标签:
1、sys & os:
我们在写项目的时候,经常遇到模块互相调用的情况,但是在不同的模块下我们通过什么去可以找到这些模块的位置哪?
那就是环境变量!
如何查看当前的环境变量?
a = sys.path
print(a)
[‘D:\\资料\\python\\oldboy13\\jobs\\day5\\conf‘, ‘D:\\资料\\python\\python35\\lib\\site-packages\\requests-2.10.0-py3.5.egg‘, ‘D:\\资料\\python\\oldboy13\\day6‘, ‘D:\\资料\\python\\oldboy13\\jobs\\day4‘, ‘D:\\资料\\python\\oldboy13\\jobs\\day5‘, ‘D:\\资料\\python\\oldboy13‘, ‘D:\\资料\\python\\python35\\python35.zip‘, ‘D:\\资料\\python\\python35\\DLLs‘, ‘D:\\资料\\python\\python35\\lib‘, ‘D:\\资料\\python\\python35‘, ‘D:\\资料\\python\\python35\\lib\\site-packages‘]
在pycharm中我们可以看到这个所有的环境变量
但是此时要注意:
‘D:\\资料\\python\\oldboy13\\day6‘, 这个当前项目的环境变量。
然后我们用命令行找到这个写好上面查看环境变量的py文件,执行以下这个py文件。使用python3 path.py看一下输出的结果
应该是看不到这一个环境变量了,这是怎么回事?
其实这是pycharm里面会自动的将当前项目添加进pycharm这个内置的环境变量中,为了方便使用pycharm的人能够快速的找到当前项目下的模块。
所以此时如果你没有配置环境变量,但是又使用了不同的自定义模块,那么把程序换个环境运行肯定就会报错了。
这是我们怎么处理??
就要将当前项目添加进python程序的环境变量中
这是我们就用到了os和sys的库了
首先说一个 __file__ 知识
a = __file__
b = os.path.abspath(__file__)
D:/资料/python/oldboy13/jobs/day5/conf/test.py
D:\资料\python\oldboy13\jobs\day5\conf\test.py
这两个结果貌似除了斜线不同其他的都相同,都是找到当前文件的绝对路径
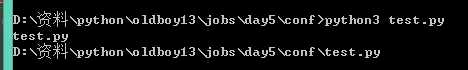
但是我们使用命令行来执行却得出了这个结果
一个是文件名,一个是绝对路径!!!
这又是pycharm搞的鬼,我们就知道了如果想要回去文件的绝对路径就要用第二个os的那个命令
如果要是想取得文件名就可以使用__file__.
好了圆规正传我们继续说一下os,和sys的库
此时我们可以获得当前文件的绝对路径了。我们只要找到这个文件所在的项目,并把这个项目添加到环境变量中 ,那么我们这个项目下的所有位置就都能找到了。
a = __file__ #查看当前文件的文件名,在pycharm中会默认的把当前文件的绝对路径给出来
b = os.path.abspath(__file__) #查看当前文件的绝对路径
print(b)
c = os.path.dirname(b) #查看点钱上一级目录
print(c)
D:\资料\python\oldboy13\jobs\day5\conf\test.py
D:\资料\python\oldboy13\jobs\day5\conf
看到了os.path.dirname 就是可以看到当前文件所在的目录,那么我们再往上看一层目录怎么做哪?
