标签:
Python的字符串格式化有两种方式: 百分号方式、format方式,由于百分号的方式相对来说比较老,在社区里讨论format方式有望取代百分号方式,下面我们分别介绍一下这两种方式:
用法:%[(name)][flags][width].[precision]typecode
(name):可选,用于选择指定的key
flags:可选,可提供选择的值有
|
1
2
3
4
|
+ #右对齐;正数前加正号,负数前加负号 - #左对齐;正数前无符号,负数前加负号空格 #右对齐;正数前加空格,负数前加负号 0 #右对齐;正数前无符号,负数前加负号;用0填充空白处 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
s #获取传入对象的__str__方法的返回值,并将其格式化到指定位置r #获取传入对象的__repr__方法的返回值,并将其格式化到指定位置c #整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置o #将整数转换成 八 进制表示,并将其格式化到指定位置x #将整数转换成十六进制表示,并将其格式化到指定位置d #将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置e #将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)E #将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)f #将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)F #同上g #自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)G #自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)% #当字符串中存在格式化标志时,需要用 %%表示一个百分号注:Python中百分号格式化是不存在自动将整数转换成二进制表示的方式 |
百分号具体使用方法:
|
1
2
3
4
|
msg=(‘hello %s,age %d‘)%(‘jack‘,18) #根据顺序进行传值msg = ("my name %(name)s,age %(age)d") % ({"name":"jack","age":18}) #根据定义的名字进行传值msg=‘age %.2f‘%(1.232323) #保留两位小数点msg=‘age %.2f %%‘%(1.23232) #这里必须注意要添加两个%号,输出百分比 |
用法:[[fill]align][sign][#][0][width][,][.precision][type]
fill:空白处填充的字符
align:对齐方式(需配合width使用)
|
1
2
3
4
|
< #内容左对齐> #内容右对齐(默认)= #内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效,符号+填充符+数字^ #内容居中 |
|
1
2
3
|
+ #正号加正,负号加负- #正号不变,负号加负空格 #正号加空格,负号加负 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#传入” 字符串类型 “的参数 s #格式化字符串类型数据 空白 #未指定类型,则默认是None,同s#传入“ 整数类型 ”的参数 b #将10进制整数自动转换成2进制表示然后格式化 c #将10进制整数自动转换为其对应的unicode字符 d #十进制整数 o #将10进制整数自动转换成8进制表示然后格式化; x #将10进制整数自动转换成16进制表示然后格式化(小写x) X #将10进制整数自动转换成16进制表示然后格式化(大写X)#传入“ 浮点型或小数类型 ”的参数 e #转换为科学计数法(小写e)表示,然后格式化; E #转换为科学计数法(大写E)表示,然后格式化; f #转换为浮点型(默认小数点后保留6位)表示,然后格式化; F #转换为浮点型(默认小数点后保留6位)表示,然后格式化; g #自动在e和f中切换 G #自动在E和F中切换 % #显示百分比(默认显示小数点后6位) |
