标签:android blog http java 使用 strong 文件 数据
随着android的学习解析xml成为了很多朋友面临的问。想学习如何解析xml就要先了解xml是什么。
XML称为可扩展标记语言(Extensible Markup Language),由标准通用标记语言(SGML:Standard Generalized Markup Language)发展而来,允许开发者自定义标签,可以实现标签和内容的有效分离。
与HTML不同,XML不再侧重于数据如何表现,而是更多的关注数据如何存储和传输。因此,XML逐渐演变成为一种跨平台的数据交换格式。通过使用XML,开发者可以在不同平台、不同系统之间进行数据交换。除此之外,还可以使用XML作为配置文件,将应用程序状态保存到XML文件中,而无须使用关系型数据库。
目前常用的两种解析xml的方式:DOM SAX
二者区别:
DOM 通过标准接口将文档读入内存,
优点是可以随机访问xml中每个元素。
缺点是一次性读入整个文档到内存中,整个DOM树常驻内存,导致系统开销过大。
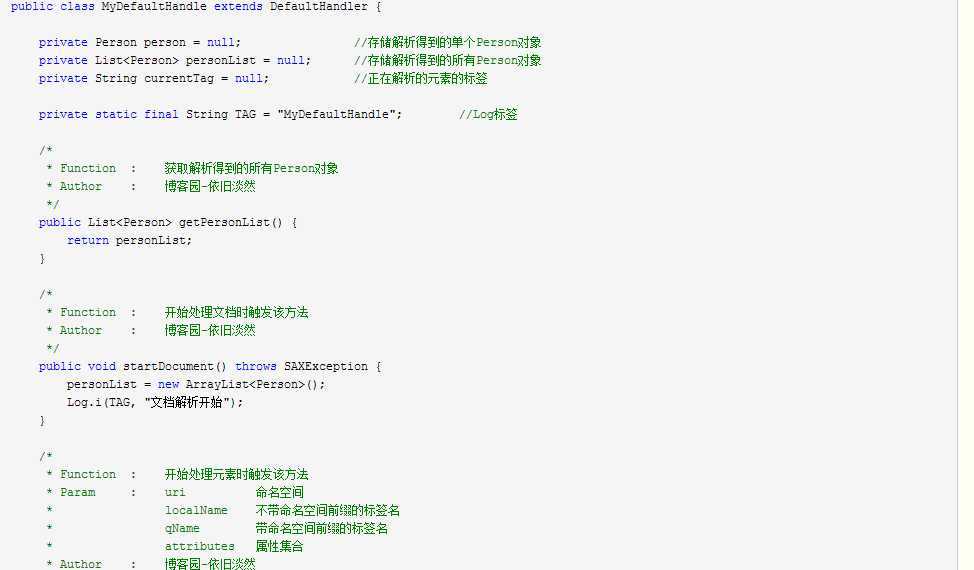
SAX 采用时间驱动机制来解析xml文档。通过开发者编写的事件监听器来获取XML信息。
优点是解析方式占用内存小处理速度快。
缺点是采用顺序模式来读取xml,因此无法做到随机读取文档中的任意元素。
JAXP(java API for xml)JAXP是建立在DOM和SAX之上的一个抽象层,它既没有提供解析XML的新方法,也没有对DOM和SAX进行任何扩展,仅仅只是提供了一种工厂模式,允许应用程序在不同的XML解析器之间切换。
SAX解析器
JAXP为SAX解析器提供了以下的2组API。
(1)XMLReader和XMLReaderFactory:XMLReaderFactory工程类的creatXMLReader()静态方法用于创建XMLReader。
(2)SAXParser和SAXParserFactory:SAXParserFactory工厂类的newSAXParser()实例方法用于创建SAXParser。
以上两组API中的XMLReader和SAXParser都是SAX解析器,它们都定义了多个parser()方法,用于以SAX方式解析XML文档。
其中,XMLReader提供了如下2个用于解析XML文档的parser()方法。
(1)void parse(InputSource input); //解析InputSource输入源中的XML文档
(2)void parse(String systemId); //解析系统URI指定的XML文档
SAXParser则提供了如下4个用于解析XML文档的parser()方法。
(1)void parse(File f, DefaultHandler dh); //解析f文件所代表的XML文档
(2)void parse(InputSource is, DefaultHandler dh); //解析InputSource输入源中的XML文档
