标签:
需要准备的知识点:http://www.cnblogs.com/zjiaxing/p/5616653.html
http://www.cnblogs.com/zjiaxing/p/5616664.html
http://www.cnblogs.com/zjiaxing/p/5616670.html
http://www.cnblogs.com/zjiaxing/p/5616679.html
利用 BoVW 表示图像,将图像进行结构化描述。BoVW思想是将图像特征整合成视觉单词,将图像特征空间转化成离散的视觉字典。将新的图像特征映射到视觉字典中最近邻视觉字典,再通过计算视觉字典间距离计算图像的相似度,从而完成识别、图像分类、检索等任务。
基于图像的闭环检测系统,将当前采集的图像和之前数据集中所有采集到的图像进行比较。每幅图像通过该图像的显著视觉特征描述,并用于图像相似性比较。描述符提取图像特征,将图像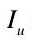
表示为一个 n维的描述符集合 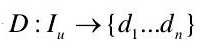 。
。
提取特征点后,每幅图像由一系列的视觉单词组成。每个orb 描述符提取的特征点 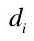 都 关 联 到 视 觉 字 典 中 的 一 个 视 觉 单 词
都 关 联 到 视 觉 字 典 中 的 一 个 视 觉 单 词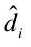 , 视 觉 字 典 表 示 为 :
, 视 觉 字 典 表 示 为 :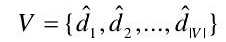 。视觉字典 V通过 BoVW 建模方法,对相似描述符聚类进行构建。 每一个视觉单词的 orb描述向量都被认为是一个关联的视觉词表。
。视觉字典 V通过 BoVW 建模方法,对相似描述符聚类进行构建。 每一个视觉单词的 orb描述向量都被认为是一个关联的视觉词表。
在构建好视觉字典之后,对群集进行中心化。通过在群集中心构架 K-D 树,并执行最近邻knn矢量对所有描述符量子化,实现对群集的简化。
测量两幅图像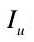 和
和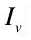 的相似度,可以通过计算它们之间的余弦距离获得。每一幅图像
的相似度,可以通过计算它们之间的余弦距离获得。每一幅图像 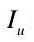 由不同权重
由不同权重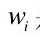 的词汇
的词汇 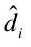 聚集构成,权重
聚集构成,权重 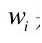 是每个词汇在全部图像集中发生的频率。 每个词汇的权重由式:
是每个词汇在全部图像集中发生的频率。 每个词汇的权重由式: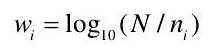
式中,N 是存储的所有图像,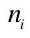 是
是 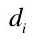 中包含图像的数量。如果视觉字典中包含|V|个不同的词汇,可以形成图像的矢量为:
中包含图像的数量。如果视觉字典中包含|V|个不同的词汇,可以形成图像的矢量为: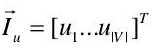
其中图像中包含的词汇权重如式: 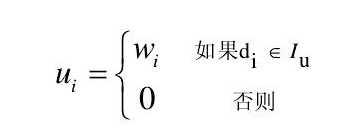
得到每个词汇的权重后,即可求出整幅图像的权重。再利用相似函数计算图像 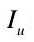 与
与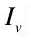 间的相似度,相似函数如式:
间的相似度,相似函数如式:
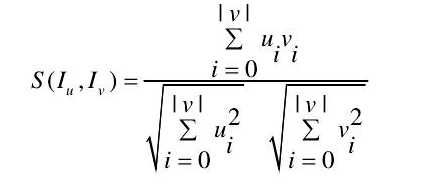
Bag of Words 字典建立
1、从训练图像中离线抽取特征
2、将抽取的特征用 k-means++ 算法聚类,将描述子空间划分成 k 类
3、将划分的每个子空间,继续利用 k-means++ 算法做聚类
4、按照上述循环,将描述子建立树形结构,如下图所示:
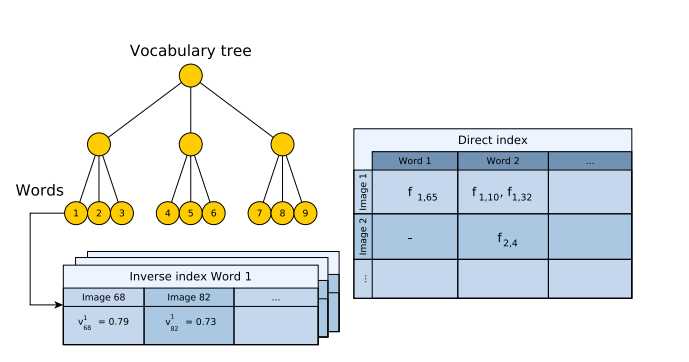
字典树在建立过程中,每个叶子也就是每个 word 记录了该 word 在所有的训练图像中出现的频率出现的频率越高,表示这个 word 的区分度越小,频率的计算公式如下:
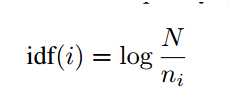
在线更新字典树
当在字典树中需要插入一幅新图像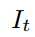 图像中提取的特征描述子按照 Hamming 距离从字典树的根部节点开始逐级向下到达叶子节点,可以计算每个叶子节点也就是每个 word 在图像 中的出现频率:
图像中提取的特征描述子按照 Hamming 距离从字典树的根部节点开始逐级向下到达叶子节点,可以计算每个叶子节点也就是每个 word 在图像 中的出现频率:
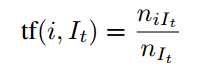
其中 niIt表示 word 在图像中出现的次数 nIt表示图像中描述子的总数在树构建的过程中每个叶子节点存储了 inverse index(倒排挡索引),存储了到达叶子节点的图像 It的 ID 和 word 在图像 It 描述 vector 中第 i 维的值: vit=tf(i,It)×idf(i)
对于一幅图像所有的描述子,做上述操作,可以得到每个 word 的值,将这些值构成图像的描述向量 vt。
对两幅图像比较计算其相似度时,两幅图像相似度计算公式如下:
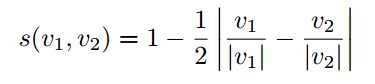
两幅图像越相似得分越高。字典树除了存储了 inverse index,还存储了 direct index 如上图所示,direct index 方便两幅图像特征搜索,建立特征之间的对应,计算两帧之间的位姿转换。
Database query
由于在计算相似度时,相似度的大小和字典树、图像等有一定关系,这里采用归一化的方式,消除这两种因素的影响:
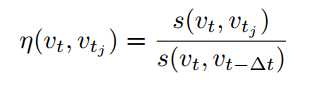
