标签:
字符编码
将各种文字、图形、标点、数字整合在一个集合叫做字符集。
把这些字符集按照不用规则进行编码就形成了不同的字符编码。
如
你 用显微镜把盘片放大,会看见盘片表面凹凸不平,凸起的地方被磁化,凹的地方是没有被磁化;凸起的地方代表数字1,凹的地方代表数字0。硬盘只能用0和1 来表示所有文字、图片等信息。那么字母”A”在硬盘上是如何存储的呢?可能小张计算机存储字母”A”是1100001,而小王存储字母”A”是 11000010,这样双方交换信息时就会误解。比如小张把1100001发送给小王,小王并不认为1100001是字母”A”,可能认为这是字 母”X”,于是小王在用记事本访问存储在硬盘上的1100001时,在屏幕上显示的就是字母”X”。也就是说,小张和小王使用了不同的编码表。
字符编码分类
1、ASCII
ASCII全称是 American Standard Code for Information Interchange(美国信息互换标准代码)。
读作‘啊思客’,一直以为II是罗马数字,原来是Information Interchange的缩写。
标准ASCII 码也叫基础ASCII码,使用7 位二进制数来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符,而第8位用来控制奇偶校验
奇偶校验:是一种校验代码传输正确性的方法。根据被传输的一组二进制代码的数位中“1”的个数是奇数或偶数来进行校验。采用奇数的称为奇校验,反之,称为偶校验。采用何种校验是事先规定好的。
通常专门设置一个奇偶校验位,用它使这组代码中“1”的个数为奇数或偶数。若用奇校验,则当接收端收到这组代码时,校验“1”的个数是否为奇数,从而确定传输代码的正确性。
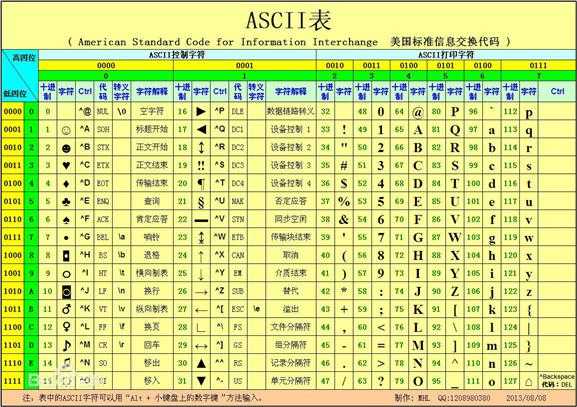
ASCII只能满足美国的应用,其他国家为了满足对本国文字的需要,对ASCII码进行了扩展。取消奇偶校验位,改成了256字符。
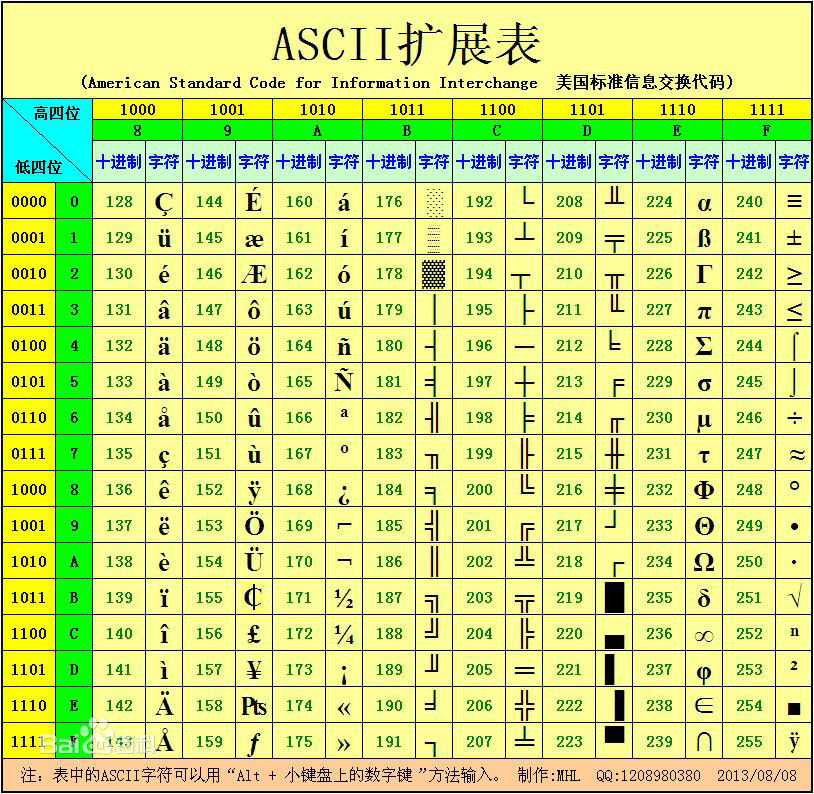
2、ANSI
ansi这种字符码 在windows操作系统不同的言语环境中表示不同的字符编码
在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码
3、GB2312、GBK和GB18030的区别
(1)GB2312
标签:
原文地址:http://www.cnblogs.com/buchizaodian/p/5575486.html