标签:
前四章介绍了系统层的设计,从这一章开始进入服务层的设计。
在常见的服务器场景中,客户端断开连接的方式为被动关闭。即作为客户端请求完服务器的服务后,选择主动关闭同服务器的连接。在服务器的角度看,服务器是客户端连接套接字read系统调用返回0,触发关闭逻辑,服务器本地是被动关闭连接的。
但是在某些场景中,客户端虽然已经实际断开了与服务器的连接,但是服务器并不能及时检测出此时维护的连接已经断开的情景。在这种情况下,由于被动关闭的缘故,服务器并不会主动释放与该连接有关的资源。这些不能被释放的资源包括文件描述符、系统内存等系统稀缺资源。如果服务器系统中出现大量类似僵死连接得不到及时处理,将会导致系统资源耗尽的问题,可能会严重影响到服务器的性能,甚至导致服务器崩溃。
一般而言,判断一个连接是否断开,只需调用write,返回为0,则为掉线。但是在长连接下,很有可能很长的一段时间都没有数据往来。理论上,这个长连接是一直保持连接的,但是实际情况中,如果中间节点出现某些故障是难以知道的。甚至有一些防火墙会自动把一定时间内没有数据交互的连接给断开。
在TCP的机制中,本身存在SO_KEEPALIVE的选项。通过该选项可以设置2小时的心跳额度。但是它检查不到机器断电、网线拔出、防火墙导致断线等这些情况。而且通过该选项也很难在逻辑层对断线进行处理。
综上原因,我们需要制定某种机制来帮助服务器检查连接是否已经断开,对疑似断开连接的客户进行主动关闭,并释放相关资源。
常用软件一般是通过心跳机制来解决检查连接的问题。通常是客户端必须每隔一小段时间向服务器发送一个数据包,通知服务器自己仍然在线,并传输一些可能必要的数据。而服务器则维护每个连接的连接计时,每当每个连接发送有效消息后,就刷新该连接的计时。如果一段时间内服务器没有收到某个连接的计时,则服务器判定该连接失活,并对该连接执行强制关闭和资源释放工作。
服务器如何维护每个连接的连接计时,一般有两种方法:
在方案一中,虽然只有一个定时器的开销,但是每次都需遍历全部连接,如果连接数目比较大,每次遍历工作将会有较大开销。同时执行超时检测的线程可能和连接管理的线程并非同一线程,当超时检测线程读取连接的最后收到数据时间时,可能在另一个线程中正在对该连接的该时间进行修改。因此我们还需要通过读写锁的机制对连接最后收到数据的时间进行保护。
而方案二中,将会给每个连接都创建一个定时器,同时每个连接每次收到一次数据就需修改这个定时器的超时时间。这样将每个连接的定时管理与该连接的管理置于同一个线程之中,避免了多线程环境下的锁开销。但如果连接数目较大,且会有频繁更新定时器的操作,可能会对反应器的定时机制造成较大压力。
以上两种方案中,实现均并不困难,但是均比较粗暴,都可能随着连接和更新次数的增加而对服务器性能造成影响,有必要在这两种方案的基础上进行优化。
在之前的方案一中,最大的开销是每次检查超时连接时都需遍历所有连接的接收时间,时间复杂度为O(n)。我们可以在此基础上对其进行优化,通过某种策略让检查超时的操作在尽可能短的时间内找出所有的超时连接。
通过分析超时时间可知,对于所有连接而言,系统设定的超时时间是相同的。在均未收到新数据的情况下,上次先收到数据的连接肯定比后收到数据的连接先超时。这类似于一个先进先出的队列。因此我们尝试用队列对超时连接进行管理。
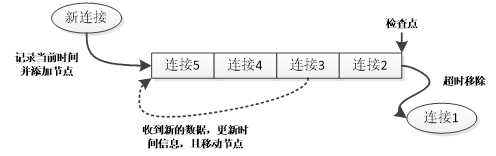
图4-1 超时队列
如图4-1所示,我们创建了一个先入先出队列用来管理超时连接。为了保证该队列的线程安全,每次对该队列进行添加和删除操作均需在加锁情况下进行。在每个队列节点中,我们都保存了对应连接的上次接收消息时间。并且我们此时不考虑该连接又收到新的消息导致接收消息时间更新的情景。
每当有新连接建立时,我们尝试获取超时队列锁,然后创建一个新的队列节点,并在该节点中保存该连接信息和当前时间。最后我们将这个新连接对应的节点添加到超时队列的头部。此时该节点之后的超时队列中已有连接1至5对应的节点,且每个节点对应连接的接收时间依次递增,即连接1的接收时间早于连接2,连接2的接收时间早于连接3,以此类推。
系统建立了一个定时器,每隔一段时间检查超时队列中接收时间已经过期的连接。首先会检查超时队列最尾部的节点,如果对该节点对应连接的接收时间进行判断,显示未超时,则整个超时队列中的其他节点对应连接也均未超时,此次定时事件直接结束处理。如果判定该队尾节点对应连接已经超时,则记录该连接信息,并将该节点从队尾移除。然后再判断新的队尾节点是否已超时,如超时则同样记录并且移除,直到新的队尾节点未超时为止。最后系统将会向此次检测超时的所有连接发送超时通知,并最终强制断开这些超时连接。
