标签:
第 18 章 高可用设计之 MySQL 监控
前言:
一个经过高可用可扩展设计的 MySQL 数据库集群,如果没有一个足够精细足够强大的监控系统,同样可能会让之前在高可用设计方面所做的努力功亏一篑。一个系统,无论如何设计如何维护,都无法完全避免出现异常的可能,监控系统就是根据系统的各项状态的分析,让我们能够尽可能多的提前预知系统可能会出现的异常状况。即使没有及时发现将要发生的异常,也要在异常出现后的第一时间知道系统已经出现异常,否则之前的设计工作很可能就白费了。
18.1 监控系统设计
系统监控在很多人眼中是一个没有多少技术含量的事情,其实并不是这样的。且不说一个大型网站的所有设备的监控,就仅仅只是搭建一个比较完善的几十台 MySQL 集群系统的监控,很可能就会让很多人束手无策,或者功能不够完善。
其实一个完善的大型集群系统的监控系统,和少数几台主机的监控是有很大差别的。少数机台主机的监控在大多数时候可以通过几个简单的脚本(Shell或者Perl等),发发邮件,再高一点的报警信息发发手机短信,基本就搞定了。监控点少,发出的信息量也少。很多状态信息甚至都可以通过维护人员登录到主机上面来定时 Check 即可。可如果有上百台主机,仍然仅仅依靠在每台主机上面部署几个简单的脚本的方式来进行监控,后期的管理维护成本就会非常高了。
当 MySQL 主机达到一定规模之后,我们基本上很难通过人工到各个主机上面来定时检查各自的状态,不论是运行状态还是性能状态。甚至都不能像只有少数 MySQL 主机的时候那样简单的通过发送邮件的方式将相关信息发出。毕竟,量大了之后,检查邮件的时间成本也是很大的。这时候就需要我们进行统一的监控信息采集、分析、存储、处理系统来帮助我们过滤掉可以忽略的正常信息,并画出相关信息的趋势图,以帮助判断系统的运行状况和发展趋势。
所以,MySQL 分布式集群的监控系统整体架构体系应该如下图所示:
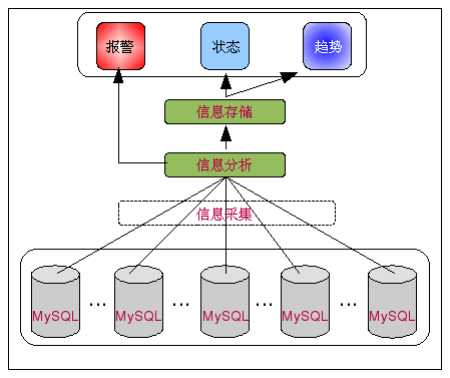
1、信息采集
信息采集可以是一个统一的模块以主动的方式从各个 MySQL 主机上面来获取信息然后存放到监控信息存储中心,也可以是分布在各个 MySQL 主机上面的模块以被动的方式来反向将相关数据推向监控信息存储中心。
一般来说,较小规模的监控点可以采用轮询的方式主动采集数据,但是当监控点达到一定规模以后,轮询的主动采集方式可能就会遇到一定的性能瓶颈和信息延时问题,尤其是当需要采集的数据比较多的时候尤为突出。而如果要采用从各个 MySQL 节点进行被动的推送,则可能需要开发能够支持网络通信的监控程序,使采集的信息能够顺利的到达信息分析模块以即时得到分析,成本会稍微高一些。
不论是采用主动还是被动的方式来进行数据采集,我们都需要在监控主机上面部署采集相关信息的程序或脚本,包括主机信息和数据库信息。
2、信息分析
当前端采集模块的监控程序获取到 MySQL 主机当前的各种状态信息之后,分析模块需要实时地对数据进行分析,识别出系统是正常还是异常,如果是异常,就必须通过相关机制立即发出报警通知,并将信息发送到存储模块进行持久化。如果正常,则不需要进行任何处理就可以将数据传递到存储模块持久化。对信息分析模块来讲,最重要的事情就是处理及时、准确,当监控点到达一定的量之后,性能可能会成为瓶颈。
3、信息存储
存储监控程序采集的信息也是一件非常重要的事情,因为不论是查看当前状态,还是绘制趋势图,都需要用到这些信息。此外还有一个非常重要的原因就是通过对积累下来的这些监控信息的分析挖掘,为系统的容量规划和性能模型设计带来非常大的帮助。
4、信息处理
最后根据采集到的各种状态、性能信息,通过应用相应规则进行分析挖掘运算,绘制出各种状态的趋势图以供维护人员查看。此外,通过对各种趋势的分析,发掘出业务发展与数据库负载之间的关系,以及与主机硬件的关系。这些关系数据,对于系统发展规划的制定将是非常有意义的。
18.2 健康状态监控
健康状态信息一般来说还是比较简单的,但也是非常重要的。因为对于监控来说,需要了解的健康状态基本上也就只有“正常”或“不正常”这两种。下面分别从主机状态信息和数据库状态信息来分别介绍一下。
18.2.1 主机健康状态监控
在数据库运行环境,需要关注的主机状态主要有网络通信、系统软硬件错误、磁盘空间、内存使用,进程数量等。
● 网络通信:网络通信基本上可以说是最容易检测的了,基本上只需要通过网络 ping 就可以获知是否正常。如果还不放心,或者所属网段内禁用了 ping,也可以从监控主机进行固定端口的 telnet 尝试或者 ssh 登录尝试。由于网络出现故障的时候被动的信息采集方式也会失效(无法与外界通信),所以网络通信的检测主要还是依靠主动检测。
