标签:
20160616更新
1. SQLite PRAGMA:可以用在 SQLite 环境内控制各种环境变量和状态标志。
一个 PRAGMA 值可以被读取,也可以根据需求进行设置。
(1)读取语法:只需要提供该 pragma 的名字
PRAGMA pragma_name;
(2)设置语法:
PRAGMA pragma_name = value;
(3)举几个例子:pragma.txt
详情请参考:http://www.runoob.com/sqlite/sqlite-pragma.html
pragma auto_vacuum; -- 这里是查看
pragma cache_size;
pragma case_sensitive_like;
pragma count_changes;
pragma database_list;
pragma encoding;
pragma freelist_count;
pragma auto_vacuum = FULL; -- 这里是设置
pragma cache_size = 10;
pragma case_sensitive_like = true;
pragma count_changes = true;
2. SQLite 约束:约束是在表的数据列上强制执行的规则
约束可以是列级或表级。列级约束仅适用于列,表级约束被应用到整个表
(1)以下是在 SQLite 中常用的约束
NOT NULL 约束:确保某列不能有 NULL 值。
DEFAULT 约束:当某列没有指定值时,为该列提供默认值。
UNIQUE 约束:确保某列中的所有值是不同的。
PRIMARY Key 约束:唯一标识数据库表中的各行/记录。
CHECK 约束:CHECK 约束确保某列中的所有值满足一定条件
(2)primary key约束:
PRIMARY KEY 约束唯一标识数据库表中的每个记录。
在一个表中可以有多个 UNIQUE 列,但只能有一个主键。
在设计数据库表时,主键是很重要的。主键是唯一的 ID。
在 SQLite 中,主键可以是 NULL,这是与其他数据库不同的地方。
主键是表中的一个字段,唯一标识数据库表中的各行/记录。主键必须包含唯一值。主键列不能有 NULL 值。
一个表只能有一个主键,它可以由一个或多个字段组成。当多个字段作为主键,它们被称为复合键。
如果一个表在任何字段上定义了一个主键,那么在这些字段上不能有两个记录具有相同的值。
(3)实例: constraint.txt
create table tab_test
(
ID INT PRIMARY KEY NOT NULL, -- 主键 非空
NAME TEXT NOT NULL UNIQUE, -- 非空, 不相等
AGE INT CHECK(AGE > 0), -- check约束,AGE必须大于0
ADDRESS CHAR(50),
SALARY REAL DEFAULT 5000.00 -- 默认约束
);
(4)删除约束:在 SQLite 中,ALTER TABLE 命令允许用户重命名表,或向现有表添加一个新的列。重命名列,删除一列,或从一个表中添加或删除约束都是不可能的。
3. SQLite joins:用于结合两个或多个数据库中表的记录。JOIN 是一种通过共同值来结合两个表中字段的手段
(1)主要有三种连接方式:
交叉连接 - CROSS JOIN
内连接 - INNER JOIN
外连接 - OUTER JOIN
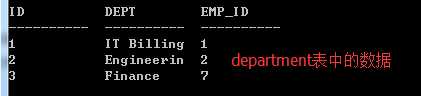
(2)为了练习需要新建一个表: create_department.txt
create table department(
ID INT PRIMARY KEY NOT NULL,
DEPT CHAR(50) NOT NULL,
EMP_ID INT NOT NULL );
-- 插入一些数据
insert into department values(1, ‘IT Billing‘, 1);
insert into department values(2, ‘Engineering‘, 2);
insert into department values(3, ‘Finance‘, 7);
select * from department;

(3)交叉连接:把第一个表的每一行与第二个表的每一行进行匹配。如果两个输入表分别有 x 和 y 列,则结果表有 x*y 列。有时会特别庞大
语法:
SELECT ... FROM table1 CROSS JOIN table2 ...
(4)内连接 inner join:根据连接谓词结合两个表(table1 和 table2)的列值来创建一个新的结果表。
查询会把 table1 中的每一行与 table2 中的每一行进行比较,找到所有满足连接谓词的行的匹配对。
为了避免冗余,并保持较短的措辞,可以使用 USING 表达式声明内连接(INNER JOIN)条件。这个表达式指定一个或多个列的列表:
SELECT ... FROM table1 JOIN table2 USING ( column1 ,... ) ...