format具体使用用法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
tp1="i am {},age {},{}".format(‘six‘,18,‘jack‘) #可以接受任意的数值类型tp1="i am {},age {},{}".format(*[‘six‘,18,‘jack‘]) #加*将列表里的值一个一个传进去tp1="i am {0},age {1},{0}".format(‘six‘,18,‘jack‘) #根据下标进行赋值tp1="i am {name},age {age},{name}".format(name=‘jack‘,age=18) #根据定义的名字进行传值
#format是字符串的一个方法,也就是一个函数,函数在传入字典是需要在前面加上**,类似**kwargstp1="i am {:s},age {:d},{:f}".format(‘jack‘,18,1.34) #定义为:s,:d,:f,这里的值必须是字符串,数值,和浮点数tp1="i am {name:s},age {age:d},{a:f}".format(**{‘name‘:‘jack‘,‘age‘:18,‘a‘:2.343}) #定义名字tp1="i am {name:s},age {age:d},{a:.2%}".format(**{‘name‘:‘jack‘,‘age‘:19,‘a‘:0.21312}) #a:.2% 保留两位小数点,并且转换成百分比tp1=‘{:#^20s}‘.format(‘购物中心‘) #字符串居中 |
格式化操作就介绍到这里,更多的操作请参考官网:https://docs.python.org/3/library/string.html
先通过一个小例子来认识一下递归的用法:
|
1
2
3
4
5
6
7
8
9
10
|
def func(n): n +=1 #传入一个值自加1 if n >= 4: #如果这个值大于等于4时,结束函数返回end return ‘end‘ return func(n) ret =func(1)print(ret)#结果:end |
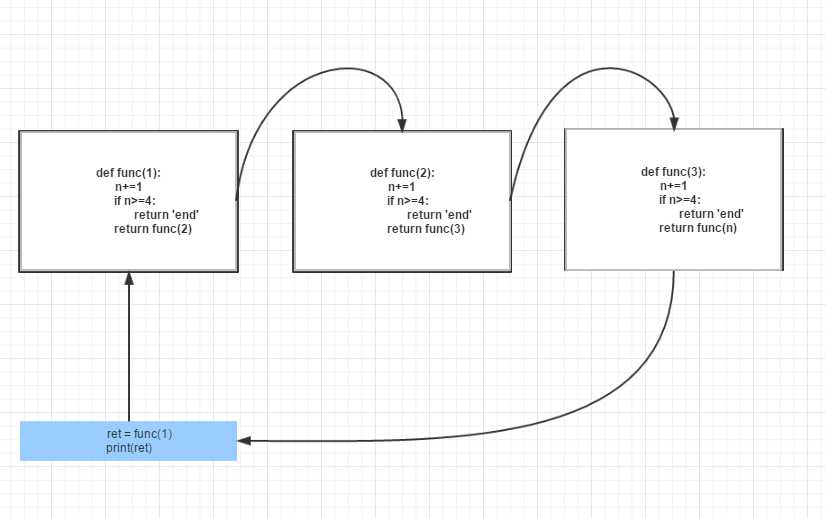
图画的丑了一些,根据这个图我们来介绍一下递归,首先给函数赋值为1,当1进入函数后自加1,这是n=2,不满足n>=4的条件,将n=2传入return func()
进入第二次判断,同样没有满足条件,今天第三次判断这是n=3+1满足条件直接返回end,总结就是条件不满足就一直一层一层到递归下去,知道条件成立。
下面再举一个例子,咱们来算一下数字的阶乘:
|
1
2
3
4
5
6
7
8
9
|
def jiecheng(n): if n==1 or n==0: return 1 return n*jiecheng(n-1)ret=jiecheng(5)print(ret)结果:120 |
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,知道所有元素被访问完结束。迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退。
迭代器的优点就是不要求事先准备好整个迭代过程中所有的元素,迭代器仅仅在迭代到某个元素时才计算元素,而在这之前或之后,元素可以不存在或者被销毁,这个特点使得它特别适合用于遍历一些巨大的或者无限的集合,比如几个G的文件
特点:
访问者不需要关心迭代器内部的结构,仅需要通过next()方法不断去取一下内容
不能随机访问集合中的某个值,只能从头到尾依次访问
访问到一半时不能后退
便于循环比较大的数据集合,节省内存?