● 系统软硬件错误:系统软硬件错误,一般只能通过检测各种日志文件的信息来实现, 如主机的系统日志中基本上都会记录下 OS 能够检测到的大部分错误信息,如硬件错误,IO 错误等等。我们一般使用文本监控软件,如 sec、logwatch 等日志监控专用软件,通过配置相应的匹配规则,从日志文件中捕获满足条件的错误信息,再发送给信息分析模块。
● 磁盘空间:对于磁盘空间的使用状况监控,我们通过最简单的 shell 脚本就可以轻松搞定,得出系统中各个分区的当前使用量,剩余可用空间。积累一定时间段的信息之后,很容易就能得出系统数据量增长趋势。
● 内存使用:系统物理内存使用量的信息采集同样非常简单,只需要一个基本的系统命令“free”,就可以获得当前系统内存总量,剩余使用量,以及文件系统的buffer和cache两者使用量。而且,除了物理内存使用情况,还可以得到 swap 使用量。
通过shell脚本对这些输出信息进行简单的处理,即可获得足够的信息。当然,如果你希望获取更多的信息,如当前系统使用内存最多的进程,可能还需要借助其他命令(如:top)才能得到。当然,不同的 OS 在输出值的处理方面可能会稍有区别,
● 进程数量:系统进程总数,或者某个用户下的进程数,都可以通过“ps”命令经过
简单的处理来获得。如获取mysql用户下的进程总数:
ps -ef | awk ‘{print $1}‘ | grep "mysql" | grep -v "grep" | wc -l
如要获得更为详细的某个或者某类进程的信息,同样可以根据上述类似命令得到。
18.2.2 数据库健康状态信息
除了主机的状态信息之外,MySQL Server 自身也有很多的状态信息需要监控。下面就详细介绍一下 MySQL Server 需要监控的内容以及监控方法。
● 服务端口(3306):MySQL 端口是一个必不可少的监控项,因为这直接反应了 MySQL Server 是否能够正常为外部请求提供服务。有些时候从主机层面来检查 MySQL 可能很正常,可外部应用却无法通过 TCP/IP 连接上 MySQL。产生这种现象的原因可能有多种,如网络防火墙的问题,网络连接问题,MySQL Server 所在主机的网络设置问题,以及 MySQL 本身问题都可能造成上述现象。
服务端口状态的监控和主机网络连接的监控同样非常简单,只需要对 3306 端口进行 telnet 尝试即可。通过对 3306 端口的 telnet 尝试,同时还可以完成对主机网络状况的监控。
● socket文件:对于有些环境来说,socket 的状态监控可能并不如网络服务端口的监控重要,因为很多 MySQL Server 的连接并不会通过本地 socket 进行连接。但是也有不少小型应用(或者某些特殊的应用)还是和 MySQL 数据库处于同一台主机上,并通过本地 socket 连接。另外,不少本地被动监控的信息采集脚本也是通过本地 socket 来连接 MySQL Server。
本地 socket 的监控最好是通过本地 socket 的实际连接尝试的方式,虽然也可以通过检测 socket 文件是否存在来监控,但是即使 socket 文件确实存在,也并不一定就可以确保能够通过 socket 正常登录。毕竟,在某些异常情况下,socket 文件存在并不代表就可以正常使用。
● mysqld 和 mysqld_safe 进程:mysqld 进程是 MySQL Server最核心的进程。
mysqld 进程 crash 或者出现异常,MySQL Server 基本上也就无法正常提供服务了。当然,如果我们是通过 mysqld_safe 来启动 MySQL Server,则 mysqld_safe 会帮助我们来监控 mysqld 进程的状态,当 mysqld 进程crash 之后,mysqld_safe 会马上帮助我们重启 mysqld 进程。但前提是我们必须通过mysqld_safe 来启动 MySQL Server,这也是 MySQL AB 强烈推荐的做法。如果我们通过 mysqld_safe 来启动 MySQL Server,那么我们也必须对 mysqld_safe 进程进行监控。
无论是 mysqld 还是 mysqld_safe 进程的监控,都可以通过 ps 命令来得到实现:
ps -ef | grep "mysqld_safe" | grep -v "grep" 和 ps -ef | grep "mysqld" | grep -v "mysqld_safe"| grep -v "grep"
● Error log:Error log 的监控目的主要是即时检测 MySQL Server 运行过程中发生的各种错误,如连接异常,系统bug等。
