标签:
http://www.cnblogs.com/zhangchaoyang/articles/2200800.html
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)天生就是为处理超大规模(至少要让你的内存容不下)的数据集而设计的,它可以在任何给定的内存下运行。关于BIRCH的更多特点先不介绍,我先讲一下算法的完整实现细节,对算法的实现过程搞清楚后再去看别人对该算法的评价才会感受深刻。
你不需要具备B树的相关知识,我接下来会讲得很清楚。
BIRCH算法的过程就是要把待分类的数据插入一棵树中,并且原始数据都在叶子节点上。这棵树看起来是这个样子:
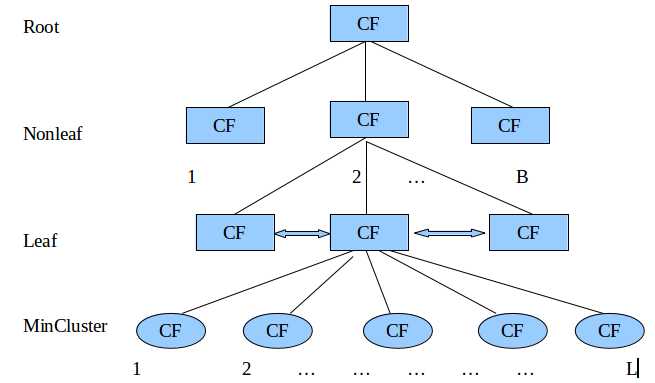
在这棵树中有3种类型的节点:Nonleaf、Leaf、MinCluster,Root可能是一种Nonleaf,也可能是一种Leaf。所有的Leaf放入一个双向链表中。每一个节点都包含一个CF值,CF是一个三元组,其中data point instance的个数,
和
是与数据点同维度的向量,
是线性和,
是平方和。比如有一个MinCluster里包含3个数据点(1,2,3),(4,5,6),(7,8,9),则
N=3,
=(1+4+7,2+5+8,3+6+9)=(12,15,18),
=(1+16+49,4+25+64,9+36+81)。
就拿这个MinCluster为例,我们可以计算它的
簇中心
簇半径
簇直径
我们还可以计算两个簇之间的距离,当然你也可以使用D0,D1,D3等等,不过在这里我们使用D2。
有意思的是簇中心、簇半径、簇直径以及两簇之间的距离D0到D3都可以由CF来计算,比如
簇直径
簇间距离,这里的N,LS和SS是指两簇合并后大簇的N,LS和SS。所谓两簇合并只需要两个对应的CF相加那可
CF1 + CF2 = (N1 + N2 , LS1 + LS2, SS1 + SS2)
每个节点的CF值就是其所有孩子节点CF值之和,以每个节点为根节点的子树都可以看成 是一个簇。
Nonleaf、Leaf、MinCluster都是有大小限制的,Nonleaf的孩子节点不能超过B个,Leaf最多只能有L个MinCluster,而一个MinCluster的直径不能超过T。
算法起初,我们扫描数据库,拿到第一个data point instance--(1,2,3),我们创建一个空的Leaf和MinCluster,把点(1,2,3)的id值放入Mincluster,更新MinCluster的CF值为(1,(1,2,3),(1,4,9)),把MinCluster作为Leaf的一个孩子,更新Leaf的CF值为(1,(1,2,3),(1,4,9))。实际上只要往树中放入一个CF(这里我们用CF作为Nonleaf、Leaf、MinCluster的统称),就要更新从Root到该叶子节点的路径上所有节点的CF值。
当又有一个数据点要插入树中时,把这个点封装为一个MinCluster(这样它就有了一个CF值),把新到的数据点记为CF_new,我们拿到树的根节点的各个孩子节点的CF值,根据D2来找到CF_new与哪个节点最近,就把CF_new加入那个子树上面去。这是一个递归的过程。递归的终止点是要把CF_new加入到一个MinCluster中,如果加入之后MinCluster的直径没有超过T,则直接加入,否则譔CF_new要单独作为一个簇,成为MinCluster的兄弟结点。插入之后注意更新该节点及其所有祖先节点的CF值。
插入新节点后,可能有些节点的孩子数大于了B(或L),此时该节点要分裂。对于Leaf,它现在有L+1个MinCluster,我们要新创建一个Leaf,使它作为原Leaf的兄弟结点,同时注意每新创建一个Leaf都要把它插入到双向链表中。L+1个MinCluster要分到这两个Leaf中,怎么分呢?找出这L+1个MinCluster中距离最远的两个Cluster(根据D2),剩下的Cluster看离哪个近就跟谁站在一起。分好后更新两个Leaf的CF值,其祖先节点的CF值没有变化,不需要更新。这可能导致祖先节点的递归分裂,因为Leaf分裂后恰好其父节点的孩子数超过了B。Nonleaf的分裂方法与Leaf的相似,只不过产生新的Nonleaf后不需要把它放入一个双向链表中。如果是树的根节点要分裂,则树的高度加1。
CF.java
package birch;public class CF { private int N; private double[] LS; private double[] SS; public CF() { LS=new double[BIRCH.dimen]; SS=new double[BIRCH.dimen]; } // 根据一个data point instance创建一个Clustering Feature public CF(double[] data) { int len = data.length; this.N = 1; this.LS = data; this.SS=new double[len]; for (int i = 0; i < len; i++) this.SS[i] = Math.pow(data[i], 2); } //复制构造函数(深复制) public CF(CF cf){ this.N=cf.getN(); int len=cf.getLS().length; this.LS=new double[len]; this.SS=new double[len]; for(int i=0;i<len;i++){ this.LS[i]=cf.getLS()[i]; this.SS[i]=cf.getSS()[i]; } } // 采用D2计算两个CF Entry之间的距离 public double getDistanceTo(CF entry) { double dis = 0.0; int len = this.LS.length; // 采用D2 for (int i = 0; i < len; i++) { dis += this.SS[i] / this.N + entry.getSS()[i] / entry.getN() - 2 * this.LS[i] * entry.getLS()[i] / (this.N * entry.getN()); } return