归一化相似度计算公式如下: 其中 vt−Δt表示上一帧图像,上式含义是上一帧图像和当前帧图像是最为相似度的,用和上一帧图像计算的相似度来归一化和字典树中图像计算的相似度。
当 s(vt,vt−Δt)较小时(机器人做旋转时),会把总体的得分拉的很高,论文里面剔除这种因素,选取阈值 α,当前帧和上一帧图像相似度小于 α 时不做回环检测。
Matching group
假设图像 vt 和图像 vni相似度很大,那么和图像 vni周围的图像也会有很高的相似度,这里将相邻的得分都很高的图像 group 在一起构成 island,得分是 group 中图像得分的总和。
Temporal consistency
假设图像 vt 和 island Vt1 之间相似度很大,那么图像 vt−kΔt 和 Vtk像素度也应该很大(k 小于 一定值),相当于两串图像间会有 overlap,利用这个条件作为 consistency 的约束。
Efficient geometrical consistency
对于一幅新图像 Ii,用字典树建立对图像的描述,并且计算和字典树中以前存储的图像之间的得分。
inverse index 加快待比较的图像搜索速度
由于 inverse index 存储了哪些图像也到达该叶子节点,在选择待比较的图像时,只需要比较到达相同叶子节点的图像,不需要和存储的每幅进行比较,从而加快比较速度。
direct index 加快特征比较速度
假设图像 Ii 和 Ij得分最高,在两幅图像特征匹配时,只需要比较 direct index 中属于同一个 node 的图像特征,node 指字典树的一层,如果是叶子节点层,那么选择是同一个 word 的特征做匹配。
#include <iostream> #include <vector> // DBoW2 #include "DBoW2.h" // defines Surf64Vocabulary and Surf64Database #include <DUtils/DUtils.h> #include <DVision/DVision.h> // OpenCV #include <opencv2/core.hpp> #include <opencv2/highgui.hpp> #include <opencv2/xfeatures2d/nonfree.hpp> using namespace DBoW2; using namespace DUtils; using namespace std; // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - void loadFeatures(vector<vector<vector<float> > > &features); void changeStructure(const vector<float> &plain, vector<vector<float> > &out, int L); void testVocCreation(const vector<vector<vector<float> > > &features); void testDatabase(const vector<vector<vector<float> > > &features); // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - // number of training images const int NIMAGES = 4; // extended surf gives 128-dimensional vectors const bool EXTENDED_SURF = false; // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - void wait() { cout << endl << "Press enter to continue" << endl; getchar(); } // ---------------------------------------------------------------------------- int main() { vector<vector<vector<float> > > features; loadFeatures(features); testVocCreation(features); wait(); testDatabase(features); return 0; } // ---------------------------------------------------------------------------- void loadFeatures(vector<vector<vector<float> > > &features) { features.clear(); features.reserve(NIMAGES); cv::Ptr<cv::xfeatures2d::SURF> surf = cv::xfeatures2d::SURF::create(400, 4, 2, EXTENDED_SURF); cout << "Extracting SURF features..." << endl; for(int i = 0; i < NIMAGES; ++i) { stringstream ss; ss << "images/image" << i << ".png"; cv::Mat image = cv::imread(ss.str(), 0); cv::Mat mask; vector<cv::KeyPoint> keypoints; vector<float> descriptors; surf->detectAndCompute(image, mask, keypoints, descriptors); features.push_back(vector<vector<float> >()); changeStructure(descriptors, features.back(), surf->descriptorSize()); } } // ---------------------------------------------------------------------------- void changeStructure(const vector<float> &plain, vector<vector<float> > &out, int L) { out.resize(plain.size() / L); unsigned int j = 