标签:
参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功。下面就把详细的安装步骤叙述一下。我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择2.7.1版本。
创建用户,并为其添加root权限,经过亲自验证下面这种方法比较好。
1 sudo adduser hadoop 2 sudo vim /etc/sudoers 3 # 修改内容如下: 4 root ALL = (ALL)ALL 5 hadoop ALL = (ALL)ALL
给hadoop用户创建目录,并添加到sudo用户组中,命令如下:
1 sudo mkdir /home/hadoop 2 sudo chown hadoop /home/hadoop 3 # 添加到sudo用户组 4 sudo adduser hadoop sudo
最后注销当前用户,使用新创建的hadoop用户登陆。
ubuntu中默认是没有装ssh server的(只有ssh client),所以先运行以下命令安装openssh-server。安装过程轻松加愉快~
sudo apt-get install ssh openssh-server
直接上代码:执行完下边的代码就可以直接登陆了(可以运行ssh localhost进行验证)
1 cd ~/.ssh 2 ssh-keygen -t rsa 3 cp id_rsa.pub authorized_keys
有两种下载方式:
1. 直接去官网下载:
http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
2. 使用wget命令下载:
wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
1. 解压下载的hadoop安装包,并修改配置文件。我的解压目录是(/home/hadoop/hadoop-2.7.1),即进入/home/hadoop/文件夹下执行下面的解压缩命令。
tar -zxvf hadoop-2.7.1.tar.gz
2. 修改配置文件:(hadoop2.7.1/etc/hadoop/)目录下,hadoop-env.sh,core-site.xml,mapred-site.xml.template,hdfs-site.xml。
(1). core-site.xml 配置:其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
(2). mapred-site.xml.template配置:
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
(3). hdfs-site.xml配置: 其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
注意:如果运行Hadoop的时候发现找不到jdk,可以直接将jdk的路径放置在hadoop-env.sh里面,具体如下:
export JAVA_HOME="/opt/java_file/jdk1.7.0_79",即安装java时的路径。
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/data</value> </property> </configuration>
配置完成后运行hadoop。
在hadop2.7.1目录下执行命令:
bin/hdfs namenode -format
出现如下结果说明初始化成功。

NameNode 和 DataNode 守护进程在hadop2.7.1目录下执行命令:
sbin/start-dfs.sh
成功的截图如下:


若出现如图所示结果,则说明DataNode和NameNode都已经开启。
在浏览器中输入 http://localhost:50070 ,即可查看相关信息,截图如下
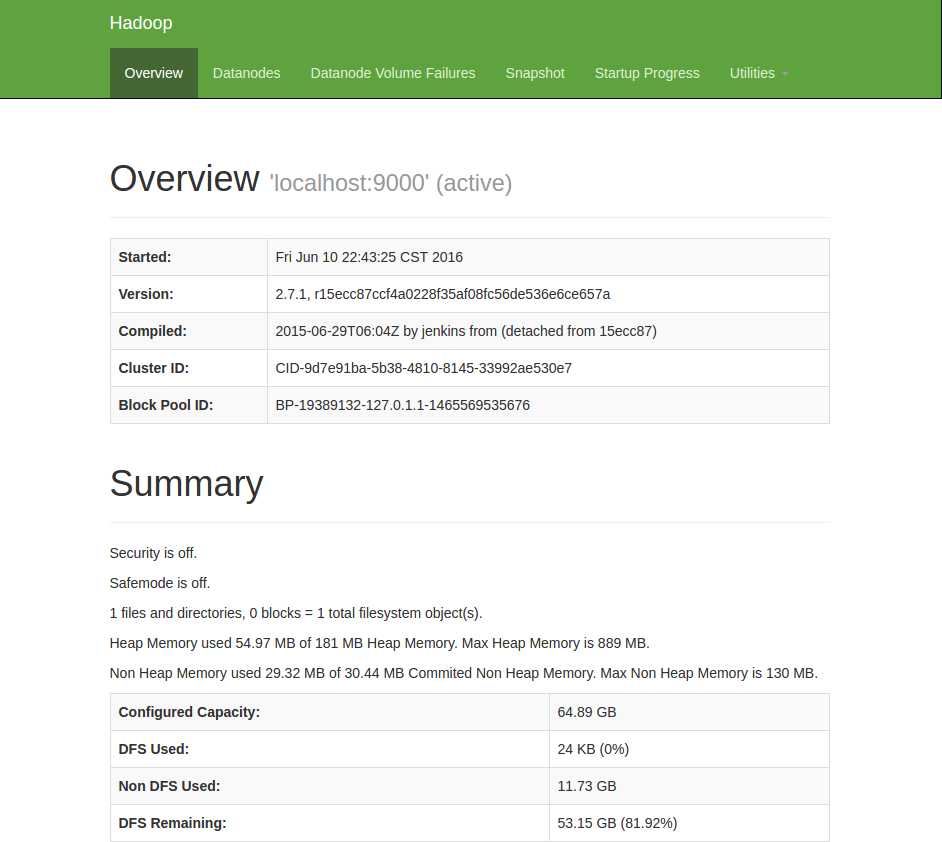
至此,hadoop的环境就已经搭建好了。
1. 在本地新建一个文件,里面内容随便填:例如我在home/hadoop目录下新建了一个haha.txt文件,里面的内容为" hello world! "。
2. 然后在分布式文件系统(hdfs)中新建一个test文件夹,用于上传我们的测试文件haha.txt。在hadoop-2.7.1目录下运行命令:
# 在hdfs的根目录下建立了一个test目录 bin/hdfs dfs -mkdir /test # 查看HDFS根目录下的目录结构 bin/hdfs dfs -ls /
结果如下:

3. 将本地haha.txt文件上传到test目录中;
# 上传 bin/hdfs dfs -put /home/hadoop/haha.txt /test/ # 查看 bin/hdfs dfs -ls /test/
结果如下:

4. 运行wordcount demo;
# 将运行结果保存在/test/out目录下 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /test/haha.txt /test/out # 查看/test/out目录下的文件 bin/hdfs dfs -ls /test/out
结果如下:

运行结果表示:运行成功,结果保存在part-r-00000中。
5. 查看运行结果;
# 查看part-r-00000中的运行结果 bin/hadoop fs -cat /test/out/part-r-00000
结果如下:

至此,wordcount demo 运行结束。
配置过程遇到了很多问题,最后都一一解决,收获很多,特此把这次配置的经验分享出来,方便想要配置hadoop环境的各位朋友~
参考:
http://www.tuicool.com/articles/bmeUneM
标签:
原文地址:http://www.cnblogs.com/lijingchn/p/5574476.html