标签:
大多数的字符和字母都为普通字符
在正则里,有其特殊的功能的字符称为元字符,如:. ^ $ * + ? {} | () \
import re strs = ‘ji154\n651jia*-‘ m = re.findall(‘.‘,strs) #findall把所有匹配成功的对象装一个列表返回 print(m) #结果为:[‘j‘, ‘i‘, ‘1‘, ‘5‘, ‘4‘, ‘6‘, ‘5‘, ‘1‘, ‘j‘, ‘i‘, ‘a‘, ‘*‘, ‘-‘]
import re
strs = ‘alex123‘
m = re.search(‘^alex‘,strs) #匹配成功返回match对象,否则返回None
if m:
print(m.group()) #alex
import re
strs = ‘123alex‘
m = re.search(‘alex$‘,strs)
if m:
print(m.group()) #alex
import re
str1 = ‘alexxxxx‘
str2 = ‘alex‘
str3 = ‘ale‘
m1 = re.match(‘alex*‘,str1) #match从头匹配,匹配成功返回match对象,否则返回None
if m1:
print(m1.group()) #alexxxxx
m2 = re.match(‘alex*‘,str2)
if m2:
print(m2.group()) #alex
m3 = re.match(‘alex*‘,str3)
if m3:
print(m3.group()) #ale
import re
str1 = ‘alexxxxx‘
str2 = ‘alex‘
str3 = ‘ale‘
m1 = re.match(‘alex+‘,str1)
if m1:
print(m1.group()) #alexxxxx
m2 = re.match(‘alex+‘,str2)
if m2:
print(m2.group()) #alex
m3 = re.match(‘alex+‘,str3)
if m3: #条件不成立
print(m3.group())
print(m3) #None
import re
str1 = ‘alexxxx‘
str2 = ‘alex‘
str3 = ‘ale‘
m1 = re.match(‘alex?‘,str1)
if m1:
print(m1.group()) #alex
m2 = re.match(‘alex?‘,str2)
if m2:
print(m2.group()) #alex
m3 = re.match(‘alex?‘,str3)
if m3:
print(m3.group()) #ale
import re
str1 = ‘alexxx‘
str2 = ‘alexxxxx‘
m1 = re.search(‘alex{3}‘,str1)
if m1:
print(m1.group()) #alexxx
m2 = re.search(‘alex{3,5}‘,str1)
if m2:
print(m2.group()) #alexxx
m3 = re.search(‘alex{3,5}‘,str2)
if m3:
print(m3.group()) #alexxxxx
import re
str1 = ‘jing264-*4*df‘
m1 = re.search(‘[a-z]‘,str1) #search从左往右匹配,匹配成功就不再往后匹配
if m1:
print(m1.group()) #j
m2 = re.findall(‘[a-z]‘,str1)
print(m2) #[‘j‘, ‘i‘, ‘n‘, ‘g‘, ‘d‘, ‘f‘]
元字符在字符集中会失去其特有功能,回归本性,除-,^,\
import re m = re.findall(‘[^1-9]‘,‘ww32sd8l‘) #在字符集里,^表示非,在这里就是非数字 print(m) #[‘w‘, ‘w‘, ‘s‘, ‘d‘, ‘l‘]
import re m = re.findall(‘[*\^]‘,‘kdf*nd15^1j5‘) #匹配星号或折号 print(m) #[‘*‘, ‘^‘]
import re
m = re.findall(‘(ab)+‘,‘abababab156712‘) #findall对组有优先获取权
print(m) #[‘ab‘]
m2 = re.search(‘(ab)+‘,‘abababab156712‘)
if m2:
print(m2.group()) #abababab