(3)void parse(InputStream is, DefaultHandler dh); //解析InputStream输入源中的XML文档
(4)void parse(String uri, DefaultHandler dh); //解析系统URI指定的XML文档
可以看出,在SAXParser的parser()方法中,第二个参数是一个DefaultHandler对象,该对象就是用于监听SAX解析事件的监听器。
SAX的监听器:
(1)ContentHandler:坚挺xml文档内容处理事件
(2)DTDHandler:监听DTD事件的监听器
(3)EntityResolver 监听实体处理事件
(4)ErrorHandler 监听错误
JAXP提供了DefaultHandler类来实现监听。DefaultHandler类实现了ContentHandler、DTDHandler、EntityResolver和ErrorHandler接口,并为这些接口中所包含的方法提供了空实现。因此,开发者只需要编写一个继承自DefaultHandler的类,并重写自己所关心的监听方法,而无须为每个方法都提供实现。
SAX解析xml文档的一般步骤:
(1)通过SAXParserFactory的newInstance()方法创建SAXParserFactory对象(SAX解析器工厂)
(2)通过SAXParserFactory对象的newSAXParser()创建SAXParser对象(SAX解析器)
(3) 通过SAXParser对象的parser()方法解析xml文档,该方法的第二个参数要传入一个DefaultHandler对象
综上,附上代码供大家参考:



1.DOM树中的对象类型
使用DOM解析XML文档时,整个XML文档会被转换成一颗DOM树,DOM解析器会将XML文档的节点对应转化成DOM树的每个节点。
DOM树不仅可以描述XML文档的结构化特征,而且具有对象模型的特征,将XML文档转换成DOM树的过程,就是将文档模型对象化的过程。
2.DOM解析器(与SAX解析器类似)
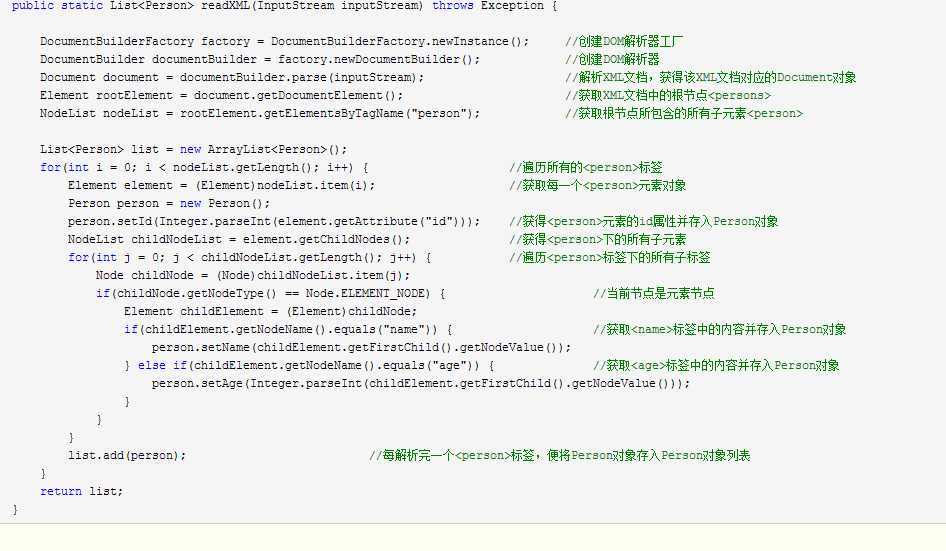
通过以下三个步骤可以实现DOM解析器的创建,并完成XML文档模型对象化的过程。
(1)通过调用DocumentBuilderFactory类的newInstance()方法,创建一个DOM解析器工厂对象。
(2)通过调用DOM解析器工厂对象的newDocumentBuilder()方法,创建一个DOM解析器对象。
(3)通过调用DOM解析器对象的parse()方法,完成文档模型对象化的过程,将XML文档解析成Document文档对象。
附上代码:
综上所诉,大家对xml的解析肯定有了一定的了解,但想真正学会如何使用xml还要用心继续学习。加油。(本文参考了“依旧淡然”的相关片段,并在此基础上整理加上个人的理解,希望对大家有用)
Android学习xml解析大全之SAX和DOM,布布扣,bubuko.com
标签:android blog http java 使用 strong 文件 数据
原文地址:http://www.cnblogs.com/xzHome/p/3891480.html