Math.sqrt(dis); } //采用D0计算两个簇心之间的欧氏距离// public double getDistanceTo(CF entry) {// int len=entry.getLS().length;// double[] a=new double[len];// double[] b=new double[len];// for(int i=0;i<len;i++){// a[i]=this.getLS()[i]/this.N;// b[i]=this.getSS()[i]/this.N;// }// return calEuraDist(a,b,len);// } // 加上或减去一个CF的值 public void addCF(CF entry, boolean add) { int opt = 1; // 默认为相加 if (!add) // 如果add为false则为相减 opt = -1; this.N = this.N + entry.getN() * opt; int len = this.LS.length; for (int i = 0; i < len; i++) { this.LS[i] = this.LS[i] + entry.getLS()[i] * opt; this.SS[i] = this.SS[i] + entry.getSS()[i] * opt; } } //计算两个向量的欧氏距离 public static double calEuraDist(double[] arr1,double[] arr2,int len){ double result=0.0; for(int i=0;i<len;i++){ result+=Math.pow(arr1[i]-arr2[i],2.0); } return Math.sqrt(result); } public int getN() { return N; } public void setN(int n) { N = n; } public double[] getLS() { return LS; } public void setLS(double[] lS) { LS = lS; } public double[] getSS() { return SS; } public void setSS(double[] sS) { SS = sS; }} |
MinCluster.java
package birch;import java.util.ArrayList;//最小簇public class MinCluster { private CF cf; private ArrayList<String> inst_marks; public MinCluster(){ cf=new CF(); inst_marks=new ArrayList<String>(); } public CF getCf() { return cf; } public void setCf(CF cf) { this.cf = cf; } public ArrayList<String> getInst_marks() { return inst_marks; } public void setInst_marks(ArrayList<String> inst_marks) { this.inst_marks = inst_marks; } //计算簇的直径 public static double getDiameter(CF cf){ double diameter=0.0; int n=cf.getN(); for(int i=0;i<cf.getLS().length;i++){ double ls=cf.getLS()[i]; double ss=cf.getSS()[i]; diameter=diameter+(2*n*ss-2*ls*ls); } diameter=diameter/(n*n-n); return Math.sqrt(diameter); } //计算和另外一个簇合并后的直径 public static double getDiameter(MinCluster cluster1,MinCluster cluster2){ CF cf=new CF(cluster1.getCf()); cf.addCF(cluster2.getCf(), true); return getDiameter(cf); } public void mergeCluster(MinCluster cluster){ this.getCf().addCF(cluster.getCf(), true); for(int i=0;i<cluster.getInst_marks().size();i++){ this.getInst_marks().add(cluster.getInst_marks().get(i)); } }} |
TreeNode.java
package birch;public abstract class TreeNode extends CF { private TreeNode parent; public TreeNode() { } public TreeNode(double[] data) { super(data); } public TreeNode getParent() { return parent; } public void setParent(TreeNode parent) { this.parent = parent; } public void addCFUpToRoot(CF cf){ TreeNode node=this; while(node!=null){ node.addCF(cf, true); node=node.getParent(); } } abstract void split(); abstract void absorbSubCluster(MinCluster cluster);} |
NonleafNode.java
