标签:
《机器学习实战》第三章 决策树
-------------------------------------
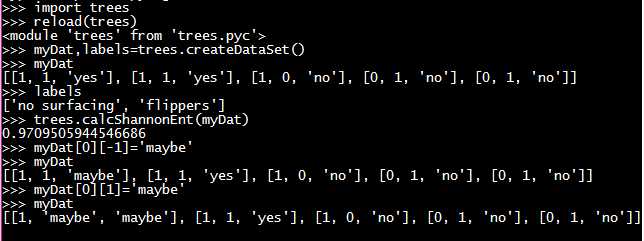
#1 trees.py 计算给定数据集的香农熵
-------------------------------------
1 from math import log 2 3 # 计算给定数据集的香农熵 4 def calcShannonEnt(dataSet): 5 numEnres = len(dataSet) 6 labelCoounts = {} 7 for featVec in dataSet: 8 #为所有可能分类创建字典 9 currentLabel = featVec[-1] 10 if currentLabel not in labelCoounts.keys(): 11 labelCoounts[currentLabel] = 0 12 labelCoounts[currentLabel] += 1 13 shannonEnt = 0.0 14 for key in labelCoounts: 15 prob = float(labelCoounts[key]) / numEnres 16 shannonEnt -= prob * log(prob, 2) #以2为底求对数 17 return shannonEnt 18 19 #用来 得到简单鱼类鉴定数据集 20 def createDataSet(): 21 dataSet = [[1, 1, ‘yes‘], 22 [1, 1, ‘yes‘], 23 [1, 0, ‘no‘], 24 [0, 1, ‘no‘], 25 [0, 1, ‘no‘]] 26 labels = [‘no surfacing‘, ‘flippers‘] 27 return dataSet, labels
-------------------------------------
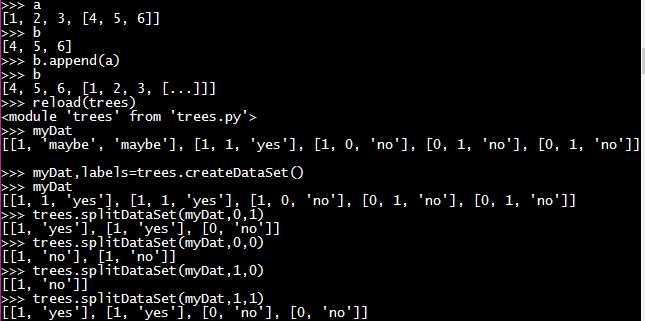
#2 trees.py 划分数据集 待划分的数据集、划分数据集的待征、需要返回的特征的值
-------------------------------------
1 # 划分数据集 待划分的数据集、划分数据集的待征、需要返回的特征的值 2 def splitDataSet(dataSet, axis, value): 3 retDataSet = [] 4 for featVec in dataSet: 5 if featVec[axis] == value: 6 reducedFeatVec = featVec[:axis] 7 reducedFeatVec.extend(featVec[axis + 1:]) 8 retDataSet.append(reducedFeatVec) 9 return retDataSet
-------------------------------------
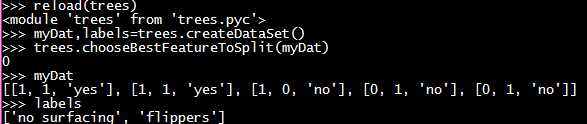
#3 trees.py 选择最好的数据集划分方式
-------------------------------------
1 # 划分数据集 待划分的数据集、划分数据集的待征、需要返回的特征的值 2 def splitDataSet(dataSet, axis, value): 3 retDataSet = [] 4 for featVec in dataSet: 5 if featVec[axis] == value: 6 reducedFeatVec = featVec[:axis] 7 reducedFeatVec.extend(featVec[axis + 1:]) 8 retDataSet.append(reducedFeatVec) 9 return retDataSet 10 11 12 # 选择最好的数据集划分方式 13 def chooseBestFeatureToSplit(dataSet): 14 numFeatures = len(dataSet[0]) - 1 15 baseEntropy = calcShannonEnt(dataSet) 16 bestInfoGain = 0.0; 17 bestFeature = -1; 18 for i in range(numFeatures): 19 featList = [example[i] for example in dataSet] 20 uniqueVals = set(featList) 21 newEntropy = 0.0; 22 23 for value in uniqueVals: 24 subDataSet = splitDataSet(dataSet, i, value) 25 prob = len(subDataSet) / float(len(dataSet)) 26 newEntropy += prob * calcShannonEnt(subDataSet) 27 28 infoGain = baseEntropy - newEntropy 29 30 if (infoGain > bestInfoGain): 31 bestInfoGain = infoGain 32 bestFeature = i 33 34 return bestFeature
-------------------------------------
#4 trees.py 创建树的函数代码 两个参数:数据集、标签列表
-------------------------------------
1 import operator 2 3 # 创建树的函数代码 两个参数:数据集、标签列表 4 def createTree(dataSet, labels): 5 classList = [example[-1] for example in dataSet] 6 7 # 类别完全相同则停止继续划分 8 if classList.count(classList[0]) == len(classList): 9 return classList[0] 10 11 # 遍历完所有特征时返回出现次数最多的 12 if len(dataSet[0]) == 1: 13 return majorityCnt(classList) 14 15 bestFeat = chooseBestFeatureToSplit(dataSet) 16 bestFeatLabel = labels[bestFeat] 17 myTree = {bestFeatLabel: {}} 18 del (labels[bestFeat]) 19 20 # 得到列表包含的所有属性值 21 featValues = [example[bestFeat] for example in dataSet] 22 uniqueVals = set(featValues) 23 24 # 遍历当前选择特征包含的所有属性值,在每个数据集划分上递归调用函数createTree() 25 for value in uniqueVals: 26 subLabels = labels[:] 27 myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels) 28 29 return myTree

标签:
原文地址:http://www.cnblogs.com/sows/p/5573618.html