0; for(unsigned int i = 0; i < plain.size(); i += L, ++j) { out[j].resize(L); std::copy(plain.begin() + i, plain.begin() + i + L, out[j].begin()); } } // ---------------------------------------------------------------------------- void testVocCreation(const vector<vector<vector<float> > > &features) { // Creates a vocabulary from the training features, setting the branching factor and the depth levels of the tree and the weighting and scoring schemes * Creates k clusters from the given descriptors with some seeding algorithm. const int k = 9; const int L = 3; const WeightingType weight = TF_IDF; const ScoringType score = L1_NORM; Surf64Vocabulary voc(k, L, weight, score); cout << "Creating a small " << k << "^" << L << " vocabulary..." << endl; voc.create(features); cout << "... done!" << endl; cout << "Vocabulary information: " << endl << voc << endl << endl; // lets do something with this vocabulary cout << "Matching images against themselves (0 low, 1 high): " << endl; BowVector v1, v2; for(int i = 0; i < NIMAGES; i++) { //Transforms a set of descriptores into a bow vector voc.transform(features[i], v1); for(int j = 0; j < NIMAGES; j++) { voc.transform(features[j], v2); double score = voc.score(v1, v2); cout << "Image " << i << " vs Image " << j << ": " << score << endl; } } // save the vocabulary to disk cout << endl << "Saving vocabulary..." << endl; voc.save("small_voc.yml.gz"); cout << "Done" << endl; } // ---------------------------------------------------------------------------- void testDatabase(const vector<vector<vector<float> > > &features) { cout << "Creating a small database..." << endl; // load the vocabulary from disk Surf64Vocabulary voc("small_voc.yml.gz"); Surf64Database db(voc, false, 0); // false = do not use direct index // (so ignore the last param) // The direct index is useful if we want to retrieve the features that // belong to some vocabulary node. // db creates a copy of the vocabulary, we may get rid of "voc" now // add images to the database for(int i = 0; i < NIMAGES; i++) { db.add(features[i]); } cout << "... done!" << endl; cout << "Database information: " << endl << db << endl; // and query the database cout << "Querying the database: " << endl; QueryResults ret; for(int i = 0; i < NIMAGES; i++) { db.query(features[i], ret, 4); // ret[0] is always the same image in this case, because we added it to the // database. ret[1] is the second best match. cout << "Searching for Image " << i << ". " << ret << endl; } cout << endl; // we can save the database. The created file includes the vocabulary // and the entries added cout << "Saving database..." << endl; db.save("small_db.yml.gz"); cout << "... done!" << endl; // once saved, we can load it again cout << "Retrieving database once again..." << endl; Surf64Database db2("small_db.yml.gz"); cout << "... done! This is: " << endl << db2 << endl; }
标签:
原文地址:http://www.cnblogs.com/zjiaxing/p/5616701.html