标签:
1.模块简介
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用python标准库的方法。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
2.模块的引入
在Python中用关键字import来引入某个模块,比如要引用模块math,就可以在文件最开始的地方用import math来引入。在调用math模块中的函数时,必须这样引用:
模块名.函数名 例: import sys import module
有时候我们只需要用到模块中的某个函数,只需要引入该函数即可,此时可以通过语句
from 模块名 import 函数名1,函数名2....
例:
import module #从某个模块导入某个功能 from module.xx.xx import xx #从某个模块导入某个功能,并且给他个别名 from module.xx.xx import xx as rename #从某个模块导入所有 from module.xx.xx import *
模块分为三种
#安装模块的几种方式
(1)yum,pip安装:http://www.ttlsa.com/python/how-to-install-and-use-pip-ttlsa/
(2)源码安装
需要编译环境:yum install python-devel gcc 下载源码包:wget http://xxxxxxxxxxx.tar 解压:tar -xvf xxx.tar 进入:cd xxx 编译:python setup.py build 安装:python setup.py install
1.在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。
写一个自定义模块(模块文件要和调用该模块的程序在同一目录下)
#s4.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: Jason Wang
def login():
print("login")
def logout():
print(‘logout‘)
#执行s3输出: login
2.模块文件为单独文件夹,文件夹和程序在同一目录
导入模块其实就是告诉Python解释器去解释那个py文件
3.sys.path添加目录
如果sys.path路径列表没有你想要的路径,可以通过 sys.path.append(‘路径‘) 添加。
通过os模块可以获取各种目录,如果自定义模块的目录机构包含两级文件目录,可以将第一级父目录加到path变量中例如:
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) #os.path.abspath(__file__)获取文件的绝对路径,os.path.dirname获取此文件的父目录,此例子为将Atm_shopping加入到系统path路径中去
1.os模块 提供系统级别的操作
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
>>> os.getcwd() ‘/Users/JasonWang/PycharmProjects/sd13‘
os.chdir("目录名") 改变当前脚本工作目录;相当于linux下cd命令
>>> os.chdir(‘/usr‘) >>> os.getcwd() ‘/usr‘ >>>
os.curdir 返回当前目录: (‘.‘)
>>> os.curdir ‘.‘
os.pardir 获取当前目录的父目录字符串名:(‘..‘)
>>> os.pardir ‘..‘
os.makedirs(‘目录1/目录2‘) 可生成多层递归目录(相当于linux下mkdir -p)
>>> os.makedirs(‘test/a1‘) >>> os.listdir() [‘__pycache__‘, ‘account.py‘, ‘commons.py‘, ‘index.py‘, ‘manager.py‘, ‘maopao.py‘, ‘test‘]
os.removedirs(‘目录‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
>>> os.removedirs(‘test/a1‘) >>> os.listdir() [‘__pycache__‘, ‘account.py‘, ‘commons.py‘, ‘index.py‘, ‘manager.py‘, ‘maopao.py‘] >>>
#a目录中除了有一个b目录外,再没有其它的目录和文件。#b目录中必须是一个空目录。 如果想实现类似rm -rf的功能可以使用shutil模块os.mkdir(‘目录‘) 生成单级目录;相当于shell中mkdir 目录
>>> os.mkdir(‘test‘) >>> os.listdir() [‘__pycache__‘, ‘account.py‘, ‘commons.py‘, ‘index.py‘, ‘manager.py‘, ‘maopao.py‘, ‘test‘]
os.rmdir(‘目录‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir
>>> os.rmdir(‘test‘) >>> os.listdir() [‘__pycache__‘, ‘account.py‘, ‘commons.py‘, ‘index.py‘, ‘manager.py‘, ‘maopao.py‘]
os.listdir(‘目录‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove()删除一个文件
os.rename("原名","新名") 重命名文件/目录
>>> os.rename(‘test‘,‘test1‘) >>> os.listdir() [‘__pycache__‘, ‘account.py‘, ‘commons.py‘, ‘index.py‘, ‘manager.py‘, ‘maopao.py‘, ‘test1‘]
os.stat(‘path/filename‘) 获取文件/目录信息