package birch;import java.util.ArrayList;public class NonleafNode extends TreeNode { private int B=5; private ArrayList<TreeNode> children; public NonleafNode() { children=new ArrayList<TreeNode>(); } public NonleafNode(double[] data) { super(data); } // 节点分裂 public void split() { // 找到距离最远的两个孩子节点 int c1 = 0; int c2 = 0; double maxDist = 0; int len = this.getChildren().size(); for (int i = 0; i < len - 1; i++) { for (int j = i + 1; j < len; j++) { double dist = this.getChildren().get(i) .getDistanceTo(this.getChildren().get(j)); if (dist > maxDist) { maxDist = dist; c1 = i; c2 = j; } } } // 以距离最远的孩子节点为中心,把B+1个孩子分为两个大簇。其中一个簇仍留作本节点的孩子,另外一簇需要新创建一个节点来领养它们 NonleafNode newNode = new NonleafNode(); newNode.addChild(this.getChildren().get(c2)); //如果本节点已经是Root节点,则需要创建一个新的Root节点 if(this.getParent()==null){ NonleafNode root= new NonleafNode(); root.setN(this.getN()); root.setLS(this.getLS()); root.setSS(this.getSS()); root.addChild(this); this.setParent(root); } newNode.setParent(this.getParent()); ((NonleafNode)this.getParent()).addChild(newNode); for (int i = 0; i < len; i++) { if (i != c1 && i != c2) { if (this.getChildren().get(i) .getDistanceTo(this.getChildren().get(c2)) < this .getChildren().get(i) .getDistanceTo(this.getChildren().get(c1))) { newNode.addChild(this.getChildren().get(i)); } } } for (TreeNode entry : newNode.getChildren()) { newNode.addCF(entry, true); this.deleteChild(entry); this.addCF(entry, false); } //如果本节点分裂导致父节点的孩子数超过了分枝因子,引发父节点分裂 NonleafNode pn=(NonleafNode)this.getParent(); if(pn.getChildren().size()>B){ this.getParent().split(); } } public void absorbSubCluster(MinCluster cluster){ //从本节点的孩子中寻找与cluster最近的子节点 CF cf=cluster.getCf(); int nearIndex=0; double minDist=Double.MAX_VALUE; for(int i=0;i<this.getChildren().size();i++){ double dist=cf.getDistanceTo(this.getChildren().get(i)); if(dist<minDist){ nearIndex=i; } } //让那个最近的子节点absorb掉这个新到的cluster this.getChildren().get(nearIndex).absorbSubCluster(cluster); } public ArrayList<TreeNode> getChildren() { return children; } public void setChildren(ArrayList<TreeNode> children) { this.children = children; } public void addChild(TreeNode child) { this.children.add(child); } public void deleteChild(TreeNode child) { this.children.remove(children.indexOf(child)); } public int getB() { return B; } public void setB(int b) { B = b; }} |
LeafNode.java
package birch;import java.util.ArrayList;public class LeafNode extends TreeNode { private int L=10; private double T=2.8; private ArrayList<MinCluster> children; private LeafNode pre; private LeafNode next; public LeafNode() { children=new ArrayList<MinCluster>(); } public LeafNode(double[] data) { super(data); } // 节点分裂 public void split() { // 找到距离最远的两个孩子节点 int c1 = 0; int c2 = 0; double maxDist = 0; int len = this.getChildren().size(); for (int i = 0; i < len - 1; i++) { for (int j = i + 1; j < len; j++) { double dist = this.getChildren().get(i).getCf() .getDistanceTo(this.getChildren().get(j).getCf()); if (dist > maxDist) { maxDist = dist; c1 = i; c2 = j; } } } // 以距离最远的孩子节点为中心,把B+1个孩子分为两个大簇。