因为连接1的接收时间早于连接2,所以如果连接1未超时,连接2也显然为超时;但如果连接1此时已经超时,则无法判断之后的连接是否超时,因此还需再检测连接2,直到从超时队列中检测到一个未超时的节点,该节点及之后节点也均未超时。
此时我们的超时队列已经能够满足无时间更新时的工作了。我们再添加它对接收到新的消息后,对接收时间的更新工作。依旧是如图的场景,此时连接3接收到了一条新的心跳消息,我们需要将该连接的计时重置。相应的操作其实很简单,获取超时队列的锁,找到该连接在超时队列中的节点,将该节点重新移到队列的头部,并更新节点中保存的上次接收数据时间即可。此时该节点所对应的连接成为超时队列管理的所有连接中时间最新的连接,当前连接均不变的话,该连接将最后超时。
其中还是存在一个问题,连接如何确定自己对应的超时队列中的节点。如果不建立某种映射信息,我们从超时队列中查找某次连接的节点将需遍历整个超时队列中的所有节点,而获取连接对应节点又是更新超时时间必须的操作。如果每个连接每次更新超时时间都需要遍历超时队列,而超时队列又维护了成千上万的连接,那这将给整个系统带来极大的性能开销。
我们可以采用STL库的std::list作为超时队列的底层实现,list数据结构保证其中的每个节点在整个生命周期内对应的内存空间不变。因此我们可以在每个连接对应对象中保存一个指向超时队列中对应节点的指针,当我们需要定位到该连接的超时节点时,只需对该指针取引用就行了,免去了遍历列表的开销。
但是这种方式同样存在一定危险。因为该指针所指节点为超时队列的内部数据,我们将该指针暴露给连接对象,也就相当于把超时队列内部的数据泄露了出去,这可能会对整个队列的安全产生影响。比如原来多线程环境下对该超时队列的所有访问都需要添加线程锁保证线程安全,但是现在可以通过该指针绕过线程锁访问甚至修改超时队列中的数据。
在系统实现中,我们设计了名为LinkedHashMap的数据结构,通过该结构来维护超时队列,同时建立了键值对映射机制,来确保通过某个Key就可获取对应的队列节点。
我们设计的LinkedHashMap类似于HashMap,同样提供键值对映射功能,但是它保留键值对插入的顺序,也就是说它既能满足键值对数据根据插入顺序先入先出的要求,同时也能根据键数据映射快速查找出值数据。
LinkedHashMap内部由一个STL的std::list和一个std::unordered_map组成。每当有一个新键值对传入,就在list表头创建一个节点,并保存键值数据。同时在unordered_map中创建一个该键与队列中对应节点迭代器的映射。因此我们借助list实现了根据插入顺序排序的队列,而通过键映射我们又能快速找出队列中对应节点的迭代器,从而获取队列节点中数据。
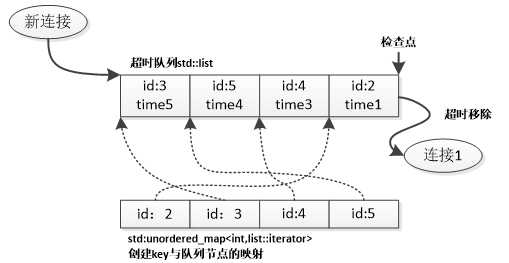
图4-2 LinkedHashMap实现的超时队列
在系统实现中,我们为每个连接对象分配了一个唯一的ID,并为其建立了ID与连接对象的映射,通过这个ID,我们可以很方便的获取对应的连接对象。在超时管理的具体实现中,我们使用连接ID代替实际的连接对象。
如图4-2所示,我们将ID作为了LinkedHashMap的键,ID和对应连接的最后接收消息时间作为了值,构造了以上的LinkedHashMap结构。我们依次添加了连接1至连接5的数据,并更新了连接3的最后接收消息时间,并且连接1已经由于超时原因被移除。
当我们添加一个新的连接时,只需获取该连接的ID和最后接收消息时间,并插入LinkedHashMap中,LinkedHashMap会将新节点插入队列的头部,并建立ID与节点的映射。当我们需要更新某个连接的最后接收消息时间时,只需通过ID便可获得所在节点,并修改最后接收消息时间并将该节点重新连接到队列头部。当该节点被系统检测到超时时,我们可以根据节点中保存的ID获知具体超时的连接对象,并将该ID的相关数据从list和unordered_map中移除即可。以上对于LinkedHashMap的插入、更新和删除操作均能大致保证在常数时间完成。
通过以上设计,我们能够高效的实现对连接的超时管理。同时整个超时机制仅通过一个ID值保持与系统实际连接对象的联系,保证了模块间的低耦合度。
标签:
原文地址:http://www.cnblogs.com/moyangvip/p/5585994.html