>>> os.stat(‘test1‘) os.stat_result(st_mode=16877, st_ino=2841750, st_dev=16777220, st_nlink=2, st_uid=501, st_gid=20, st_size=68, st_atime=1465982539, st_mtime=1465982462, st_ctime=1465982462) >>>
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
>>> os.sep ‘/‘
os.pathsep 输出用于分割文件路径的字符串
>>> os.pathsep ‘:‘
os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘
>>> os.name ‘posix‘
os.system("linux命令") 运行shell命令,直接显示
>>> os.system(‘uptime‘) 9:38 up 15 mins, 1 user, load averages: 2.24 2.55 2.02 0
os.environ 系统环境变量
>>> os.environ
os其他语法
os.path模块主要用于文件的属性获取, os.path.abspath(path) 返回path规范化的 *os.path.split(path) 将path分割成目录和文件名二元组返回 *os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 *os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False *os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
2、sys模块 用于提供对解释器相关的操作
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.modules 返回系统导入的模块字段,key是模块名,value是模块 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdout.write(‘please:‘) val = sys.stdin.readline()[:-1] sys.modules.keys() 返回所有已经导入的模块名 sys.modules.values() 返回所有已经导入的模块 sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息 sys.exit(n) 退出程序,正常退出时exit(0) sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0 sys.version 获取Python解释程序的 sys.api_version 解释器的C的API版本 sys.version_info ‘final’表示最终,也有’candidate’表示候选,serial表示版本级别,是否有后继的发行 sys.displayhook(value) 如果value非空,这个函数会把他输出到sys.stdout,并且将他保存进__builtin__._.指在python的交互式解释器里,’_’ 代表上次你输入得到的结果,hook是钩子的意思,将上次的结果钩过来 sys.getdefaultencoding() 返回当前你所用的默认的字符编码格式 sys.getfilesystemencoding() 返回将Unicode文件名转换成系统文件名的编码的名字 sys.setdefaultencoding(name)用来设置当前默认的字符编码,如果name和任何一个可用的编码都不匹配,抛出 LookupError,这个函数只会被site模块的sitecustomize使用,一旦别site模块使用了,他会从sys模块移除 sys.builtin_module_names Python解释器导入的模块列表 sys.executable Python解释程序路径 sys.getwindowsversion() 获取Windows的版本 sys.copyright 记录python版权相关的东西 sys.byteorder 本地字节规则的指示器,big-endian平台的值是’big’,little-endian平台的值是’little’ sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息 sys.exec_prefix 返回平台独立的python文件安装的位置 sys.stderr 错误输出 sys.stdin 标准输入 sys.stdout 标准输出 sys.platform 返回操作系统平台名称 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.maxunicode 最大的Unicode值 sys.maxint 最大的Int值 sys.version 获取Python解释程序的版本信息 sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
3.时间模块
1)time模块
时间戳计算机时间的一种表示方式,是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数。
time.time()
>>> import time >>> time.time() 1466041557.853502
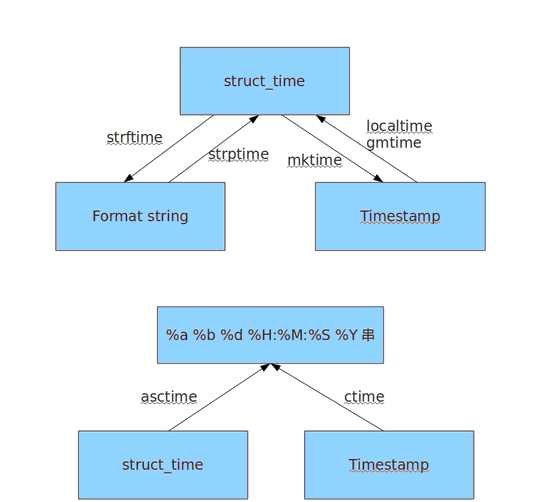
time.ctime()
>>> time.ctime()#将时间戳转化为字符串格式Thu Jun 16 09:49:10 2016,默认是当前系统时间的时间戳 ‘Thu Jun 16 09:49:10 2016‘ >>> time.ctime(time.time()-3600)#ctime可以接收一个时间戳作为参数,返回该时间戳的字符串形式 Wed Thu Jun 16 08:49:33 2016‘ ‘Thu Jun 16 08:49:33 2016‘
time.gtime()