Error log 的监控和系统软硬件状态的监控一样,都是通过对文本文件内容的监控来实现的。同样使用文本监控软件,通过配置各种错误信息的匹配规则来捕获日志文件中的错误信息。
● 复制状态:如果我们的 MySQL 数据库环境使用了 MySQL Replication,就必须增加对 Slave 复制状态的监控。对Slave 的复制状态的监控包括对 IO 线程和 SQL线程二者的运行状态的监控。当然,如果希望能够监控 Replication 更多的信息, 如两个线程各自运行的进度等,同样可以在 Slave 节点上执行相应命令轻松得到, 如下:
sky@localhost : (none) 04:30:38> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Connecting to master
Master_Host: 10.0.77.10
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 196
Relay_Log_File: mysql-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB: example,abc
Replicate_Ignore_DB: mysql,test
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 196
Relay_Log_Space: 106
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
通过如上命令,我们可以获取获取关于 Replication 的各种信息,不论是复制的监控状况,还是复制的进度,都可以很容易的获取。上面输出的各项内容中,最重要的内容就是 Slave_IO_Running 和 Slave_SQL_Running 这两项,分别代表了 IO线程和 SQL 线程的运行状态,如上面的输出就表明 SQL 线程运行正常,但是 IO线程并没有运行。其他各项的详细解释,请参考本书附录。
18.3 性能状态监控
性能状态的监控和健康状态的监控有一定的区别,他所反应出来的主要是系统当前提供服务的响应速度,影响的更多是客户满意度。性能状态的持续恶化,则可能升级为系统不可用,也就是升级为健康状态的异常。如系统的过度负载,可能导致系统的 crash。性能状态的监控同样可以分为主机和数据库层面。
18.3.1 主机性能状态
主机性能状态主要表现在三个方面:CPU、IO以及网络,可以通过以下五个监控量来监控。
● 系统 load值:系统 load 所包含的最关键含义是 CPU 运行等待的数量,也就是侧面反应了 CPU 的繁忙程度。只不过 load 值并不直接等于等待队列中的进程数量。
load 值的监控也非常简单,通过运行 uptime 命令即可获得当前时间之前1秒、5秒和15秒的 load 平均值。
sky@sky:~$ uptime 17:27:44 up 4:12, 3 users, load average: 0.87, 0.66, 0.61
如上面输出内容中的“load average: 0.87, 0.66, 0.61”中的三个数字,分别代表了1秒、5秒和15秒的load平均值。
一般来说,load值在不超过系统物理 cpu数目(或者cpu总核数)之前,系统不会有太大问题。
● CPU 使用率:CPU 使用率和系统 load 值一样,从另一个角度反应出 CPU 的总体繁忙程度,只不过可以反应出更为详细的信息,如当前空闲 的CPU 比率,系统占用的 CPU比率,用户进程占用的 CPU 比率,处于 IO 等待的 CPU 比率等。
CPU 使用率可以通过多种方法来获取,最为常用的方法是使用命令 top 和 vmstat来获取 。当然,不同的 OS 系统上的 top 和 vmstat 的输出可能有些许不同,且输出格式也可能各不一样,如 Linux 下的 top 包含 IO 等待的 CPU 占用律,但是 Solaris 下的 top 就不包含,各位读者朋友请根据自己的 OS 环境进行相应的处理。
● 磁盘 IO 量:磁盘 IO 量直接反应出了系统磁盘繁忙程度,对于数据库这种以 IO操作为主的系统来说,IO 的负载将直接影响到系统的整体响应速度。
磁盘 IO 量同样也可以通过 vmstat 来获取,当然,我们还可以通过iostat 来获得更为详细的系统 IO 信息。包括各个磁盘设备的 iops,每秒吞吐量等。
● swap 进出量:swap 的使用主要表现了系统在物理内存不够的情况下使用虚拟内存的情况。当然,有些时候即使系统还有足够物理内存的时候,也可能出现使用 swap的情况,这主要是由系统内核中的内存管理部分来决定。如果希望系统完全不使用swap,最直接的办法就是关闭 swap。当然,前提条件是我们必须要有足够的物理内存,否则很可能会出现内存不足的错误,严重的时候可能会造成系统 crash。
