标签:
图像压缩的目的是减少图像的不相关性和冗余性使得其能够以有效的形式存储或者传输。图像压缩分为有损压缩和无损压缩,无损图像压缩常用于档案资料、医学、工程制图、剪贴画和漫画。有损图像压缩,对于低比特流的传输条件下常使用。有损图像压缩对于那些可以牺牲少许的图像质量而希望获得低比特传输的图像具有很广泛的应用。
图像的压缩方法就是研究如何减少或去掉数据中冗余部分以减小数据的存储空间,图像压缩中数据冗余主要包含以下几种:
1.编码冗余:
以灰度图像为例,像素点的取值范围是[0,255],而对于一幅图像来说,其宽度和高度可能是512*512或者更多,这样会导致一幅图像中相同的灰度级会出现多次,对于这种相同灰度级出现多次的冗余,就叫做编码冗余,减少这种冗余的主要方法是把出现次数较多的灰度值用较小位数进行编码,而出现次数较少的灰度值用相对较多的位数进行编码(夫曼编码和算术编码就是基于此思想)。
图示:灰度图像和其对应的数据表示方式
图示:统计图像,得到整幅图像共有64个像素,需要存储空间64×8=512B,按照表中的编码方式,需要存储空间为40×1+2×1+3×2=67B
2.空间冗余:
空间冗余(像素冗余,几何冗余)它描述的是图像具有局部自相似性,即图像中一个点的颜色和周围邻域内的像素点的颜色值相等或者很近,单个像素携带的信息相对较小。自然界中的人或者物的图像都具有这个特性,假如人脸图像不具有自相似性,那么就会变的五彩斑斓。
利用该特性对图像进行压缩有四种方法:
1)对于连续相等灰度值的情况,采用灰度值和相等点个数组合的编码方式:
如上图所示的灰度图像与数据对应的关系,有连续8个点是灰度值3,则将这8个点编码为(8,0),(8表示相等点的个数,0表示灰度值为3)[此种编码即为行程编码]
2)对于灰度值相近的情况,可以利用对当前点与前一个点的差进行编码的方法,由于灰度值相近,差的绝对值就接近于0,所占的位就少了,从而达到压缩的目的。在解压的过程,把差加到前一点的灰度值就得到了当前点的灰度值了:
例如对数列[1,2,3,4,5,6,7,8,9]进行压缩,对该数列变形[1,1(2-1),1(3-2),1(4-3),1(5-4),1(6-5),1(7-6),1(8-7),1(9-8)]进行压缩就方便了,这就是差分编码的思想。
在实际的应用中,当前点的值可能与前几个点的灰度值相关,此时可以采用当前点与前几个像素点灰度值的加权和的差进行编码,即预测编码。
3)图像的像素之间具有较强的相关性,可以通过一种变换把相关性去掉,让图像的信息集中在少数几个系数上,这样可以减少冗余,实现压缩,如DCT变换等。
3.人眼视觉冗余:
人观察图像的目的就是获得有用的信息,但是人眼并不是对所有的视觉信息具有相同的敏感度,在特定的场合,一些信息相对于另外一些信息来说,就不那么重要,这些相对不重要的信息就是心理视觉冗余。科学实验表明:人眼的分辨率是有限的,人眼不能区分各种颜色或者灰度级,如对整幅图像而言,人眼能区分40~60个灰度级,而对于图像的局部,人眼只能区分32个灰度级,其他的灰度级相对来说就是心理视觉冗余信息。如图所示,和之前的图看起来没有差别,但是他们对应的数据却不一致。在两幅图中,2,3,4灰度值与3很相近,148,150,151的灰度值和150很相近,253,254,255的灰度值与255相近,如把数据中相应的灰度值变换成对应的3,150,255,这样利于数据压缩,这就是心理视觉冗余。
图示 心里视觉冗余

图示 图像压缩算法的分类
现在以离散余弦变化为例,像大家解释一下JPEG的压缩。
在实际应用中,JPEG图像编码算法使用的大多是离散余弦变换、Huffman编码、顺序编码模式。这样的方式,被人们称为JPEG的基本系统。这里介绍的JPEG编码算法的流程,也是针对基本系统而言。基本系统的JPEG压缩编码算法一共分为11个步骤:颜色模式转换、采样、分块、离散余弦变换(DCT)、Zigzag 扫描排序、量化、DC系数的差分脉冲调制编码、DC系数的中间格式计算、AC系数的游程长度编码、AC系数的中间格式计算、熵编码。下面,将一一介绍这11个步骤的详细原理和计算过程。
图示:DCT图像压缩算法流程示意图
JPEG算法的第一步,图像被分割成大小为8X8的小块,这些小块在整个压缩过程中都是单独被处理的。
步骤2:颜色空间转换:
不同的颜色模型各有不同的应用场景,例如RGB模型适合于像显示器这样的自发光图案,而在印刷行业,使用油墨打印,图案的颜色是通过在反射光线时产生的,通常使用CMYK模型,而在JPEG压缩算法中,需要把图案转换成为YCbCr模型,这里的Y表示亮度(Luminance),Cb和Cr分别表示绿色和红色的“色差值”。