自然连接(NATURAL JOIN)类似于 JOIN...USING,只是它会自动测试存在两个表中的每一列的值之间相等值:
SELECT ... FROM table1 NATURAL JOIN table2...
语法:
SELECT ... FROM table1 [INNER] JOIN table2 ON conditional_expression ...
(5)外连接 outer join:虽然 SQL 标准定义了三种类型的外连接:LEFT、RIGHT、FULL,但 SQLite 只支持 左外连接(LEFT OUTER JOIN)。
外连接(OUTER JOIN)声明条件的方法与内连接(INNER JOIN)是相同的,使用 ON、USING 或 NATURAL 关键字来表达。
最初的结果表以相同的方式进行计算。一旦主连接计算完成,外连接(OUTER JOIN)将从一个或两个表中任何未连接的行合并进来,外连接的列使用 NULL 值,将它们附加到结果表中。
为了避免冗余,并保持较短的措辞,可以使用 USING 表达式声明外连接(OUTER JOIN)条件。这个表达式指定一个或多个列的列表:
SELECT ... FROM table1 LEFT OUTER JOIN table2 USING ( column1 ,... ) ...
语法:
SELECT ... FROM table1 LEFT OUTER JOIN table2 ON conditional_expression ...
(6)实例: join.txt
-- 交叉连接,表1与表2的所有列进行一一匹配
select EMP_ID, NAME, DEPT from company cross join department;
-- 内连接,满足连接谓词时就生成一个新的结果
select EMP_ID, NAME, DEPT from company inner join department on company.ID = department.EMP_ID;
-- 左外连接,从一个或两个表中任何未连接的行合并进来,外连接的列使用 NULL 值,将它们附加到结果表中。
select EMP_ID, NAME, DEPT from company left outer join department on company.ID = department.EMP_ID;
结果:
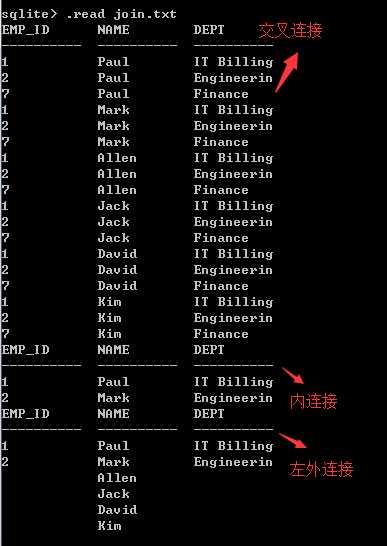
(7)比较:(不知道这样算不算正确,我也不是理解的太深刻)
交叉连接后结果非常多,慎用
左外连接会填充NULL,内连接不会
4, SQLite Unions子句:用于合并两个或多个 SELECT 语句的结果,不返回任何重复的行。
为了使用 UNION,每个 SELECT 被选择的列数必须是相同的,相同数目的列表达式,相同的数据类型,并确保它们有相同的顺序,但它们不必具有相同的长度
(1)UNION基本语法:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
(2)union all基本语法:用于结合两个 SELECT 语句的结果,包括重复行。适用于 UNION 的规则同样适用于 UNION ALL 运算符。
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION ALL
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
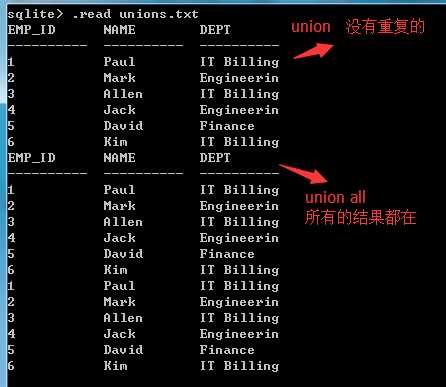
(3)实例:unions.txt
select EMP_ID,NAME,DEPT from company inner join department -- 内连接
on company.ID = department.EMP_ID
UNION
select EMP_ID,NAME,DEPT from company left outer join department -- 左外连接
on company.ID = department.EMP_ID;
select EMP_ID,NAME,DEPT from company inner join department -- 内连接
on company.ID = department.EMP_ID
UNION ALL
select EMP_ID,NAME,DEPT from company left outer join department -- 左外连接
on company.ID = department.EMP_ID;
5. SQLite NULL值:
SQLite 的 NULL 是用来表示一个缺失值的项。表中的一个 NULL 值是在字段中显示为空白的一个值。
带有 NULL 值的字段是一个不带有值的字段。NULL 值与零值或包含空格的字段是不同的,理解这点是非常重要的。
(1)带有 NULL 值的字段在记录创建的时候可以保留为空。
(2)NULL 值在选择数据时会引起问题,因为当把一个未知的值与另一个值进行比较时,结果总是未知的,且不会包含在最后的结果中。
6. SQLite 别名:暂时把表或列重命名为另一个名字,这被称为别名。
重命名是临时的改变,在数据库中实际的表的名称不会改变。
列别名用来为某个特定的 SQLite 语句重命名表中的列。
(1)语法:
表 别名的基本语法如下:
SELECT column1, column2....
