标签:
这讲介绍最后一个预处理指令---文件包含
其实我们早就有接触文件包含这个指令了, 就是#include,它可以将一个文件的全部内容拷贝另一个文件中。
直接到C语言库函数头文件所在的目录中寻找文件
系统会先在源程序当前目录下寻找,若找不到,再到操作系统的path路径中查找,最后才到C语言库函数头文件所在目录中查找
1.#include指令允许嵌套包含,比如a.h包含b.h,b.h包含c.h,但是不允许递归包含,比如 a.h 包含 b.h,b.h 包含 a.h。
下面的做法是错误的
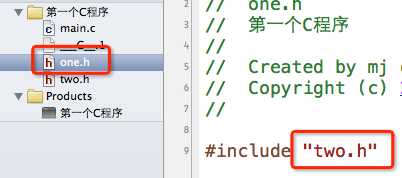
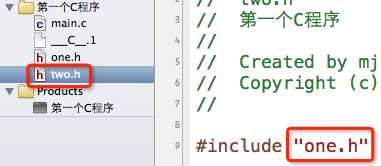
2.使用#include指令可能导致多次包含同一个头文件,降低编译效率
比如下面的情况:
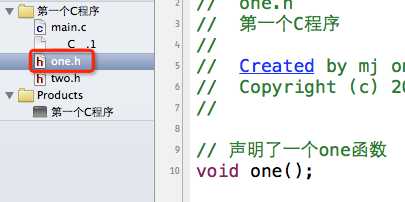
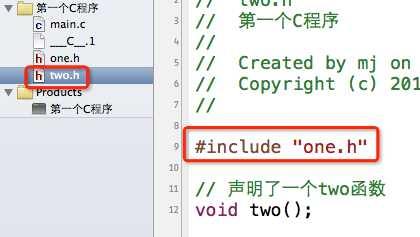
在one.h中声明了一个one函数;在two.h中包含了one.h,顺便声明了一个two函数。(这里就不写函数的实现了,也就是函数的定义)
假如我想在main.c中使用one和two两个函数,而且有时候我们并不一定知道two.h中包含了one.h,所以可能会这样做:
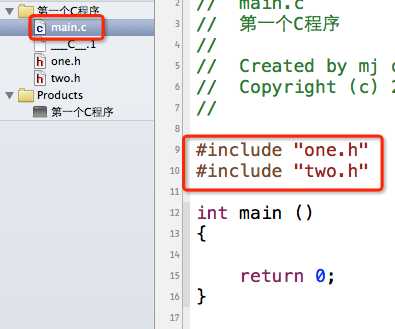
编译预处理之后main.c的代码是这样的:

1 void one();
2 void one();
3 void two();
4 int main ()
5 {
6
7 return 0;
8 }
第1行是由#include "one.h"导致的,第2、3行是由#include "two.h"导致的(因为two.h里面包含了one.h)。可以看出来,one函数被声明了2遍,根本就没有必要,这样会降低编译效率。
为了解决这种重复包含同一个头文件的问题,一般我们会这样写头文件内容:
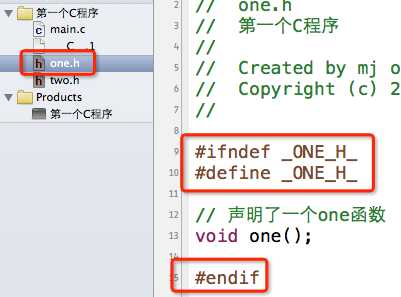
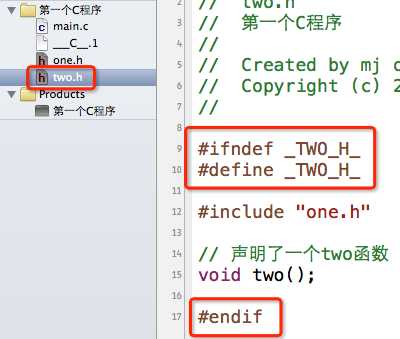
大致解释一下意思,就拿one.h为例:当我们第一次#include "one.h"时,因为没有定义_ONE_H_,所以第9行的条件成立,接着在第10行定义了_ONE_H_这个宏,然后在13行声明one函数,最后在15行结束条件编译。当第二次#include "one.h",因为之前已经定义过_ONE_H_这个宏,所以第9行的条件不成立,直接跳到第15行的#endif,结束条件编译。就是这么简单的3句代码,防止了one.h的内容被重复包含。
这样子的话,main.c中的:
#include "one.h"
#include "two.h"
就变成了:
1 // #include "one.h"
2 #ifndef _ONE_H_
3 #define _ONE_H_
4
5 void one();
6
7 #endif
8
9 // #include "two.h"
10 #ifndef _TWO_H_
11 #define _TWO_H_
12
13 // #include "one.h"
14 #ifndef _ONE_H_
15 #define _ONE_H_
16
17 void one();
18
19 #endif
20
21 void two();
22
23 #endif
第2~第7行是#include "one.h"导致的,第10~第23行是#include "two.h"导致的。编译预处理之后就变为了:
1 void one();
2 void two();
这才是我们想要的结果
标签:
原文地址:http://www.cnblogs.com/LiLihongqiang/p/5579791.html