“色差”这个概念起源于电视行业,最早的电视都是黑白的,那时候传输电视信号只需要传输亮度信号,也就是Y信号即可,彩色电视出现之后,人们在Y信号之外增加了两条色差信号以传输颜色信息,这么做的目的是为了兼容黑白电视机,因为黑白电视只需要处理信号中的Y信号即可。
最终可以得到RGB转换为YCbCr的数学公式为
可以明显看到,亮度图的细节更加丰富。JPEG把图像转换为YCbCr之后,就可以针对数据得重要程度的不同做不同的处理。这就是为什么JPEG使用这种颜色空间的原因。
步骤3:离散余弦变换:
离散余弦变换属于傅里叶变换的另外一种形式,没错,就是大名鼎鼎的傅里叶变换。傅里叶是法国著名的数学家和物理学家,1807年,39岁的傅里叶在他的一篇论文里提出了一个想法,他认为任何周期性的函数,都可以分解为为一系列的三角函数的组合,这个想法一开始并没有得到当时科学界的承认,比如当时著名的数学家拉格朗日提出质疑,三角函数无论如何组合,都无法表达带有“尖角”的函数,一直到1822年拉格朗日死后,傅里叶的想法才正式在他的著作《热的解析理论》一书中正式发表。
金子总会闪光,傅里叶变换如今广泛应用于数学、物理、信号处理等等领域,变换除了它在数学上的意义外,还有其哲学上的伟大意义,那就是,世上任何复杂的事物,都可以分解为简单的事物的组合,而这个过程只需要借助数学工具就可以了。但是当年拉格朗日的质疑是正确的,三角函数的确无法表达出尖角形状的函数,不过只要三角函数足够多,可以无限逼近最终结果。
DCT变换具有以下的性质,正是利用这些性质,我们将其用到JPEG压缩算法中:
1)图像经DCT变换以后,DCT系数之间的相关性就会变小。而且大部分能量集中在少数的系数上,因此,DCT变换在图像压缩中非常有用,是有损图像压缩国际标准JPEG的核心。
2)在空间上具有强相关的信号,反映在频域上是在某些特定的区域内能量常常被集中在一起,或者是系数矩阵的分布具有某些规律。
3)将空间域上的图像经过正交变换映射到系数空间,使变换后的系数直接相关性降低。图像变换本身并不能压缩数据,但变换后图像大部分能量集中到了少数几个变换系数上,再采用适当的量化和熵编码便可以有效地压缩图像。
4)信息论的研究表明,正交变换不改变信源的熵值,变换前后图像的信息量并无损失,完全可以通过反变换得到原来的图像值。但图像经过正交变换后,把原来分散在原空间的图像数据在新的坐标空间中得到集中,对于大多数图像而言,大量的变换系数很小,只要删除接近于0的系数,并对较小的系数进行粗量化,而保留包含图像主要信息的系数,以此进行压缩编码。在重建图像进行解码(逆变换)时,所损失的将是些不重要的信息,几乎不会引起图像失真,图像的变换编码就是利用这些来压缩图像并得到很高的压缩比;
5)如果原始信号是图像等相关性较大的数据的时候,我们可以发现在变换之后,系数较大的集中在左上角,而右下角的几乎都是0,其中左上角的是低频分量,右下角的是高频分量,低频系数体现的是图像中目标的轮廓和灰度分布特性,高频系数体现的是目标形状的细节信息。DCT变换之后,能量主要集中在低频分量处,这也是DCT变换去相关性的一个体现。反应在恢复图像上将是轮廓及细节模糊;
6)即图像信息的大部分集中于直流系数及其附近的低频频谱上,离DC系数越来越远的高频频谱几乎不含图像信息,甚至于只含杂波。
可以看到,数据经过DCT变化后,被明显分成了直流分量和交流分量两部分
DCT变换是一个无损压缩变换,它实际上并不实现压缩,是“有损”的准备,即为“量化”处理阶段做准备。
量化只不过是通过减少整数单精度来减少存贮整数值所需要的位数第一个过程。一旦DCT图像压缩,我们可以随着远离原点处的直流系数越来越多地减少系数的精度:离(0,0)点越远,这个元素对于图形图像的贡献就越小,所有我们就越不用去维持这个值的精确精度,进而减少存储变换后的系数需要的比特数。定义量化公式为:
其中,为量化前的DCT系数,为量化后的DCT系数,而为量化步长,通常随DCT系数的位置不同而取不同的值,表示取整。
对于基于DCT的JPEG图像压缩编码算法,量化步距是按照系数所在的位置和每种颜色分量的色调值来确定。因为人眼对亮度信号比对色差信号更敏感,因此使用了表2-1所示的量化表。此外,由于人眼对低频分量的图像比对高频分量的图像更敏感,因此表中的左上角的量化步距要比右下角的量化步距小。

图示:亮度色度量化表
图示 DCT量化与反量化举例
