标签:
一、代码
package com.sgcc.hj
import java.sql.DriverManager
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by user on 2016/6/17.
*/
object JdbcTest {
def main(args: Array[String]) {
val conf = new SparkConf()
val sc = new SparkContext(conf)
val rdd = new JdbcRDD(
sc,
() => {
Class.forName("oracle.jdbc.driver.OracleDriver").newInstance()
DriverManager.getConnection("jdbc:oracle:thin:@172.16.222.112:1521:pms", "scyw", "scyw")
},
"SELECT * FROM MW_APP.CMST_AIRPRESSURE WHERE 1 = ? AND rownum < ?",
1, 10, 1,
r => (r.getString(1),r.getString(2),r.getString(5)))
rdd.collect().foreach(println)
sc.stop()
}
}
二、运行截图
命令:spark-submit --master yarn --jars /opt/test/data/oracle.jdbc_10.2.0.jar --name OracleRead --class com.sgcc.hj.JdbcTest--executor-memory 1G /opt/test/data/sparktest.jar(注意这里依赖了oracle的jar包要在加上)
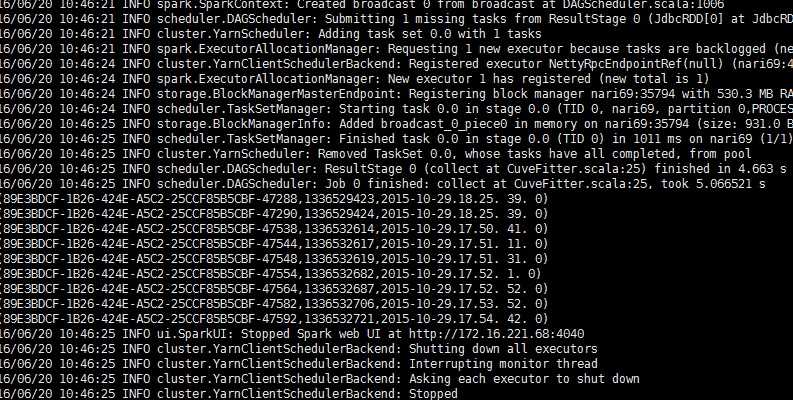
三、答疑
1、官方文档地址:
https://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.rdd.JdbcRDD
2、JdbcRdd中的构造参数:
前面三个就不解释了,一眼就可以看懂,后面三个数字,前两个表示SQL中的参数,必须是LONG型,而且必须有,这个是Spark源码要求的,如果没有LONG型的条件,可以使用1=1这种参数(第三个参数要为1);第三个参数表示分区查询,例如给定前两个参数为1和20,第三个参数为2,那么SQL就会执行两次,第一次参数为(1, 10),第二次为(11, 20);最后一个参数是函数,这里表示把一条记录里的第1、2、5个字段组成三元组,当然也可以变成别的形式。
Spark通过JdbcRdd连接Oracle数据库(scala)
标签:
原文地址:http://www.cnblogs.com/kevin19900306/p/5602563.html