标签:
Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发。Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于Hadoop MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,节省了磁盘IO耗时,性能比Hadoop更快。 所以,相对来说Hadoop更适合做批处理,而Spark更适合做需要反复迭代的机器学习。下面是我在ubuntu14.04中配置Spark的整个流程以及遇到的问题的,一方面当做自己的备忘录,另一方面也希望能够给像我一样初次配置的新手提供一些帮助~╮(╯▽╰)╭
注意:确保你之前已经安装配置好了hadoop集群(YARN方式),可以参考我的另一篇博文:Linux中安装配置hadoop集群
我所使用的环境:
ubuntu 14.04 LTS 计算机两台,一个当作Master,一个作slave。
Scala版本:scala-2.10.6
Hadoop版本:hadoop-2.7.1
Spark版本:spark-1.6.1 (记得下载预编译版本的)
我的安装目录:
Scala:/home/hadoop/spark/scala-2.10.6
Spark:/home/hadoop/spark/spark-1.6.1
Java:/home/javafile/jdk1.7.0_79
1 2 tar zxvf scala-2.10.6.tgz
然后,修改:/etc/profile

同样,还是先去Spark官网下载:spark-1.6.1-bin-hadoop2.6.tgz,解压到:/home/hadoop/spark下;
1 cd /home/hadoop/spark 2 tar zxvf spark-1.6.1-bin-hadoop2.6.tgz
然后,修改:/etc/profile

01. 修改配置文件spark-env.sh
1 cd /home/hadoop/spark/spark-1.6.1/conf 2 cp spark-env.sh.template spark-env.sh
修改spark-env.sh如下:

02. 修改配置文件slaves
在slaves中添加你的slave主机名:我只有一个slave,所以只添加了一个。

03. 配置slave
至此,master节点上的Spark已配置完毕。把master上Spark相关配置copy到slave中。(注意,三台机器spark所在目录必须一致,因为master会登陆到worker上执行命令,master认为worker的spark路径与自己一样)
启动命令非常简单:
1 cd /home/hadoop/spark/spark-1.6.1 2 sbin/start-all.sh
使用 jps 命令,查看master和slave上的进程:


进入Spark的Web管理页面: http://master:8080 (将master替换成你的master主机名即可)
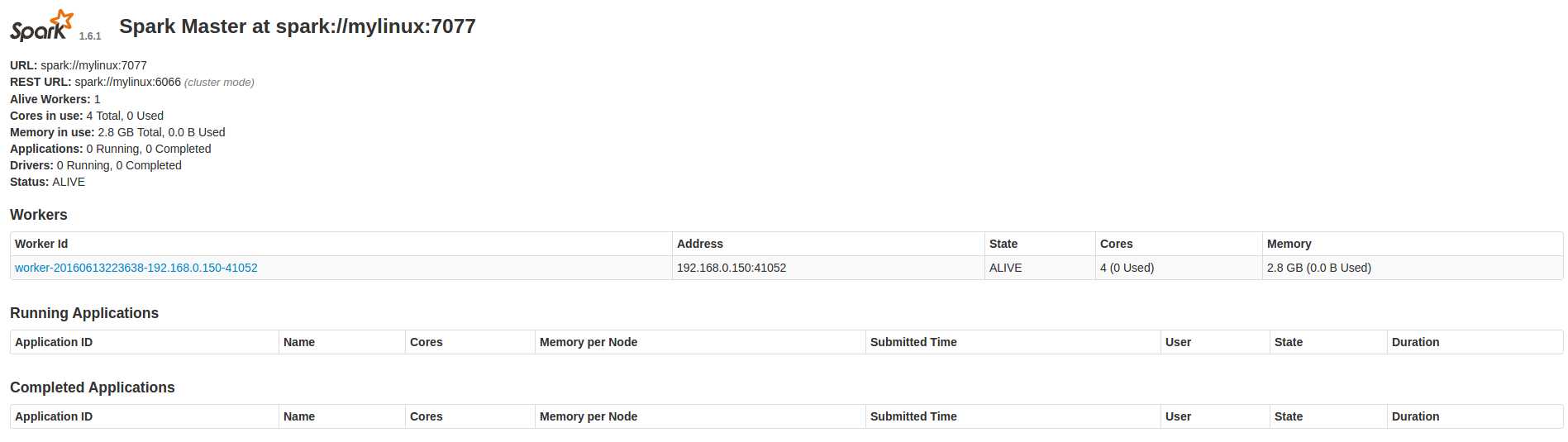
至此,Spark集群的安装配置就完成了,有什么不对的地方还请大家指正,一起交流讨论~
参考:
http://www.tuicool.com/articles/MbuaUv
http://wuchong.me/blog/2015/04/04/spark-on-yarn-cluster-deploy/
标签:
原文地址:http://www.cnblogs.com/lijingchn/p/5573898.html