import re m = re.findall(‘(abc)|(1)|(\n)‘,‘jicabc21\n1‘) print(m) #[(‘abc‘, ‘‘, ‘‘), (‘‘, ‘1‘, ‘‘), (‘‘, ‘‘, ‘\n‘), (‘‘, ‘1‘, ‘‘)] m = re.findall(‘(\d)+‘,‘abcabc21ji‘) print(m) #[‘1‘] m = re.findall(‘(abc)‘,‘jicabc21\n1‘,re.M) print(m) #[‘abc‘]
正则的\与python里的\--当正则规则与python规则相冲突时
#匹配字符里的 import re m = re.findall(‘\\\\‘,‘abc\com‘) print(m) #[‘\\‘] m2 = re.findall(r‘\\‘,‘abc\com‘) print(m2) #[‘\\‘]
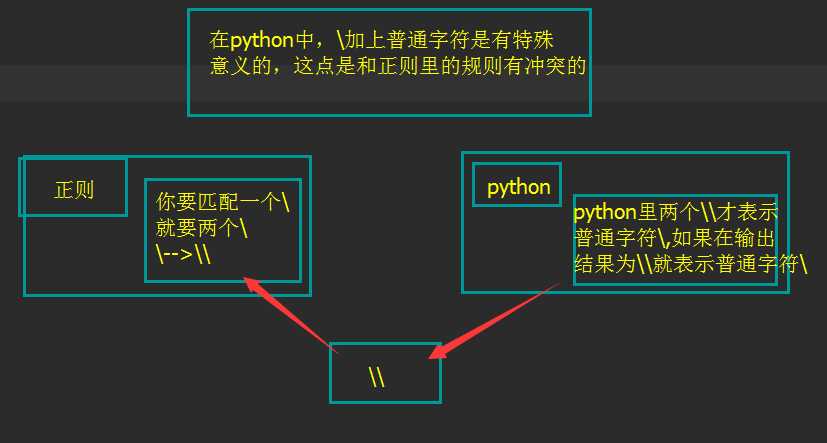
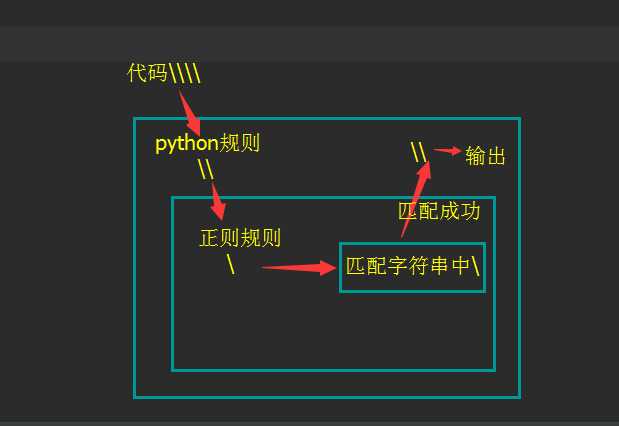
你会不会觉得就因为正则规则和python规则相冲突而把这个搞得好麻烦呢??所以r登场了,它是让python别胡乱瞎搞的
import re str1 = ‘4d4g2c\n 5\v‘ m1 = re.findall(‘\d‘,str1) print(m1) #[‘4‘, ‘4‘, ‘2‘, ‘5‘] m2 = re.findall(‘\w‘,str1) print(m2) #[‘4‘, ‘d‘, ‘4‘, ‘g‘, ‘2‘, ‘c‘, ‘5‘] m3 = re.findall(‘\s‘,str1) print(m3) #[‘\n‘, ‘ ‘, ‘\x0b‘]
import re str1 = ‘alex*eric eva‘ m4 = re.findall(r‘\b‘,str1) print(m4) #[‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘]
import re
m = re.search(r‘(alex)(eric)com\2\1‘,‘alexericcomericalex‘)
if m:
print(m.group()) #alexericcomericalex
import re
m1 = re.search(‘a(\d+?)‘,‘a21471‘)
if m1:
print(m1.group()) #a2
m2 = re.search(‘a(\d*?)‘,‘a21471‘)
if m2:
print(m2.group()) #a
#如果前后有限定条件,再加非贪婪?--无效
m3 = re.search(‘a(\d+?)b‘,‘a265532b‘)
if m3:
print(m3.group()) #a265532b
m4 = re.search(‘a(\d+)b‘,‘a265532b‘)
if m4:
print(m4.group()) #a265532b
import re
#无分组
origin = ‘hello alex bcd alex lge alex ccd 16‘
r = re.match(‘h\w+‘,origin)
print(r.group()) #hello
print(r.groups()) #()--获取模型中匹配到的分组结果--等同于对匹配到的结果再次进行筛选
print(r.groupdict()) #{}--获取模型中匹配到的分组中所有执行了key的组
#有分组
r = re.match(‘(?P<n1>h)(\w+)‘,origin) #key对应的?P 大写p
print(r.group()) #hello
print(r.groups()) #(‘h‘, ‘ello‘)--获取模型中匹配到的分组结果--等同于对匹配到的结果再次进行筛选
print(r.groupdict()) #{‘n1‘: ‘h‘}--获取模型中匹配到的分组中所有执行了key的组
import re m1 = re.match(‘(a)(l)(e)(x)‘,‘alex‘) print(m1.group(0)) #alex print(m1.group(1)) #a print(m1.group(4)) #x print(m1.start()) #0 print(m1.end()) #4 print(m1.span()) #(0, 4)
import re # m1 = re.search(‘alex‘,‘ALEX‘,re.I) # print(m1.group()) # m2 = re.findall(‘.‘,‘1d5\n2d‘,re.S) # print(m2) str1 = ‘123alex\nalex154ip\nalex15ip‘ m3 = re.findall(‘^alex‘,str1,re.M) print(m3) #以行头为头,以行尾为尾,进行^和$匹配