>>> time.gmtime()#将时间戳转化为struct_time格式,默认是当前系统时间戳 time.struct_time(tm_year=2016, tm_mon=6, tm_mday=16, tm_hour=1, tm_min=52, tm_sec=57, tm_wday=3, tm_yday=168, tm_isdst=0) >>> time.gmtime(time.time()-3600) time.struct_time(tm_year=2016, tm_mon=6, tm_mday=16, tm_hour=0, tm_min=53, tm_sec=18, tm_wday=3, tm_yday=168, tm_isdst=0)
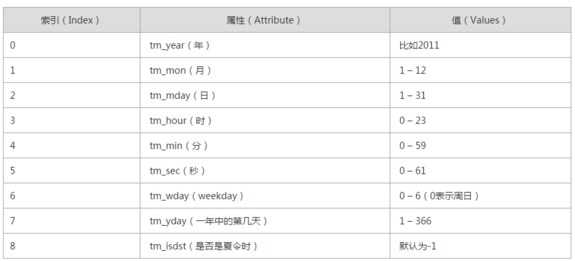
说明: struct_time格式也是一种时间表现形式,其实有点类似列表或元祖的形式 共有九个元素,分别表示,同一个时间戳的struct_time会因为时区不同而不同顺序为 年 tm_year 月 tm_mon 日 tm_mday 小时 tm_hour 分钟 tm_min 秒 tm_sec 周 tm_wday,注意周是从0开始计数的,也就是周一是0 一年中的第几天 tm_yday 是否是夏令日 tm_isdst(也没啥卵用)
time.localtime()
>>> time.localtime()# 同样是将时间戳转化为struct_time,只不过显示的是本地时间,gmtime显示的是标准时间(格里尼治时间) time.struct_time(tm_year=2016, tm_mon=6, tm_mday=16, tm_hour=9, tm_min=55, tm_sec=24, tm_wday=3, tm_yday=168, tm_isdst=0)
time.mktime()
>>> time.mktime(time.localtime())# 将struct_time时间格式转化为时间戳 1466042217.0
time.strftime()
>>> time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())# 将struct_time时间格式转化为自定义的字符串格式
‘2016-06-16 09:58:43‘
说明: "%Y-%m-%d %H:%M:%S"就是我们自定义的字符串个"%Y有点类似于占位符
time.strptime()
>>> time.strptime("2016-06-16","%Y-%m-%d")# 与trftime相反,将字符串格式转化为struct_time格式
time.struct_time(tm_year=2016, tm_mon=6, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=168, tm_isdst=-1)
说明: 第一个参数是时间的字符串形式,第二个参数是第一个参数的格式,格式要与字符串对应 另外时分秒默认是0,可以省略,但是年月日不可以省
time.asctime()
>>> time.asctime(time.localtime())# 将struct_time转化为字符串形式 ‘Thu Jun 16 10:05:42 2016‘
>>> datetime.date.today()# 返回当前日期的字符串形式2016-02-17 datetime.date(2016, 6, 16)
>>> print(datetime.date.today())
2016-06-16
>>> print( datetime.datetime.now())#返回的时间的字符串形式 2016-06-16 10:10:37.612443 >>> print( datetime.datetime.now().timestamp())# 转化为struct_time格式 1466043058.141845
>>> datetime.date.fromtimestamp(time.time()- 3600 *24) datetime.date(2016, 6, 15) >>> print(datetime.date.fromtimestamp(time.time()- 3600 *24)) 2016-06-15
datetime.timedelta()
datetime.timedelta()返回的是一时间间隔对象,常与datetime.datetime.now()合用计算时间
>>> print(datetime.datetime.now() - datetime.timedelta(days = 2)) 2016-06-14 10:27:09.652336
三、递归
递归函数
def d():
return "123"
def c():
r = d()
return r
def b():
r = c()
return r
def a():
r = b()
print(r)
a()
#123
def func(n):
n += 1
if n >=4:
return ‘end‘
return func(n)
r = func(1)
print(r)
#end
#阶乘递归
def func(num):
if num == 1:
return 1
return num*func(num-1)
a = func(7)
print(a)
#5040
实例,通过递归实现二分查找
1 def binary_search(data_list,find_num):
2 mid_pos = int(len(data_list) /2 ) # 获取中间的索引
3 mid_val = data_list[mid_pos] # 获取中间的索引对相应元素,也就是值
4 print(data_list)
5 if len(data_list) >1: # 递归结束条件,也就是规模绩效
6 if mid_val > find_num: # 中间的值比要找的值大,说明在中间值左边
7 print("[%s] should be in left of [%s]" %(find_num,mid_val))
8 binary_search(data_list[:mid_pos],find_num) # 递归自己,继续查找自己的左边(也就是递归要求里的缩小调用规模)
9 elif mid_val < find_num: # 中间的值比要找的值大,说明在中间值左边