swap 使用量的总体情况可以通过 free 命令获得,但 free 命令只能获得当前系统 swap 的总体使用量。如果希望获得实时的 swap 使用变化,还是得依赖 vmstat来得到。vmstat 输出信息中包含了每秒 swap 的进出量,当然,不同的 OS 输出可能存在一定的差异。
● 网络流量:作为数据库系统,网络流量也是一个不容忽视的监控点。毕竟数据库系统的数据进出比普通服务器的量还是要大很多的。不论是总体吞吐量还是网络iops,都需要给予一定的关注。当然,一般非数据仓库类型的数据库,网络流量成为瓶颈的可能性还是比较小的。
网络流量的监控很少有系统自带的命令可以直接完成,而需要自行编写脚本或者通过一些第三方软件来获取数据。当然,通过对网络交换机的监控,也可以获得非常详细的网络流量信息。自行编写脚本可以通过调用 ifconfig 命令来计算出基本准确的网络流量信息。第三方软件如 ifstat、iftop和nload 等则是需要另外安装的监控 linux 下网络流量第三方软件,三者各有特点,读者朋友可以根据三款软件官方介绍的功能特点自行选择。
18.3.2 数据库性能状态
MySQL 数据库的性能状态监控点非常之多,其中很多量都是我们不能忽视的必须监控的量,且 90% 以上的内容可以在连接上 MySQL Server 后执行“SHOW /*!50000 GLOBAL */ STATUS” 以及 “SHOW /*!50000 GLOBAL */ VARIABLES” 的输出值获得。需要注意的是上述命令所获得状态值实际上是累计值,所以如果要计算(单位/某个)时间段内的变化量还需要稍加处理,可以在附录中找到两个命令输出值的详细说明。下面看看几项需要重点关注的性能状态:
● QPS(每秒Query 量):这里的 QPS 实际上是指 MySQL Server 每秒执行的 Query 总量,在 MySQL 5.1.30 及以下版本可以通过 Questions 状态值每秒内的变化量来近似表示,而从 MySQL 5.1.31 开始,则可以通过 Queries 来表示。Queries 是在 MySQL 5.1.31 才新增的状态变量。主要解决的问题就是 Questions 状态变量并没有记录存储过程中所执行的 Query(当然,在无存储过程的老版本 MySQL 中则不存在这个区别),而 Queries 状态变量则会记录。二者获取方式:
QPS = Questions(or Queries) / Seconds
获取所需状态变量值:
SHOW /*!50000 GLOBAL */ STATUS LIKE ‘Questions‘
SHOW /*!50000 GLOBAL */ STATUS LIKE ‘Queries‘
这里的 Seconds 是指累计出上述两个状态变量值的时间长度,后面用到的地方也代表同样的意思。
● TPS(每秒事务量): 在 MySQL Server 中并没有直接事务计数器,我们只能通过回滚和提交计数器来计算出系统的事务量。所以,我们需要通过以下方式来得到客户端应用程序所请求的 TPS 值:
TPS = (Com_commit + Com_rollback) / Seconds
如果我们还使用了分布式事务,那么还需要将 Com_xa_commit 和Com_xa_rollback 两个状态变量的值加上。
● Key Buffer 命中率:Key Buffer 命中率代表了 MyISAM 类型表的索引的 Cache 命中率。该命中率的大小将直接影响 MyISAM 类型表的读写性能。Key Buffer 命中率实际上包括读命中率和写命中率两种,MySQL 中并没有直接给出这两个命中率的值,但是可以通过如下方式计算出来:
key_buffer_read_hits = (1 - Key_reads / Key_read_requests) * 100%
key_buffer_write_hits= (1 - Key_writes / Key_write_requests) * 100%
获取所需状态变量值:
sky@localhost : (none) 07:44:10> SHOW /*!50000 GLOBAL */ STATUS
-> LIKE ‘Key%‘;
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
... ...
| Key_read_requests | 10 |
| Key_reads | 4 |
| Key_write_requests | 0 |