FROM table_name AS alias_name
WHERE [condition];
列 别名的基本语法如下:
SELECT column_name AS alias_name
FROM table_name
WHERE [condition];
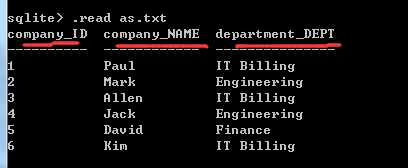
(2)实例:
select C.ID as company_ID, C.NAME as company_NAME, D.DEPT as department_DEPT -- 这里是给列取别名
from company as C , department as D -- 这里是给表取别名
where C.ID = D.EMP_ID; - 并且使用
(3)效果:
7. SQLite触发器: Trigger SQLite 的触发器是数据库的回调函数,它会自动执行/指定的数据库事件发生时调用。
(1)要点:
SQLite 的触发器(Trigger)可以指定在特定的数据库表发生 DELETE、INSERT 或 UPDATE 时触发,或在一个或多个指定表的列发生更新时触发。
SQLite 只支持 FOR EACH ROW 触发器(Trigger),没有 FOR EACH STATEMENT 触发器(Trigger)。因此,明确指定 FOR EACH ROW 是可选的。
WHEN 子句和触发器(Trigger)动作可能访问使用表单 NEW.column-name 和 OLD.column-name 的引用插入、删除或更新的行元素,其中 column-name 是从与触发器关联的表的列的名称。
如果提供 WHEN 子句,则只针对 WHEN 子句为真的指定行执行 SQL 语句。如果没有提供 WHEN 子句,则针对所有行执行 SQL 语句。
BEFORE 或 AFTER 关键字决定何时执行触发器动作,决定是在关联行的插入、修改或删除之前或者之后执行触发器动作。
当触发器相关联的表删除时,自动删除触发器(Trigger)。
要修改的表必须存在于同一数据库中,作为触发器被附加的表或视图,且必须只使用 tablename,而不是database.tablename。
一个特殊的 SQL 函数 RAISE() 可用于触发器程序内抛出异常。
(2)语法:
CREATE TRIGGER trigger_name [BEFORE|AFTER] event_name
ON table_name
BEGIN
-- Trigger logic goes here....