10 print("[%s] should be in right of [%s]" %(find_num,mid_val))
11 binary_search(data_list[mid_pos + 1:],find_num)
12 else: # 如果既不大于也不小于说明正好等于
13 print("Find ", find_num)
14
15 else:
16 # 当列表的大小等于1的时候,不在调用自己,结束递归
17 if mid_val == find_num: # 判断最用一个元素是否等于要查找的数
18 print("Find ", find_num)
19 else:
20 print("cannot find [%s] in data_list" %find_num)
21
22 if __name__ == ‘__main__‘:
23 primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103,104]
24 binary_search(primes,5)
25 binary_search(primes,66)
执行结果
1 [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 104] 2 [5] should be in left of [47] 3 [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43] 4 [5] should be in left of [19] 5 [2, 3, 5, 7, 11, 13, 17] 6 [5] should be in left of [7] 7 [2, 3, 5] 8 [5] should be in right of [3] 9 [5] 10 Find 5 11 [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 104] 12 [66] should be in right of [47] 13 [53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 104] 14 [66] should be in left of [79] 15 [53, 59, 61, 67, 71, 73] 16 [66] should be in left of [67] 17 [53, 59, 61] 18 [66] should be in right of [59] 19 [61] 20 cannot find [66] in data_list 复制代码
logging模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误、警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为 debug(), info(), warning(), error() and critical() 5个级别,下面我们看一下怎么用。
最简单用法
>>> import logging
>>> logging.warning("user [Jason] attempted wrong password more than 5 times")
WARNING:root:user [Jason] attempted wrong password more than 5 times
可见,默认情况下python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,
这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET)
默认的日志格式为:日志级别:Logger名称:用户输出消息。
看一下这几个日志级别分别代表什么意思
| Level | When it’s used |
|---|---|
DEBUG |
Detailed information, typically of interest only when diagnosing problems. |
INFO |
Confirmation that things are working as expected. |
WARNING |
An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected. |
ERROR |
Due to a more serious problem, the software has not been able to perform some function. |
CRITICAL |
A serious error, indicating that the program itself may be unable to continue running. |
如果想把日志写到文件里,也很简单
import logging logging.basicConfig(filename=‘test.log‘,level=logging.INFO) logging.debug(‘This message should come to log files‘) logging.info(‘come in this‘) logging.warning(‘hey it came out‘)
其中下面这句中的level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,在这个例子, 第一条日志是不会被纪录的,如果希望纪录debug的日志,那把日志级别改成DEBUG就行了。
感觉上面的日志格式忘记加上时间啦,日志不知道时间怎么行呢,下面就来加上!
import logging logging.basicConfig(format=‘%(asctime)s %(message)s‘, datefmt=‘%m/%d/%Y %I:%M:%S %p‘) logging.warning(‘is when this event was logged.‘) #输出 12/12/2010 11:46:36 AM is when this event was logged.