可以看到,一大部分数据变成了0,这非常有利于后面的压缩存储。这两张神奇的量化表也是有讲究的,还记得我们在第一节中所讲的有损压缩的基本原理吗,有损压缩就是把数据中重要的数据和不重要的数据分开,然后分别处理。DCT系数矩阵中的不同位置的值代表了图像数据中不同频率的分量,这两张表中的数据时人们根据人眼对不不同频率的敏感程度的差别所积累下的经验制定的,一般来说人眼对于低频的分量必高频分量更加敏感,所以两张量化系数矩阵左上角的数值明显小于右下角区域。在实际的压缩过程中,还可以根据需要在这些系数的基础上再乘以一个系数,以使更多或更少的数据变成0,我们平时使用的图像处理软件在省城jpg文件时,在控制压缩质量的时候,就是控制的这个系数。
步骤4:Zig-Zag扫描以及脉冲差分方程
DCT 将一个 8x8 的数组变换成另一个 8x8 的数组. 但是内存里所有数据都是线形存放的, 如果我们一行行的存放这 64 个数字, 每行的结尾的点和下行开始的点就没有什么关系, 所以 JPEG 规定按如下图中的数字顺序依次保存和读取64 个DCT的系数值。
这样数列里的相邻点在图片上也是相邻的了。不难发现,这种数据的扫描、保存、读取方式,是从8*8矩阵的左上角开始,按照英文字母Z的形状进行扫描的,一般将其称之为Zigzag扫描排序。如下图所示:
这么做的目的只有一个,就是尽可能把0放在一起,由于0大部分集中在右下角,所以才去这种由左上角到右下角的顺序,经过这种顺序变换,最终矩阵变成一个整数数组
步骤5:哈弗曼编码:
JPEG压缩的最后一步是对数据进行哈弗曼编码(Huffman coding),哈弗曼几乎是所有压缩算法的基础,它的基本原理是根据数据中元素的使用频率,调整元素的编码长度,以得到更高的压缩比。
举个例子,比如下面这段数据
这段数据里面包含了33个字符,每种字符出现的次数统计如下
| 字符 | A | B | C | D | E |
|---|---|---|---|---|---|
| 次数 | 6 | 15 | 2 | 9 | 1 |
如果我们用我们常见的定长编码,每个字符都是3个bit。
| 字符 | A | B | C | D | E |
|---|---|---|---|---|---|
| 编码 | 001 | 010 | 011 | 100 | 101 |
那么这段文字共需要3*33 = 99个bit来保存,但如果我们根据字符出现的概率,使用如下的编码
| 字符 | A | B | C | D | E |
|---|---|---|---|---|---|
| 编码 | 110 | 0 | 1110 | 10 | 1111 |
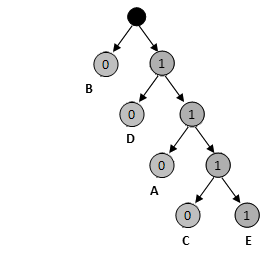
那么这段文字共需要3*6 + 1*15 + 4*2 + 2*9 + 4*1 = 63个bit来保存,压缩比为63%,哈弗曼编码一般都是使用二叉树来生成的,这样得到的编码符合前缀规则,也就是较短的编码不能够是较长编码的前缀,比如上面这个编码,就是由下面的这颗二叉树生成的。
我们回到JPEG压缩上,回顾上一节的内容,经过数据量化,我们现在要处理的数据是一串一维数组,举例如下:
| ①原始数据 |
|
|---|
在实际的压缩过程中,数据中的0出现的概率非常高,所以首先要做的事情,是对其中的0进行处理,把数据中的非零的数据,以及数据前面0的个数作为一个处理单元。
| ①原始数据 |
|
|||||||
|---|---|---|---|---|---|---|---|---|
| ②RLE编码 | 35 | 7 | 0,0,0,-6 | -2 | 0,0,-9 | 0,0,…,0,8 | 0,0,…,0 | |
如果其中某个单元的0的个数超过16,则需要分成每16个一组,如果最后一个单元全都是0,则使用特殊字符“EOB”表示,EOB意思就是“后面的数据全都是0”,
| ①原始数据 |
|
|||||||
|---|---|---|---|---|---|---|---|---|
| ②RLE编码 | 35 | 7 | 0,0,0,-6 | -2 | 0,0,-9 | 0,0,…,0,8 | 0,0,…,0 | |
| 35 | 7 | 0,0,0,-6 | -2 | 0,0,-9 | 0,0,…,0 | 0,0,8 | 0,0,…,0 | |
| (0,35) | (0,7) | (3,-6) | (0,-2) | (2,-9) | (15,0) | (2,8) | EOB | |
其中(15,0)表示16个0,接下来我们要处理的是括号里右面的数字,这个数字的取值范围在-2047~2047之间,JPEG提供了一张标准的码表用于对这些数字编码:
| Value | Size | Bits | ||
|---|---|---|---|---|
| 0 | 0 | – | ||
| -1 | 1 | 1 | 0 | 1 |