| Key_writes | 0 |
+------------------------+-------+
通过这两个计算公式,我们很容易就可以得出系统当前 Key Buffer 的使用情况
● Innodb Buffer 命中率:这里 Innodb Buffer 所指的是innodb_buffer_pool,也就是用来缓存 Innodb类型表的数据和索引的内存空间。类似 Key buffer,我们同样可以根据 MySQL Server 提供的相应状态值计算出其命中率:
innodb_buffer_read_hits=(1- Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests)* 100%
获取所需状态变量值:
sky@localhost : (none) 08:25:14> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE ‘Innodb_buffer_pool_read%‘;
+-----------------------------------+-------+
| Variable_name | Value |
+-----------------------------------+-------+
... ...
| Innodb_buffer_pool_read_requests | 5367 |
| Innodb_buffer_pool_reads | 507 |
+-----------------------------------+-------+
● Query Cache 命中率:如果我们使用了 Query Cache,那么对 Query Cache 命中率进行监控也是有必要的,因为他可能告诉我们是否在正确的使用Query Cache。
Query Cache 命中率的计算方式如下:
Query_cache_hits= (Qcache_hits / (Qcache_hits + Qcache_inserts)) * 100%
获取所需状态变量值:
sky@localhost : (none) 08:32:01> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE ‘Qcache%‘;
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
... ...
| Qcache_hits | 0 |
| Qcache_inserts | 0 |
... ...
+-------------------------+-------+
● Table Cache 状态量:Table Cache 的当前状态量可以帮助我们判断系统参数table_open_cache 的设置是否合理。如果状态变量 Open_tables 与Opened_tables 之间的比率过低,则代表 Table Cache 设置过小,个人认为该值处于 80% 左右比较合适。注意,这个值并不是准确的 Table Cache 命中率。
获取所需状态变量值:
sky@localhost : (none) 08:52:00> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE ‘Open%‘;
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
... ...
| Open_tables | 51 |
... ...
| Opened_tables | 61 |
+--------------------------+-------+
● Thread Cache 命中率:Thread Cache 命中率能够直接反应出我们的系统参数thread_cache_size 设置的是否合理。一个合理的 thread_cache_size 参数能够节约大量创建新连接时所需要消耗的资源。Thread Cache 命中率计算方式如下:
Thread_cache_hits = (1 - Threads_created / Connections) * 100%
获取所需状态变量值:
sky@localhost : (none) 08:57:16> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE ‘Thread%‘;
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
... ...
| Threads_created | 3 |
... ...