|
1
2
3
4
5
6
7
8
9
|
li =[11,22,33,44]a=filter(lambda x:x>22,li)print(a)结果:<filter object at 0x0000024AACFD52E8> #迭代器print(a.__next__())33 |
一个函数调用时返回一个迭代器,那这个函数就叫生成器(generator);如果函数中包含yield语法,那这个函数就会变成生成器。
|
1
2
3
4
5
6
7
8
|
def func(): yield 1 #有yield的函数为生成器 yield 2 yield 3ret = func()for i in ret: #进入函数找到yield,获取yield后面的数据 print(i) |
|
1
2
3
4
5
6
7
8
9
10
11
|
def myrange(arg): #自己定义一个生成器接收一个参数,初始值为1,循环加值 start=1 while True: if start >arg: return yield start start += 1ret=myrange(3)for i in ret: print(i) |
通过一个登录接口的例子,学习一下双层装饰器:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
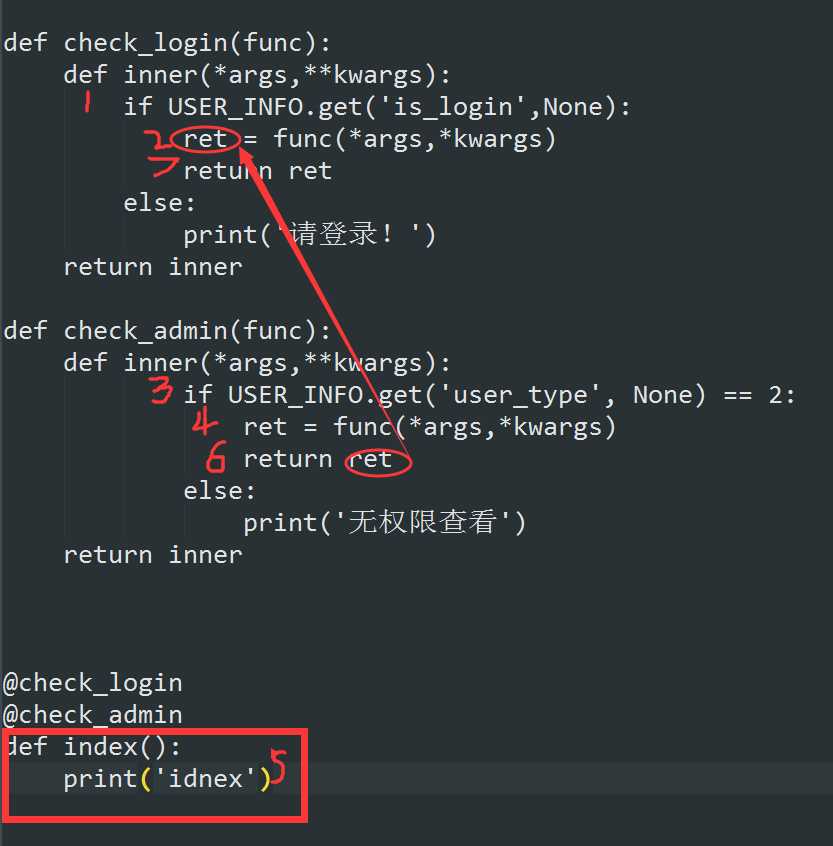
#!/usr/bin/env python# -*- coding: utf-8 -*-#Author:HaiFeng DiUSER_INFO={}def check_login(func): def inner(*args,**kwargs): if USER_INFO.get(‘is_login‘,None): ret = func(*args,*kwargs) return ret else: print(‘请登录!‘) return innerdef check_admin(func): def inner(*args,**kwargs): if USER_INFO.get(‘user_type‘, None) == 2: ret = func(*args,*kwargs) return ret else: print(‘无权限查看‘) return inner@check_login@check_admindef index(): print(‘idnex‘)@check_logindef home(): print(‘home‘)def login(): name = input(‘请输入用户名:‘) if name == ‘admin‘: USER_INFO[‘is_login‘] = True USER_INFO[‘user_type‘] = 2 else: USER_INFO[‘is_login‘] = True USER_INFO[‘user_type‘] = 1def main(): while True: inp = input(‘1、登录;2、查看信息;3、超级管理员 \n >>>‘) if inp == ‘1‘: login() elif inp ==‘2‘: home() elif inp ==‘3‘: index()main() |
下面解释一下什么的程序执行步骤:
根据Python解释器从上而下的原则,先将check_login、check_admin两个函数写到内存中,然后解释器会先解释check_admin和index(),这时index已经是新的函数体为check_admin里的inner()函数,
然后又在外面加了一层装饰器check_login,这时check_login函数里的参数func是新函数index(即:check_admin里的inner),程序执行过程请看下图:
?这次拾遗主要介绍了,字符串的高级用法,递归,生成器、迭代器和双层装饰器,后续会继续有一些类似的拾遗博客,主要是对一些扩展知识点的整理。
标签:
原文地址:http://www.cnblogs.com/phennry/p/5572578.html