| -3,-2 | 2,3 | 2 | 00,01 | 10,11 |
| -7,-6,-5,-4 | 4,5,6,7 | 3 | 000,001,010,011 | 100,101,110,111 |
| -15,…,-8 | 8,…,15 | 4 | 0000,…,0111 | 1000,…,1111 |
| -31,…,-16 | 16,…,31 | 5 | 0 0000,…,0 1111 | 1 0000,…,1 1111 |
| -63,…,-32 | 32,…,63 | 6 | 00 0000,… | …,11 1111 |
| -127,…,-64 | 64,…,127 | 7 | 000 0000,… | …,111 1111 |
| -255,…,-128 | 128,…,255 | 8 | 0000 0000,… | …,1111 1111 |
| -511,…,-256 | 256,…,511 | 9 | 0 0000 0000,… | …,1 1111 1111 |
| -1023,…,-512 | 512,…,1023 | 10 | 00 0000 0000,… | …,11 1111 1111 |
| -2047,…,-1024 | 1024,…,2047 | 11 | 000 0000 0000,… | …,111 1111 1111 |
举例来说,第一个单元中的“35”这个数字,在表中的位置是长度为6的那组,所对应的bit码是“100011”,而“-6”的编码是”001″,由于这种编码附带长度信息,所以我们的数据变成了如下的格式。
| ①原始数据 |
|
|||||||
|---|---|---|---|---|---|---|---|---|
| ②RLE编码 | 35 | 7 | 0,0,0,-6 | -2 | 0,0,-9 | 0,0,…,0,8 | 0,0,…,0 | |
| 35 | 7 | 0,0,0,-6 | -2 | 0,0,-9 | 0,0,…,0 | 0,0,8 | 0,0,…,0 | |
| (0,35) | (0,7) | (3,-6) | (0,-2) | (2,-9) | (15,0) | (2,8) | EOB | |
| ③BIT编码 | (0,6, 100011) | (0,3, 111) | (3,3, 001) | (0,2, 01) | (2,4, 0110) | (15,-) | (2,4, 1000) | EOB |
括号中前两个数字分都在0~15之间,所以这两个数可以合并成一个byte,高四位是前面0的个数,后四位是后面数字的位数。
| ①原始数据 |
|
|||||||
|---|---|---|---|---|---|---|---|---|
| ②RLE编码 | 35 | 7 | 0,0,0,-6 | -2 | 0,0,-9 | 0,0,…,0,8 | 0,0,…,0 | |
| 35 | 7 | 0,0,0,-6 | -2 | 0,0,-9 | 0,0,…,0 | 0,0,8 | 0,0,…,0 | |
| (0,35) | (0,7) | (3,-6) | (0,-2) | (2,-9) | (15,0) | (2,8) | EOB | |
| ③BIT编码 | (0,6, 100011) | (0,3, 111) | (3,3, 001) | (0,2, 01) | (2,4, 0110) | (15,-) | (2,4, 1000) | EOB |
| (0x6,100011) | (0x3,111) | (0x33,001) | (0x2,01) | (0x24,0110) | (0xF0,-) | (0x24,1000) | EOB | |
对于括号前面的数字的编码,就要使用到我们提到的哈弗曼编码了,比如下面这张表,就是一张针对数据中的第一个单元,也就是直流(DC)部分的哈弗曼表,由于直流部分没有前置的0,所以取值范围在0~15之间。
| Length | Value | Bits |
|---|---|---|
| 3 bits | 04 05 03 02 06 01 00 (EOB) |
000 001 010 011 100 101 110 |
| 4 bits | 07 | 1110 |
| 5 bits | 08 | 1111 0 |
| 6 bits | 09 | 1111 10 |
| 7 bits | 0A | 1111 110 |
| 8 bits | 0B | 1111 1110 |
举例来说,示例中的DC部分的数据是0x06,对应的二进制编码是“100”,而对于后面的交流部分,取值范围在0~255之间,所以对应的哈弗曼表会更大一些
