) 21 name2 = li.pop() 22 #remove移除;指定值,不是指定下标。只删除第一个的值 23 24 li.remove(11) 25 26 #reverse反转列表 27 28 li.reverse() 29 30 #sort排序 31 32 li.sort()
四:元组
元组的元素不能被修改,但是元组的元素的元素是可以修改的
count
index
五:字典
#判断元素的类型是不是某种类型
#例子
#type(name) is list
1 dic = {‘k1‘:‘aa‘,‘k2‘:‘bb‘,‘k3‘:‘cc‘}
2 #清除内容
3 #a = dic.clear()
4 #print a
5 #根据key获取值
6 print dic[‘k1‘]
7 print dic.get(‘k1‘)
8 #如果key值不存在,不使用get的方式会报错;使用get的方式,可以实现设置默认的值,如果这个key存在,则不打印默认值
9 #print dic[‘k4‘]
10 print dic.get(‘k4‘,‘ok‘)
11 #判断是否有key
12 print dic.has_key(‘k5‘)
13 #所有项的列表形式
14 print dic.items()
15 #所有key的列表
16 print dic.keys()
17 ##判断是否有key
18 for k in dic:
19 print k,dic[k]
20 #获取显示出来并在字典中移除
21 ‘‘‘
22 print dic.pop(‘k1‘) #指定key删除
23 print dic.popitem() #随机的删除
24
25 ‘‘‘
26
27 dic = {‘k1‘:‘aa‘,‘k2‘:‘bb‘,‘k3‘:‘cc‘}
28 #清除内容
29 #a = dic.clear()
30 #print a
31 #根据key获取值
32 print dic[‘k1‘]
33 print dic.get(‘k1‘)
34 #如果key值不存在,不使用get的方式会报错;使用get的方式,可以实现设置默认的值,如果这个key存在,则不打印默认值
35 #print dic[‘k4‘]
36 print dic.get(‘k4‘,‘ok‘)
37 #判断是否有key
38 print dic.has_key(‘k5‘)
39 #所有项的列表形式
40 print dic.items()
41 #所有key的列表
42 print dic.keys()
43 ##判断是否有key
44 for k in dic:
45 print k,dic[k]
46 #获取显示出来并在字典中移除
47 ‘‘‘
48 print dic.pop(‘k1‘) #指定key删除
49 print dic.popitem() #随机的删除
50
51 ‘‘‘
52
53 #copy:浅拷贝和深拷贝、别名的区别
54
55 >>> dic
56 {‘k3‘: ‘cc‘, ‘k2‘: ‘bb‘, ‘k1‘: ‘aa‘}
57 >>> copy_dic = dic.copy()
58 >>> copy_dic
59 {‘k3‘: ‘cc‘, ‘k2‘: ‘bb‘, ‘k1‘: ‘aa‘}
60 >>> second_dic = dic
61 >>> second_dic
62 {‘k3‘: ‘cc‘, ‘k2‘: ‘bb‘, ‘k1‘: ‘aa‘}
63 >>> dic
64 {‘k3‘: ‘cc‘, ‘k2‘: ‘bb‘, ‘k1‘: ‘aa‘}
65 >>> second_dic
66 {‘k3‘: ‘cc‘, ‘k2‘: ‘bb‘, ‘k1‘: ‘aa‘}
67 >>> copy_dic
68 {‘k3‘: ‘cc‘, ‘k2‘: ‘bb‘, ‘k1‘: ‘aa‘}
69 >>> dic[‘k4‘]=‘dd‘
70 >>> dic
71 {‘k3‘: ‘cc‘, ‘k2‘: ‘bb‘, ‘k1‘: ‘aa‘, ‘k4‘: ‘dd‘}
72 >>> second_dic
73 {‘k3‘: ‘cc‘, ‘k2‘: ‘bb‘, ‘k1‘: ‘aa‘, ‘k4‘: ‘dd‘}
74 >>> copy_dic
75
76 {‘k3‘: ‘cc‘, ‘k2‘: ‘bb‘, ‘k1‘: ‘aa‘}
六:集合(是一个无序且不重复的元素集合)
1 >>> a = range(5,10) 2 >>> b = range(7,12) 3 >>> a 4 [5, 6, 7, 8, 9] 5 >>> b 6 7 [7, 8, 9, 10, 11] 8 9 #将a列表set成集合 10 11 >>> c = set(a) 12 >>> c 13 14 set([8, 9, 5, 6, 7]) 15 16 #在a列表追加一个 6,重新set后只显示一个6 17 18 >>> a.append(6) 19 >>> a 20 [5, 6, 7, 8, 9, 6] 21 >>> c = set(a) 22 >>> c 23 set([8, 9, 5, 6, 7]) 24 >>> d = set(b) 25 >>> c,d 26 27 (set([8, 9, 5, 6, 7]), set([8, 9, 10, 11, 7])) 28 29 #取交集 30 31 >>> c & d 32 33 set([8, 9, 7]) 34 35 #取合集 36 37 >>> c | d 38 39 set([5, 6, 7, 8, 9, 10, 11]) 40 41 #取交集的补集 42 43 >>> c ^ d 44 45 set([5, 6, 10, 11]) 46 47 #取差集 48 49 >>> c - d 50 51 set([5, 6]) 52 53 #是否是子集 54 55 >>> e = set([8,9]) 56 >>> e 57 set([8, 9]) 58 >>> e.issubset(d) 59 60 True 61 62 #是否是父集 63 64 >>> e.issuperset(d) 65 False 66 >>> e 67 set([8, 9]) 68 >>> e.pop() 69 8 70 >>> e 71 set([9]) 72 >>> d 73 set([8, 9, 10, 11, 7]) 74 >>> d.remove(9) 75 >>> d 76 set([8, 10, 11, 7]) 77 >>> e 78 set([9]) 79 >>> d 80 set([8, 10, 11, 7]) 81 >>> d.update(e) 82 >>> d 83 84 set([7, 8, 9, 10, 11])
七:时间
有三种形式:时间戳、格式化
1 import time 2 print time.time() 3 #以时间戳的形式存在 4 #1445324355.64 5 print time.gmtime() 6 #time.struct_time(tm_year=2015, tm_mon=10, tm_mday=20, tm_hour=6, tm_min=59, tm_sec=15, tm_wday=1, tm_yday=293, tm_isdst=0) 7 print time.strftime(‘%Y-%m-%d %H:%M:%S‘) 8 #自定义格式 9 10 #2015-10-20 15:00:52 11 12 print time.strptime(‘2014-11-11‘, ‘%Y-%m-%d‘) 13 #将格式化的时间转成一个结构化的时间 14 15 #time.struct_time(tm_year=2014, tm_mon=11, tm_mday=11, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=1, tm_yday=315, tm_isdst=-1) 16 17 print time.localtime() 18 #是一个结构化的时间
标签:
原文地址:http://www.cnblogs.com/kevingrace/p/5569749.html