其中一个簇仍留作本节点的孩子,另外一簇需要新创建一个节点来领养它们 LeafNode newNode = new LeafNode(); newNode.addChild(this.getChildren().get(c2)); // 如果本节点已经是Root节点,则需要创建一个新的Root节点 if (this.getParent() == null) { NonleafNode root = new NonleafNode(); root.setN(this.getN()); root.setLS(this.getLS()); root.setSS(this.getSS()); this.setParent(root); root.addChild(this); } //建立新节点和本节点的父节点的父子关系 newNode.setParent(this.getParent()); ((NonleafNode)this.getParent()).addChild(newNode); //把离newNode近的孩子节点归到newNode这个簇里面 for (int i = 0; i < len; i++) { if (i != c1 && i != c2) { if (this.getChildren().get(i).getCf() .getDistanceTo(this.getChildren().get(c2).getCf()) < this .getChildren().get(i).getCf() .getDistanceTo(this.getChildren().get(c1).getCf())) { newNode.addChild(this.getChildren().get(i)); } } } //把离newNode近的孩子节点从本节点中删除 for (MinCluster cluster : newNode.getChildren()) { newNode.addCF(cluster.getCf(), true); this.deleteChild(cluster); this.addCF(cluster.getCf(), false); } // 把新增加的LeafNode添加到LeafNode双向链表中 if (this.getNext() != null) { newNode.setNext(this.getNext()); this.getNext().setPre(newNode); } this.setNext(newNode); newNode.setPre(this); // 如果本节点分裂导致父节点的孩子数超过了分枝因子,引发父节点分裂 NonleafNode pn = (NonleafNode) this.getParent(); if (pn.getChildren().size() > pn.getB()) { this.getParent().split(); } } @Override public void absorbSubCluster(MinCluster cluster) { // 先试图找到叶子节点的孩子(一些subcluster)中与cluster最近的簇 CF cf = cluster.getCf(); int nearIndex = 0; double minDist = Double.MAX_VALUE; int len = this.getChildren().size(); if (len > 0) { for (int i = 0; i < len; i++) { double dist = cf.getDistanceTo(this.getChildren().get(i) .getCf()); if (dist < minDist) { nearIndex = i; } } // 计算两个簇合并后的直径 double mergeDiameter = MinCluster.getDiameter(cluster, this .getChildren().get(nearIndex)); // 如果合并后发现簇的直径超过了阈值,则把cluster作为一个单独的孩子插入本叶子节点下 if (mergeDiameter > T) { this.addChild(cluster); if (this.getChildren().size() > L) { this.split(); } } // 如果不超过阈值,则直接合并两个簇 else { this.getChildren().get(nearIndex).mergeCluster(cluster); } } // 创建B树之初,叶子节点还没有children else { this.addChild(cluster); } this.addCFUpToRoot(cluster.getCf()); } public ArrayList<MinCluster> getChildren() { return children; } public void setChildren(ArrayList<MinCluster> children) { this.children = children; } public void addChild(MinCluster child) { this.children.add(child); } public void deleteChild(MinCluster child) { this.children.remove(children.indexOf(child)); } public LeafNode getPre() { return pre; } public void setPre(LeafNode pre) { this.pre = pre; } public LeafNode getNext() { return next; } public void setNext(LeafNode next) { this.next = next; } public int getL() { return L; } public void setL(int l) { L = l; } public double getT() { return T; } public void setT(double t) { T = t; }} |
