标签:style blog http color java 使用 os strong
1. AQS简介
AQS是Java并发类库的基础,其提供了一个基于FIFO队列,可以用于构建锁或者其他相关同步装置的基础框架。该同步器(以下简称同步器)利用了一个int来表示状态,期望它能够成为实现大部分同步需求的基础。使用的方法是继承,子类通过继承同步器并需要实现它的方法来管理其状态,管理的方式就是通过类似acquire和release的方式来操纵状态。然而多线程环境中对状态的操纵必须确保原子性,因此子类对于状态的把握,需要使用这个同步器提供的以下三个方法对状态进行操作:
- java.util.concurrent.locks.AbstractQueuedSynchronizer.getState()
- java.util.concurrent.locks.AbstractQueuedSynchronizer.setState(int)
- java.util.concurrent.locks.AbstractQueuedSynchronizer.compareAndSetState(int, int)
子类推荐被定义为自定义同步装置的内部类,同步器自身没有实现任何同步接口,它仅仅是定义了若干acquire之类的方法来供使用。该同步器即可以作为排他模式也可以作为共享模式,当它被定义为一个排他模式时,其他线程对其的获取就被阻止,而共享模式对于多个线程获取都可以成功。
同步器是实现锁的关键,利用同步器将锁的语义实现,然后在锁的实现中聚合同步器。可以这样理解:锁的API是面向使用者的,它定义了与锁交互的公共行为,而每个锁需要完成特定的操作也是透过这些行为来完成的(比如:可以允许两个线程进行加锁,排除两个以上的线程),但是实现是依托给同步器来完成;同步器面向的是线程访问和资源控制,它定义了线程对资源是否能够获取以及线程的排队等操作。锁和同步器很好的隔离了二者所需要关注的领域,严格意义上讲,同步器可以适用于除了锁以外的其他同步设施上(包括锁)。
2. CLH算法
锁的实现是以CLH算法为基础。下面简单介绍一下CLH算法:
CLH算法构建了隐式的链表,是一种非阻塞算法的实现。CLH队列中的结点QNode中含有一个locked字段,该字段若为true表示该线程需要获取锁,且不释放锁,为false表示线程释放了锁。结点之间是通过隐形的链表相连,之所以叫隐形的链表是因为这些结点之间没有明显的next指针,而是通过myPred所指向的结点的变化情况来影响myNode的行为。CLHLock上还有一个尾指针,始终指向队列的最后一个结点。CLHLock的类图如下所示:
当一个线程需要获取锁时,会创建一个新的QNode,将其中的locked设置为true表示需要获取锁,然后线程对tail域调用getAndSet方法,使自己成为队列的尾部,同时获取一个指向其前趋的引用myPred,然后该线程就在前趋结点的locked字段上旋转,直到前趋结点释放锁。当一个线程需要释放锁时,将当前结点的locked域设置为false,同时回收前趋结点。如下图所示,线程A需要获取锁,其myNode域为true,些时tail指向线程A的结点,然后线程B也加入到线程A后面,tail指向线程B的结点。然后线程A和B都在它的myPred域上旋转,一量它的myPred结点的locked字段变为false,它就可以获取锁扫行。明显线程A的myPred
locked域为false,此时线程A获取到了锁。
整个CLH的代码如下,其中用到了ThreadLocal类,将QNode绑定到每一个线程上,同时用到了AtomicReference,对尾指针的修改正是调用它的getAndSet()操作来实现的,它能够保证以原子方式更新对象引用。
CLH算法的示意代码如下:
-
import java.util.concurrent.atomic.AtomicReferenceFieldUpdater;
-
-
public class CLHLock {
-
public static class CLHNode {
-
private boolean isLocked = true;
-
}
-
-
@SuppressWarnings("unused" )
-
private volatile CLHNode tail ;
-
private static final AtomicReferenceFieldUpdater<CLHLock, CLHNode> UPDATER = AtomicReferenceFieldUpdater
-
. newUpdater(CLHLock.class, CLHNode .class , "tail" );
-
-
public void lock(CLHNode currentThread) {
-
CLHNode preNode = UPDATER.getAndSet( this, currentThread);
-
if(preNode != null) {
-
while(preNode.isLocked ) {
-
}
-
}
-
}
-
-
public void unlock(CLHNode currentThread) {
-
-
if (!UPDATER .compareAndSet(this, currentThread, null)) {
-
-
currentThread. isLocked = false ;
-
}
-
}
-
}
至于AQS的实现,和CLH略有不同,
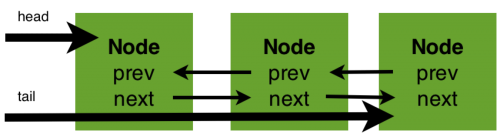
同步器的开始提到了其实现依赖于一个FIFO队列,那么队列中的元素Node就是保存着线程引用和线程状态的容器,每个线程对同步器的访问,都可以看做是队列中的一个节点。Node的主要包含以下成员变量:
-
Node {
-
int waitStatus;
-
Node prev;
-
Node next;
-
Node nextWaiter;
-
Thread thread;
-
}
成员变量主要负责保存该节点的线程引用,同步等待队列(以下简称sync队列)的前驱和后继节点,同时也包括了同步状态。节点成为sync队列和condition队列构建的基础,在同步器中就包含了sync队列。同步器拥有三个成员变量:sync队列的头结点head、sync队列的尾节点tail和状态state。对于锁的获取,请求形成节点,将其挂载在尾部,而锁资源的转移(释放再获取)是从头部开始向后进行。对于同步器维护的状态state,多个线程对其的获取将会产生一个链式的结构。
3.AQS实现分析
3.1 概述
同步器的设计包含获取和释放两个操作:
获取操作过程如下:
if(尝试获取成功){
return;
}else{
加入等待队列;park自己
}
释放操作:
if(尝试释放成功){
unpark等待队列中第一个节点
}else{
return false
}
要满足以上两个操作,需要以下3点来支持:
1、原子操作同步状态;
2、阻塞或者唤醒一个线程;
3、内部应该维护一个队列。
AQS的实现采用了模板设计模式,在AbstractQueuedSynchronizer类中,定义了
-
protected boolean tryAcquire(int arg);
-
protected int tryAcquireShared(int arg);
-
protected boolean tryRelease(int arg);
-
protected boolean tryReleaseShared(int arg);
等未具体实现的方法,子类需要实现这些方法,来完成不同的同步器实现。
3.2 获取、释放锁操作
3.2.1 获取操作
获取锁操作的代码如下:
-
public final void acquire(int arg) {
-
if (!tryAcquire(arg) &&
-
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
-
selfInterrupt();
-
}
上述逻辑主要包括:
1. 尝试获取(调用tryAcquire更改状态,需要保证原子性);
在tryAcquire方法中使用了同步器提供的对state操作的方法,利用compareAndSet保证只有一个线程能够对状态进行成功修改,而没有成功修改的线程将进入sync队列排队(通过调用addWaiter方法)
addWaiter方法如下:
-
private Node addWaiter(Node mode) {
-
Node node = new Node(Thread.currentThread(), mode);
-
-
Node pred = tail;
-
if (pred != null) {
-
node.prev = pred;
-
if (compareAndSetTail(pred, node)) {
-
pred.next = node;
-
return node;
-
}
-
}
-
enq(node);
-
return node;
-
}
2. 如果获取不到,将当前线程构造成节点Node并加入sync队列;
进入队列的每个线程都是一个节点Node,从而形成了一个双向队列,类似CLH队列,这样做的目的是线程间的通信会被限制在较小规模(也就是两个节点左右)。
3. 再次尝试获取(调用acquireQueued方法),如果没有获取到那么将当前线程从线程调度器上摘下,进入等待状态。
acquireQueued代码如下:
-
final boolean acquireQueued(final Node node, int arg) {
-
boolean failed = true;
-
try {
-
boolean interrupted = false;
-
for (;;) {
-
final Node p = node.predecessor();
-
if (p == head && tryAcquire(arg)) {
-
setHead(node);
-
p.next = null;
-
failed = false;
-
return interrupted;
-
}
-
if (shouldParkAfterFailedAcquire(p, node) &&
-
parkAndCheckInterrupt())
-
interrupted = true;
-
}
-
} finally {
-
if (failed)
-
cancelAcquire(node);
-
}
-
}
上述逻辑主要包括:
1. 获取当前节点的前驱节点;
需要获取当前节点的前驱节点,而头结点所对应的含义是当前站有锁且正在运行。
2. 当前驱节点是头结点并且能够获取状态,代表该当前节点占有锁;
如果满足上述条件,那么代表能够占有锁,根据节点对锁占有的含义,设置头结点为当前节点。
3. 否则进入等待状态。
如果没有轮到当前节点运行,那么将当前线程从线程调度器上摘下,也就是进入等待状态。
需要注意的是,acquire在执行过程中,并不能及时的对外界中断进行相应,必须等待执行完毕之后,如果由外部中断,则进行中断响应。与acquire方法类似,acquireInterruptibly方法提供了获取状态能力,当然在无法获取状态的情况下会进入sync队列进行排队,这类似acquire,但是和acquire不同的地方在于它能够在外界对当前线程进行中断的时候提前结束获取状态的操作,换句话说,就是在类似synchronized获取锁时,外界能够对当前线程进行中断,并且获取锁的这个操作能够响应中断并提前返回。一个线程处于synchronized块中或者进行同步I/O操作时,对该线程进行中断操作,这时该线程的中断标识位被设置为true,但是线程依旧继续运行。
3.2.2 释放操作
释放操作代码如下:
-
public final boolean release(int arg) {
-
if (tryRelease(arg)) {
-
Node h = head;
-
if (h != null && h.waitStatus != 0)
-
unparkSuccessor(h);
-
return true;
-
}
-
return false;
-
}
上述逻辑主要包括:
1. 尝试释放状态;
tryRelease能够保证原子化的将状态设置回去,当然需要使用compareAndSet来保证。如果释放状态成功过之后,将会进入后继节点的唤醒过程。
2. 唤醒当前节点的后继节点所包含的线程。
通过LockSupport的unpark方法将休眠中的线程唤醒,让其继续acquire状态。
The java.util.concurrent Synchronizer Framework Base Class—AbstractQueuedSynchronizer,布布扣,bubuko.com
The java.util.concurrent Synchronizer Framework Base Class—AbstractQueuedSynchronizer
标签:style blog http color java 使用 os strong
原文地址:http://blog.csdn.net/aigoogle/article/details/38368171