2.灵活配置日志级别,日志格式,输出位置
logging.basicConfig(level=logging.DEBUG,
format=‘%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s‘,
datefmt=‘%a, %d %b %Y %H:%M:%S‘,
filename=‘test.log‘,
filemode=‘w‘)
logging.debug(‘debug message‘)
logging.info(‘info message‘)
logging.warning(‘warning message‘)
logging.error(‘error message‘)
logging.critical(‘critical message‘)
在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename: 用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode: 文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format: 指定handler使用的日志显示格式。
datefmt: 指定日期时间格式。(datefmt=‘%a, %d %b %Y %H:%M:%S‘,%p)
level: 设置rootlogger(后边会讲解具体概念)的日志级别
stream: 用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。
若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s 用户输出的消息
如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识 了
The logging library takes a modular approach and offers several categories of components: loggers, handlers, filters, and formatters.
import logging
#create logger
logger = logging.getLogger(‘TEST-LOG‘)
logger.setLevel(logging.DEBUG)
# create console handler and set level to debug
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# create file handler and set level to warning
fh = logging.FileHandler("access.log")
fh.setLevel(logging.WARNING)
# create formatter
formatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘)
# add formatter to ch and fh
ch.setFormatter(formatter)
fh.setFormatter(formatter)
# add ch and fh to logger
logger.addHandler(ch)
logger.addHandler(fh)
# ‘application‘ code
logger.debug(‘debug message‘)
logger.info(‘info message‘)
logger.warn(‘warn message‘)
logger.error(‘error message‘)
logger.critical(‘critical message‘)
3.Logger,Handler,Formatter,Filter的概念
logging.basicConfig()(用默认日志格式(Formatter)为日志系统建立一个默认的流处理器(StreamHandler),
设置基础配置(如日志级别等)并加到root logger(根Logger)中)这几个logging模块级别的函数,
另外还有一个模块级别的函数是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root logger)
1).logging库提供了多个组件:Logger、Handler、Filter、Formatter。
Logger 对象提供应用程序可直接使用的接口,
Handler 发送日志到适当的目的地,
Filter 提供了过滤日志信息的方法,
Formatter 指定日志显示格式。
# 创建一个logger logger = logging.getLogger() #创建一个带用户名的logger logger1 = logging.getLogger(‘Jasonlog‘) #设置一个日志级别 logger.setLevel(logging.INFO) logger1.setLevel(logging.INFO) #创建一个handler,用于写入日志文件 fh = logging.FileHandler(‘test.log‘) # 再创建一个handler,用于输出到控制台 ch = logging.StreamHandler() # 定义handler的输出格式formatter formatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘) fh.setFormatter(formatter) ch.setFormatter(formatter) # 给logger添加handler #logger.addFilter(filter) logger.addHandler(fh) logger.addHandler(ch) # 给logger1添加handler #logger1.addFilter(filter) logger1.addHandler(fh) logger1.addHandler(ch) #给logger添加日志 logger.info(‘logger info message‘) logger1.info(‘logger1 info message‘)
用于序列化的两个模块
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