BIRCH.java
package birch;import java.io.BufferedReader;import java.io.File;import java.io.FileReader;import java.io.IOException;public class BIRCH { public static final int dimen=4; LeafNode leafNodeHead=new LeafNode(); int point_num=0; //point instance计数 //逐条扫描数据库,建立B-树 public TreeNode buildBTree(String filename){ //先建立一个叶子节点 LeafNode leaf=new LeafNode(); TreeNode root=leaf; //把叶子节点加入存储叶子节点的双向链表 leafNodeHead.setNext(leaf); leaf.setPre(leafNodeHead); //打开文件,从文件中读取原始数据 File file = new File(filename); if(!file.exists()){ System.out.println("Data File Not Exists."); System.exit(2); } try { FileReader fr = new FileReader(file); BufferedReader br=new BufferedReader(fr); String line=null; while((line=br.readLine())!=null && line.trim()!=""){ point_num++; String[] cont=line.split("[,|\\s+]"); //读入point instance double[] data=new double[dimen]; for(int i=0;i<data.length;i++){ data[i]=Double.parseDouble(cont[i]); } String mark=String.valueOf(point_num)+cont[data.length]; //根据一个point instance创建一个MinCluster CF cf=new CF(data); MinCluster subCluster=new MinCluster(); subCluster.setCf(cf); subCluster.getInst_marks().add(mark); //把新到的point instance插入树中 root.absorbSubCluster(subCluster); //要始终保证root是树的根节点 while(root.getParent()!=null){ root=root.getParent(); } } br.close(); } catch (IOException e) { e.printStackTrace(); } return root; } //打印B-树的所有叶子节点 public void printLeaf(LeafNode header){ //point_num清0 point_num=0; while(header.getNext()!=null){ System.out.println("\n一个叶子节点:"); header=header.getNext(); for(MinCluster cluster:header.getChildren()){ System.out.println("\n一个最小簇:"); for(String mark:cluster.getInst_marks()){ point_num++; System.out.print(mark+"\t"); } } } } //打印指定根节点的子树 public void printTree(TreeNode root){ if(!root.getClass().getName().equals("birch.LeafNode")){ NonleafNode nonleaf=(NonleafNode)root; for(TreeNode child:nonleaf.getChildren()){ printTree(child); } } else{ System.out.println("\n一个叶子节点:"); LeafNode leaf=(LeafNode)root; for(MinCluster cluster:leaf.getChildren()){ System.out.println("\n一个最小簇:"); for(String mark:cluster.getInst_marks()){ System.out.print(mark+"\t"); point_num++; } } } } public static void main(String[] args) { BIRCH birch=new BIRCH(); TreeNode root=birch.buildBTree("/home/orisun/test/iris.shuffled"); birch.point_num=0; birch.printTree(root); System.out.println(); //birch.printLeaf(birch.leafNodeHead); //确认被分类的point instance和扫描数据库时录入的point instance的个数是一致的 System.out.println(birch.point_num); }} |
最后我们来总结一BIRCH的优势和劣势。
优点:
缺点:
标签:
原文地址:http://www.cnblogs.com/bnuvincent/p/5587492.html