END;
event_name 可以是在所提到的表 table_name 上的 INSERT、DELETE 和 UPDATE 数据库操作。您可以在表名后选择指定 FOR EACH ROW。
以update为例:
CREATE TRIGGER trigger_name [BEFORE|AFTER] UPDATE OF column_name
ON table_name
BEGIN
-- Trigger logic goes here.... -- 这里是执行update时的操作,可以写进一张表里
END;
(3)实例:以插入数据为例:
先创建一张表,存储插入信息: create_audit.txt
CREATE TABLE AUDIT(
EMP_ID INT NOT NULL,
ENTRY_DATE TEXT NOT NULL
);
再创建触发器: trigger.txt
create trigger audit_log after insert
on company
begin
insert into audit (EMP_ID, ENIRY_DATA) values(new.ID, datetime(‘now‘)); -- 每次插入数据,就往audit中插入一条数据
end;
注意: new代表新的, 还可以用old,表示操作之前的信息。
这个例子中,如果insert换成delete,插入时就必须用 old.ID了,因为记录已经被删除了,new已经没有意义了。
再把company表中的数据清空:
delete from company;
最后运行插入数据: insert_company.txt
可以看到audit中的数据:
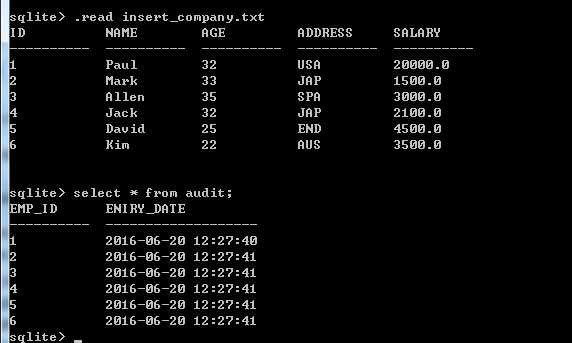
(4)列出 触发器:列出所有的触发器
select name from sqlite_master where type = ‘trigger‘; -- 列出所有的触发器
select name from sqlite_master where type = ‘trigger‘ AND tbl_name=‘company‘; -- 找出特定表中的触发器
(5)删除触发器:drop命令
如: drop trigger trigger_name;
8.SQLite 索引:是一种特殊的查找表,数据库搜索引擎用来加快数据检索
索引是一个指向表中数据的指针。一个数据库中的索引与一本书后边的索引是非常相似的。
索引有助于加快 SELECT 查询和 WHERE 子句,但它会减慢使用 UPDATE 和 INSERT 语句时的数据输入。
索引可以创建或删除,但不会影响数据。
(1)基本语法
CREATE INDEX index_name ON table_name;
(2)
单列索引:单列索引是一个只基于表的一个列上创建的索引。基本语法如下:
CREATE INDEX index_name
ON table_name (column_name);
唯一索引:使用唯一索引不仅是为了性能,同时也为了数据的完整性。唯一索引不允许任何重复的值插入到表中。基本语法如下
CREATE INDEX index_name
on table_name (column_name);
组合索引:组合索引是基于一个表的两个或多个列上创建的索引
CREATE INDEX index_name
on table_name (column1, column2);
隐式索引:隐式索引是在创建对象时,由数据库服务器自动创建的索引。索引自动创建为主键约束和唯一约束。
(3)实例: index.txt
在company的SALARY上建立索引:
CREATE INDEX salary_index ON COMPANY (SALARY);
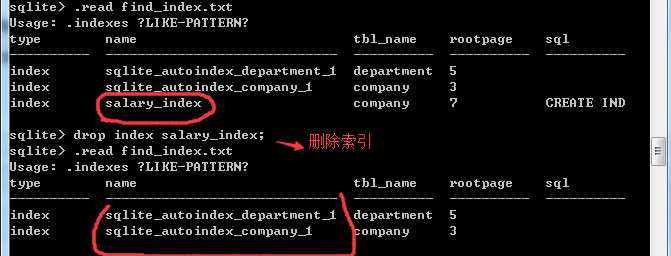
(4)实例: find_index.txt
.indices company -- .indices命令 列出company表上可用的所有的索引
select * from sqlite_master where type=‘index‘; -- 列出数据库范围内的所有索引
(5)删除索引: drop index index_name;
(6)什么情况下要避免使用索引:
索引不应该使用在较小的表上。
索引不应该使用在有频繁的大批量的更新或插入操作的表上。
索引不应该使用在含有大量的 NULL 值的列上。
索引不应该使用在频繁操作的列上。
9、SQLite index by:"INDEXED BY index-name" 子句规定必须需要命名的索引来查找前面表中值
如果索引名 index-name 不存在或不能用于查询,然后 SQLite 语句的准备失败。
(1)语法:
SELECT|DELETE|UPDATE column1, column2...
from table_name
INDEXED BY (index_name)
WHERE (CONDITION);
(2)、实例:indexby.txt
create index salary_index on company(SALARY); -- 创建索引
select * from company INDEXED BY salary_index where SALARY > 4000; -- 利用索引进行查询

标签:
原文地址:http://www.cnblogs.com/xcywt/p/5592358.html