+-------------------+-------+
4 rows in set (0.01 sec)
sky@localhost : (none) 09:01:33> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE ‘Connections‘;
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Connections | 11 |
+---------------+-------+
正常来说,Thread Cache 命中率要在 90% 以上才算比较合理。
● 锁定状态:锁定状态包括表锁和行锁两种,我们可以通过系统状态变量获得锁定总次数,锁定造成其他线程等待的次数,以及锁定等待时间信息。
sky@localhost : (none) 09:01:44> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE ‘%lock%‘;
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
... ...
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 0 |
| Innodb_row_lock_time_avg | 0 |
| Innodb_row_lock_time_max | 0 |
| Innodb_row_lock_waits | 0 |
... ...
| Table_locks_immediate | 44 |
| Table_locks_waited | 0 |
+-------------------------------+-------+
通过上述系统变量,我们可以得出表锁总次数,其中造成其他现线程等待的次数。同时还可以得到非常详细的行锁信息,如行锁总次数,行锁总时间,每次行锁等待时间,行锁造成最大等待时间以及当前等待行锁的线程数。通过对这些量的监控,我们可以清晰的了解到系统整体的锁定是否严重。如当 Table_locks_waited 与 Table_locks_immediate 的比值较大,则说明我们的表锁造成的阻塞比较严重,可能需要调整 Query语句,或者更改存储引擎,亦或者需要调整业务逻辑。当然,具体改善方式必须根据实际场景来判断。而 Innodb_row_lock_waits 较大,则说明 Innodb 的行锁也比较严重,且影响了其他线程的正常处理。同样需要查找出原因并解决。造成 Innodb 行锁严重的原因可能是 Query 语句所利用的索引不够合理(Innodb 行锁是基于索引来锁定的),造成间隙锁过大。也可能是系统本身处理能力有限,则需要从其他方面(如硬件设备)来考虑解决。
● 复制延时量:复制延时量将直接影响了 Slave 数据库处于不一致状态的时间长短。
如果我们是通过 Slave 来提供读服务,就不得不重视这个延时量。我们可以通过在 Slave 节点上执行“SHOW SLAVE STATUS”命令,取 Seconds_Behind_Master 项的值来了解 Slave 当前的延时量(单位:秒)。当然,该值的准确性依赖于复制是否处于正常状态。每个环境下的 Slave 所允许的延时长短与具体环境有关,所以复制延时多长时间是合理的,只能由读者朋友根据各自实际的应用环境来判断。
● Tmp table 状况:Tmp Table 的状况主要是用于监控 MySQL 使用临时表的量是否过多,是否有临时表过大而不得不从内存中换出到磁盘文件上。临时表使用状态信息可以通过如下方式获得:
sky@localhost : (none) 09:27:28> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE ‘Created_tmp%‘;
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Created_tmp_disk_tables | 1 |
... ...