那就再套一层试试
d = os.path.dirname(c)
print(d)
D:\资料\python\oldboy13\jobs\day5\conf\test.py
D:\资料\python\oldboy13\jobs\day5\conf
D:\资料\python\oldboy13\jobs\day5
这就可以看到了再上一层项目的目录啦!!哈哈 只要将这个路径添加进环境变量就要可以了。
sys.path得到的结果就是把所有环境变量都打出来并以列表的形式展示出来
所以我们就可以通过这个列表将上面的到的结果插入到这个列表中就可以了
sys.path.append(d),这下就将这个环境变量放到了进去。
这几个就是sys,os中常用到的命令。
hashlib
在我们保存用户密码的时候不能老用明文来保存,所以我么就要对用户输入的密码做加密
import hashlib #这个库就是用作加密的 obj = hashlib.md5(b"a") #生成一个obj对象,这个对象就是用的md5方法并且用a这个字符串作为防撞库
obj.update(b"123") #给123做加密 ret = obj.hexdigest() #取得加密后的数 print(ret)
场景:
a = "yuanledalexwuproqi"
f = re.findall("alex",a)
alex
这样就找到了a字符串中匹配的文字
元字符:
…… ¥ * + ? . {} [] | () \ ^ $
re.findall()
将所有匹配的通过列表的形式展示出来。
a = "aleuanledalexwuproqi"
f = re.findall("^ale",a)
a = "aleuanledalzexwuproqi"
f = re.findall("al.ex",a)
只能匹配点这个位置的一个任意非换行符的字符。
重复:
*
.* 表示能匹配0-多个
+
+* 表示 1- 多次
?
.* 表示能匹配0-1次
{}
al.{3} 表示能匹配3次
al.{1,5}表示匹配1-5次
al.{1,} 1-多次
al.{,6} 0-多次 只匹配到6次的位置
[]
a[bc]d 匹配到[]里面任意一个字符
a[a-z]d 匹配到a - z 中的任意一个
在[]中的符号:
-:范围
^: 代表非
\d:表示一个数字
所有的元字符在[] 里面不再有特殊意义
\: 取消后面元字符的特殊意以
\后面跟普通字符实现特殊功能:
\d:表示任意10进制数
\D:匹配任何非数字字符,相当于[^0-9]
\s:匹配任何空白字符:它相当于 [\t\n\r\f\v]
\S:匹配任何非空白字符:相当于[^\t\n\r\f\v]
\w:匹配任何字母数字字符:相当于[a-zA-Z0-9_]
\W:匹配任何非字母数字字符:相当于[^a-zA-Z0-9_]
\b:匹配一个单词边界,也就是指单词和空格间的位置
匹配一个位置信息。
比如说a = "I AM TIAN" 我想把单独的单词I找出来
re.findall(r"I\b",a)
\b就是匹配I后面的这个位置的特殊字符信息,r是使用了原生字符
\b后面只要是非字母和数字都能匹配到。
re.match(pattern,string,flags=0)
a= re.match("com","comwww.runcomoob")
此时match得到的结果是一个对象
<_sre.SRE_Match object; span=(0, 3), match=‘com‘>
使用group()就可以获得这个对象的结果
<class ‘str‘> 结果是个字符串
match 还有 几个对象的操作方法
group() 返回被 re匹配的字符串
start() 返回匹配开始的位置
end() 返回匹配结束的位置
span() 返回一个元组包含(开始,结束)的位置,整体的范围
print(a.group(),a.start(),a.end(),a.span())
com 0 3 (0, 3) 结束位置是顾头不顾尾
match只是从字符串的起始位置,如果起始位置没有匹配的,也不会往后匹配。
re.search
a= re.search("com","www.runcomoobcom")
print(a.group(),a.start(),a.end(),a.span())
com 7 10 (7, 10)
search会从字符串的头部开始查找知道找到位置就返回,只会返回第一个匹配到的
re.finditer()
他与findall的结果是一的只不过他是获得了一个对象
a= re.finditer("com","www.runcomoobcom")
for i in a:
a = i.start()
b = i.end()
c = i.span()
d = i.group()
print(a,b,c,d)
7 10 (7, 10) com
13 16 (13, 16) com
re.sub() 匹配替换
a = re.sub("g.t","have","i get a,i got b,i gut c",3) 3是最大替换次数
规则 匹配到替换成什么 字符串
print(a)
i have a,i have b,i have c
a = re.subn("g.t","have","i get a,i got b,i gut c",2)
print(a)
(‘i have a,i have b,i gut c‘, 2)
subn 和sub 结果是一样的,但是多现实了一个替换次数
re.split()
a = "one1two2three3four4"
c = re.split(r"\d+",a)
print(c)
[‘one‘, ‘two‘, ‘three‘, ‘four‘, ‘‘]
将匹配到的进行分割
re.compile()
a = "jgood is a handsome boy, he is cool, clever, and so on ...."