| Length | Value | Bits |
|---|---|---|
| 2 bits | 01 02 |
00 01 |
| 3 bits | 03 | 100 |
| 4 bits | 00 (EOB) 04 11 |
1010 1011 1100 |
| 5 bits | 05 12 21 |
1101 0 1101 1 1110 0 |
| 6 bits | 31 41 |
1110 10 1110 11 |
| … | … | … |
| 12 bits | 24 33 62 72 |
1111 1111 0100 1111 1111 0101 1111 1111 0110 1111 1111 0111 |
| 15 bits | 82 | 1111 1111 1000 000 |
| 16 bits | 09 … FA |
1111 1111 1000 0010 … 1111 1111 1111 1110 |
这样经过哈弗曼编码,并且序列化后,最终数据成为如下形式
| ①原始数据 |
|
|||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ②RLE编码 | 35 | 7 | 0,0,0,-6 | -2 | 0,0,-9 | 0,0,…,0,8 | 0,0,…,0 | |||||||
| 35 | 7 | 0,0,0,-6 | -2 | 0,0,-9 | 0,0,…,0 | 0,0,8 | 0,0,…,0 | |||||||
| (0,35) | (0,7) | (3,-6) | (0,-2) | (2,-9) | (15,0) | (2,8) | EOB | |||||||
| ③BIT编码 | (0,6, 100011) | (0,3, 111) | (3,3, 001) | (0,2, 01) | (2,4, 0110) | (15,-) | (2,4, 1000) | EOB | ||||||
| (0x6,100011) | (0x3,111) | (0x33,001) | (0x2,01) | (0x24,0110) | 0xF0 | (0x24,1000) | EOB | |||||||
| ④哈弗曼编码 | 100 | 100011 | 100 | 111 | 1111 1111 0101 | 001 | 01 | 01 | 1111 1111 0100 | 0110 | 1111 1111 001 | 1111 1111 0100 | 1000 | 1010 |
| ⑤序列化 |
|
|||||||||||||
|
|
||||||||||||||
最终我们使用了10个字节的空间保存了原本长度为64的数组,至此JPEG的主要压缩算法结束,这些数据就是保存在jpg文件中的最终数据。
步骤6:实验结果

压缩前的图像 压缩后的图像(压缩比为15:1)
以上:如果需要MATLAB源代码或者彼此之间想做出技术上的交流,请联系sunlinju303@outlook.com
本人现在也研究VESA_DSC压缩算法,想借用此博客来和大家分享交流一下技术经验,慢慢一点点跟新内容吧,有感兴趣的朋友可以发邮件至sunlinju303@outlook.com,我们做一个技术上的交流,先来一个简介:
视频电子标准协会(Video Electronics Standards Association, VESA)是由代表来自世界各地的、享有投票权利的140多家成员公司的董事会领导的非盈利国际组织,总部设立于加利福尼亚州的Milpitas,自1989年创立以来,一直致力于制订并推广显示相关标准。
该协会于2012年9月成立视觉无损压缩标准(DisplayStream Compression ,DSC))小组,在 2014年4成功的发布第一版DSC算法,DSC算法共测试了226,725幅图像,都具有视觉无损性,且图像能够保证较高的压缩质量,已成为业界公认的压缩标准之一,为此本文选择了该V1.1标准算法。
正在研究阶段,有兴趣的大家可以一起来玩。
相关文献:
1.无损数据压缩算法历史:http://blog.jobbole.com/77247/;
2.图像压缩算法:http://blog.csdn.net/anghlq/article/details/18443753
3.JPEG算法解密:http://thecodeway.com/blog/?p=69
标签:
原文地址:http://blog.csdn.net/sunlinju/article/details/51726242