| Created_tmp_tables | 46 |
+-------------------------+-------+
从上面的状态信息可以了解到系统使用了46次临时表,其中有1次临时表比较大, 无法在内存中完成,而不得不使用到磁盘文件。如果 Created_tmp_tables 非常大,则可能是系统中排序操作过多,或者是表连接方式不是很优化。而如果是Created_tmp_disk_tables 与 Created_tmp_tables 的比率过高,如超过 10%,则我们需要考虑是否 tmp_table_size 这个系统参数所设置的足够大。当然,如果系统内存有限,也就没有太多好的解决办法了。
● Binlog Cache 使用状况:Binlog Cache 用于存放还未写入磁盘的 Binlog 信息。
相关状态变量如下:
sky@localhost : (none) 09:40:38> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE ‘Binlog_cache%‘;
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Binlog_cache_disk_use | 0 |
| Binlog_cache_use | 0 |
+-----------------------+-------+
如果 Binlog_cache_disk_use 值不为0,则说明 Binlog Cache 大小可能不够, 建议增加 binlog_cache_size 系统参数大小。
● Innodb_log_waits 量:Innodb_log_waits 状态变量直接反应出 Innodb Log Buffer 空间不足造成等待的次数。
sky@localhost : (none) 09:43:53> SHOW /*!50000 GLOBAL*/ STATUS
-> LIKE ‘Innodb_log_waits‘;
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_log_waits | 0 |
+------------------+-------+
该变量值发生的频率将直接影响系统的写入性能,所以当该值达到每秒1次时就该增加 系统参数innodb_log_buffer_size的值,毕竟这是一个系统共用的缓存,适当增加并不会造成内存不足的问题。
上面这些监控量只是我个人认为比较重要的一些 MySQL 性能监控量,各位读者朋友还可以根据各自的需要,通过 MySQL 所提供的系统状态变量增加其他监控内容。
18.4 常用开源监控软件
前面已经介绍过了监控系统的设计思路,也分析了我们需要关注的部分健康状态和性能状态监控点,这一节再介绍几种常用的第三方监控软件,为大家提供一点搭建监控系统的思路。当然,推荐原则仍然是以开源(或免费)产品为主。当然,前提是我们暂时没有自行开发一套监控系统的打算,而希望通过一些开源的软件工具来实现。
在介绍监控软件之前,有一个软件是我不得不提的:RRDTool。RRDTool全称为 Round
Robin Database Tool,也就是环状循环数据库工具,在多种监控软件中充当非常重要的数据存储角色。所谓环状循环数据库,就是数据的存储方式类似于在一个环形空间中,没有确切的起始位置和结束位置。当写完一圈之后,新的数据会覆盖老数据。当然,由于环状循环数据库所存放的数据大多都是存放用于统计方面的数据,而且可以通过一些加和平均之类的统计算法通过老数据得出相应的统计结果。当老数据需要被覆盖的时候,他早已失去实际价
值了。所以,RRDTool 在很多监控工具中都被用来存放各种性能数据,然后根据这些数据画出相应的趋势图,以及不同时间段内的平均值曲线。如果有哪位读者朋友有兴趣自行开发一个监控工具,RRDTool 同样可以作为您用来存放相关数据非常合适的选择。不过,这里有一点需要注意的是他只能存放数字。
1、Nagios
Nagois 是一个非常著名的运行在 Linux/Unix 上的对IT设备或服务的运行状态进行监控的软件。实际上,我个人觉得称其为一个监控平台可能更为合适,因为它不仅仅自带了丰富的监控工具,同时还支持用户自己编写各种各样的监控脚本以插件形式嵌入其中。
Nagios 自带的监控功能不仅包含与主机资源相关的 CPU 负载,磁盘使用等,还包括了网络相关的服务,如SMTP、POP3、HTTP、NNTP、PING 等。当然,Nagios 流行的另外一个重要原因是其简单的插件设计允许用户可以非擦方便地开发自己需要的服务检查。