import re n = re.findall(‘\d+\w\d+‘,‘a2b3c4d5‘) print(n) #[‘2b3‘, ‘4d5‘]--你可能会想:怎么没有‘3c4’ #因为是顺序匹配,在没匹配成功的前提下,逐个往后找,所以结果里没有‘3c4’ #一旦匹配成功,等同拿走匹配到的字符串在往下匹配
import re origin = ‘hello alex bcd‘ r = re.findall(‘(a)(\w+)(x)‘,origin) print(r) #[(‘a‘, ‘le‘, ‘x‘)] r2 = re.findall(‘(a)(\w+(e))(?P<n1>x)‘,origin) print(r2) #[(‘a‘, ‘le‘, ‘e‘, ‘x‘)] #findall方法里加key是无意义的,因为返回对象是列表,没有groupdict方法
import re m1 = re.findall(‘a(le)x‘,‘alexjijfalexjijhfalex‘) print(m1) #[‘le‘, ‘le‘, ‘le‘] #破了findall的优先捕获组的权限--?: m2 = re.findall(‘www.(?:baidu|laonanhai).com‘,‘jfswww.laonanhai.com‘) print(m2) #[‘www.laonanhai.com‘]
import re
origin = ‘hello alex bcd‘
r = re.finditer(‘(a)(\w+)(e)(?P<n1>x)‘,origin)
print(r) #match对象组成的迭代器
for i in r:
print(i) #<_sre.SRE_Match object; span=(6, 10), match=‘alex‘>
print(i.group()) #alex
print(i.groups()) #(‘a‘, ‘l‘, ‘e‘, ‘x‘)
print(i.groupdict()) #{‘n1‘: ‘x‘}
import re
a = ‘alex‘
n = re.findall(‘(\w)(\w)(\w)(\w)‘,a)
print(n) #[(‘a‘, ‘l‘, ‘e‘, ‘x‘)]
n2 = re.findall(‘(\w){4}‘,a)
print(n2) #[‘x‘]
n3 = re.findall(‘(\w)*‘,a)
print(n3) #[‘x‘, ‘‘] *最后会匹配一次空
import re
p = re.compile(r‘\d+‘)
w = p.finditer(‘12 drwn44ers drumming,11alex10eric‘)
print(w)
for mat in w:
print(mat.group(),mat.span())
结果为:
<callable_iterator object at 0x0000000000D1FC50>
12 (0, 2)
44 (7, 9)
11 (22, 24)
10 (28, 30)
import re
m = re.search(‘alex‘,‘abalexsalex‘)
print(m)
if m:
print(m.group()) #alex
import re m = re.sub(‘\d‘,‘love‘,‘i1you2you‘,1) print(m) #iloveyou2you m2 = re.subn(‘\d‘,‘love‘,‘1df4d17g4d8t12df‘) print(m2) #(‘lovedflovedloveloveglovedlovetlovelovedf‘, 8)
import re regex = re.compile(r‘\w*oo\w*‘) print(regex.findall(‘jisf4oo12df14‘)) #[‘jisf4oo12df14‘]
import re m = re.split(‘alex‘,‘jifalex15jialexdf7‘) print(m) #[‘jif‘, ‘15ji‘, ‘df7‘] m = re.split(‘(alex)‘,‘jifalex15jialexdf7‘) print(m) #[‘jif‘, ‘alex‘, ‘15ji‘, ‘alex‘, ‘df7‘]
欢迎大家对我的博客内容提出质疑和提问!谢谢
笔者:拍省先生
标签:
原文地址:http://www.cnblogs.com/xinsiwei18/p/5572424.html