# import json
# dic = {‘k1‘:‘v1‘}
# print(dic,type(dic))
# #将python的基本类型转换为字符串
# result = json.dumps(dic)
# print(result,type(result))
{‘k1‘: ‘v1‘} <class ‘dict‘>
{"k1": "v1"} <class ‘str‘>
s1 = ‘{"k1":123}‘
import json
dic = json.loads(s1) #存入内存中
print(dic,type(dic))
{‘k1‘: 123} <class ‘dict‘>
import requests
import json
response = requests.get(‘http://wthrcdn.etouch.cn/weather_mini?city=北京‘)
response.encoding = ‘utf-8‘
print(response)
#输出
#<Response [200]>
dic = json.loads(response.text)#**使用双引号 print(dic) print(type(dic))
#输出
{‘desc‘: ‘OK‘, ‘data‘: {‘wendu‘: ‘30‘, ‘aqi‘: ‘125‘, ‘city‘: ‘北京‘, ‘forecast‘: [{‘type‘: ‘多云‘, ‘low‘: ‘低温 18℃‘, ‘fengli‘: ‘微风级‘, ‘date‘: ‘5日星期天‘, ‘high‘: ‘高温 30℃‘, ‘fengxiang‘: ‘无持续风向‘}, {‘type‘: ‘多云‘, ‘low‘: ‘低温 20℃‘, ‘fengli‘: ‘微风级‘, ‘date‘: ‘6日星期一‘, ‘high‘: ‘高温 30℃‘, ‘fengxiang‘: ‘无持续风向‘}, {‘type‘: ‘雷阵雨‘, ‘low‘: ‘低温 16℃‘, ‘fengli‘: ‘微风级‘, ‘date‘: ‘7日星期二‘, ‘high‘: ‘高温 24℃‘, ‘fengxiang‘: ‘无持续风向‘}, {‘type‘: ‘晴‘, ‘low‘: ‘低温 21℃‘, ‘fengli‘: ‘微风级‘, ‘date‘: ‘8日星期三‘, ‘high‘: ‘高温 31℃‘, ‘fengxiang‘: ‘无持续风向‘}, {‘type‘: ‘晴‘, ‘low‘: ‘低温 22℃‘, ‘fengli‘: ‘微风级‘, ‘date‘: ‘9日星期四‘, ‘high‘: ‘高温 33℃‘, ‘fengxiang‘: ‘无持续风向‘}], ‘ganmao‘: ‘各项气象条件适宜,发生感冒机率较低。但请避免长期处于空调房间中,以防感冒。‘, ‘yesterday‘: {‘fx‘: ‘无持续风向‘, ‘type‘: ‘阴‘, ‘low‘: ‘低温 19℃‘, ‘fl‘: ‘微风‘, ‘date‘: ‘4日星期六‘, ‘high‘: ‘高温 30℃‘}}, ‘status‘: 1000}
<class ‘dict‘>
import json li = [11,22,33] json.dump(li,open(‘db‘,‘w‘))#序列化 li = json.load(open(‘db‘,‘r‘))##将字符产反序列化,读文件 print(type(li),li)
#输出
#<class ‘list‘> [11, 22, 33]json/pickle
比较json更加适合跨语言,字符串,基本数据类型
class Foo():
def f1(self):
print(‘test‘)
import json
a = Foo
r = json.loads(a)
print(r)
TypeError: the JSON object must be str, not ‘type‘
pickle,python复杂类型序列化,仅适用于python
import pickle li = [11,22,33] r = pickle.dumps(li) print(r) #b‘\x80\x03]q\x00(K\x0bK\x16K!e.‘ result = pickle.loads(r) print(result) #[11, 22, 33] import pickle li = [11,22,33] pickle.dump(li, open(‘db‘,‘wb‘)) result = pickle.load(open(‘db‘,‘rb‘)) print(result) #[11, 22, 33]

User_INFO = {}
def check_login(func):
def inner(*args,**kwargs):
if User_INFO.get(‘is_login‘,None):
ret = func(*args, **kwargs)
return ret
else:
print(‘请登录‘)
return inner
def check_admin(func):
def inner(*args,**kwargs):
if User_INFO.get(‘user_type‘,None) == 2:
ret = func(*args,**kwargs)
return ret
else:
print("无权限查看")
return inner
@check_login
@check_admin
def index():
print("login success")
@check_login
def login():
User_INFO[‘is_login‘] = ‘True‘
print("普通用户登录")
def search():
print("")
def main():
while True:
inp = input("1.登录2.查看3.后台登录")
if inp == ‘1‘:
User_INFO[‘is_login‘] = True
login()
elif inp == ‘2‘:
search()
elif inp == ‘3‘:
User_INFO[‘user_type‘] = 2
index()
main()
常用格式化
生成器迭代器
模块调用,datetime,time,logging,递归,双层装饰器, json,pickle迭代器和生成器
标签:
原文地址:http://www.cnblogs.com/jasonwang-2016/p/5587733.html