对于大多数的监控场景来说,Nagios 的现有功能都能够满足。不论是主动检测,还是被动监控,都可以很好的实现。对于不同重要级别的监控点,可以分别设置不同的数据采集频率。对于异常的处理,可以设定为邮件、Web以及其他自定义的异常通知机制(如手机短信或者 IM 工具通知)。不仅如此,Nagios 还可以设置报警前的异常出现次数,如连续多少次访问超时之后再发出警告信息。而当我们需要进行正常维护的时候,还可以通过设置一个暂时忽略异常的 DownTime 时间段。
Nagios 分为客户端与服务器端两部分,客户端实际上就是大量的 Nagios 监控插件,负责采集监控点的各种数据,而服务器端则是配置管理、数据分析、告警发送、用户自助管理以及相关信息展示等功能。服务器端的Web展示界面的功能也非常强大,可以非常准且的展示出当前各个监控点的状态,上一次检测时间等信息。同时还能根据监控点追溯一定的历史记录信息。
当然,Nagios 也有一个缺点,那就是目前他仅仅支持健康状态数据的采集分析,而不支持通过采集性能数据来绘制性能趋势曲线图。当然,这可以结合其他的软件工具共同完成这一工作。
如需更为详细的 Nagios 的搭建使用手册,请各位读者朋友前往其官方网站获取更为权威的信息:http://www.nagios.org/docs
2、MRTG
MRTG 应该算是一款比较老牌的监控软件了,功能比较简单,最初是为了监控网络链路流量而产生的。但是经过原开发者的不断改造,以及网友们的集体智慧,其应用场景已经远远超出了网络链路流量监控。
MRTG 的实现原理其实很简单,他通过 snmp 协议,调用监控设备上面相应的脚本,获取需要的返回值,然后通过 RRDTool 保存起来。然后再通过 RRDTool 将保存的数据进行相应的统计平均计算,最后画成图片,通过 html 的形式展现给前端浏览者。
对于 MRTG 来说,它不需要知道我们监控的到底是什么数据,只需要告诉他到底什么时候该调用什么脚本来取得监控返回值,同时配置好存放位置,即可完成一个监控项的监控配置。对于我们来说,最为重要的是写好取得监控值的脚本,设定好 MRTG 的采集频率,然后就是查看各种监控数据的曲线图了。
更为详细的 MRTG 使用及搭建方法,请至官方网站(http://oss.oetiker.ch/mrtg) 上查找相应文档。
3、 Cacti
Cacti 和 Nagios 最大的区别在于前者具有非常强大的数据采集、存储以及展现功能, 但在告警管理这一块稍弱于后者。其开发语言是PHP,配置存储在 MySQL 数据库中,数据采集同样利用了 SNMP 协议,采集数据的存储则利用了本节最前面介绍的 RRDTool。
在数据的绘图展现方面,相对于其他有些监控软件来说,也有一定的优势,如单个图上面可以有无限多个数据项共存,而不像 MRTG 每张图片上只能有两个数据项的曲线。
除了非常强大的数据灰土展现功能之外,Cacti另外一个比较有吸引力的功能就是可以通过用户管理,设定多种权限角色,让更多的用户自行定义维护各自的监控配置项。这个特性对于监控设备(或服务)涉及到多个部门的很多人的应用场景下,是非常有用的。
当然,除了上面的这几个比较有特点特性之外,Cacti 还存在很多很多其他的特性。大家可以从Cacti官方文档获得更详细的信息:http://www.cacti.net/documentation.php。
不同的监控需求,可以采用不同的监控软件来实现,如我个人的很多环境就同时使用了Nagios 来实现健康状况的监控和告警。而性能数据的采集与绘图则利用了MRTG和 RRDTool来实现。各位读者朋友完全可以根据自己的需求来决定如何搭建一个更为合适的监控系统,来帮助大家更进一步提高系统的可用性。
18.4 小结
系统的监控在很多环境中都没有得到足够的重视,可其实际意义却非常大。虽然监控系统本身并不能让系统运行的更好,却能够给在系统出现问题之后的第一时间通知我们,缩短了发现问题的时间,也间接提高了系统的可用性。甚至可以根据监控所收集的各种性能数据,让我们提前发现系统的性能问题,防范于未然。本章通过对 MySQL 数据库环境的健康状态、性能状态以及相应的监控方式的分析,完成了搭建一个高可用数据库环境的最后一步,希望能够对各位读者朋友有一点帮助。
摘自:《MySQL性能调优与架构设计》简朝阳
转载请注明出处:
作者:JesseLZJ
出处:http://jesselzj.cnblogs.com
MySQL性能调优与架构设计——第 18 章 高可用设计之 MySQL 监控
标签:
原文地址:http://www.cnblogs.com/jesselzj/p/5611904.html