ret = re.compile(r"\W*oo\W*")
print(ret.findall(a))
[‘oo‘, ‘oo‘]
compile 将规则编译成为一个对象
标志位:
re.I 使匹配对大小写不敏感
re.L 做本地化识别(locale-aware)匹配
re.M 多行匹配,影响^ 和 $
re.S 使. 匹配包括换行在内的所有字符
re.U 根据unicode字符集解析字符,这个标志影响 \w,\W,\b,\B
re.X 该标志通过给与你更灵活的格式以便你讲政策表达式写的更易于理解
a = "asd\nadf"
b = re.findall("d.a",a)
print(b)
[]
此时是匹配不到 d\na的,因为. 不能匹配 \n换行符的。
如果想匹配就要加上上面的表示为 re.S了
a = "asd\nadf"
b = re.findall("d.a",a,re.S)
print(b)
[‘d\na‘]
原声字符串之转译:
f = open("D:\abc.txt")
在python中这样打开就会报错
如果我们想打开的话就要写一个转译符号
f = open(r"D:\abc.txt")
这样就把 \这个特殊含义转掉了
因为在python解释器里面 \a 本身也有自己的意思,所以解释器解释到这步的时候就把\a给解释成python里面的 响铃符了
这是我们就要使用原声字符串的形式了,就是前面+r 或者将\a取消含义,\\a
上面说的是我们想要的是一个字符串,那么我们如果在python中调用re模块,怎么处理
a = "adaf\comnf"
如果我们想匹配 \com 怎么办?
抛开解释器,单纯的re中
b = re.findall("\\com",a)
这样就可以了,因为\本身就是转译作用如果不再加个\,我们只能是认为将c转译,不是找\c这个字符
但是我们这样的结果只是找到了com,因为中间还有一层python解释器
在python解释器中\也有特殊意义,所以我们要想传递一个\进入到re中也需要一个\+\ 所以的到的结果就是
b = re.findall("\\\com",a)
print(b)
[‘\\com‘]
咦?怎么是2个??
因为在python中看到的就是2个。
分组
将已经匹配到的结果再去匹配一下相应的数值
a = "has adaf\comnf"
b = re.match("h\w+",a) #将匹配到的输出
b = re.match("h(\w+)",a) #将匹配到的输出,但是我们只要分组中的
b = re.match("h(?P<name>\w+)",a) #将匹配到的变为velvet,前面?P<nane>就是起一个key
print(b.group())
print(b.groups())
print(b.groupdict())
has
(‘as‘,)
{‘name‘: ‘as‘}
re.findall("")
a = "hasabba asdfaf halabba 91293jf"
b = re.findall("h(\w+)(ab)ba",a)
print(b)
[(‘as‘, ‘ab‘), (‘al‘, ‘ab‘)]
findall会将所有匹配的找到,分组是从找到的结果中将想要的挑选出来
re.sub 里面分组是不生效的
re.split()
a = "hello abc asdfaf abc ;kjlk;jadf asdfabcaf"
b = re.split("(abc)",a)
print(b)
[‘hello ‘, ‘abc‘, ‘ asdfaf ‘, ‘abc‘, ‘ ;kjlk;jadf asdf‘, ‘abc‘, ‘af‘]
本应该split以abc为分割,不取abc,由于分组的原因,将abc取回来了。
如果括号内再匹配括号呢?
a = "hello abc asdfaf abc ;kjlk;jadf asdfabcaf"
b = re.split("(a(b)c)",a)
print(b)
[‘hello ‘, ‘abc‘, ‘b‘, ‘ asdfaf ‘, ‘abc‘, ‘b‘, ‘ ;kjlk;jadf asdf‘, ‘abc‘, ‘b‘, ‘af‘]
哪分组就是由外向内逐个匹配。分别获取。
标签:
原文地址:http://www.cnblogs.com/python-way/p/5577274.html