标签:
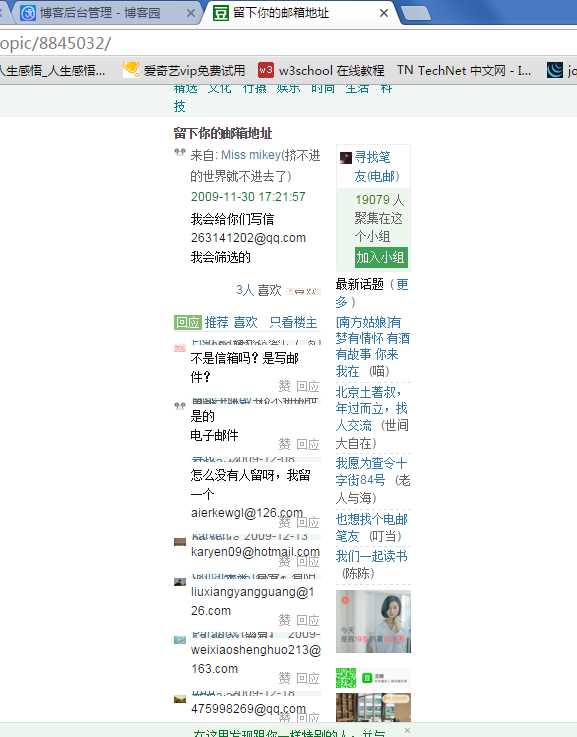
我们来抓取豆瓣网的邮箱吧!把这个页面的所有邮箱都抓取下来
如https://www.douban.com/group/topic/8845032/:
代码如下:
package cn.zhangzong.test; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.URL; import java.net.URLConnection; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * 正则抓取邮箱 * @author happy * */ public class Test { public static void main(String[] args) throws IOException { //1.1 创建一个url对象 URL url = new URL("https://www.douban.com/group/topic/8845032/"); //1.2 打开连接 URLConnection conn = url.openConnection(); //1.3 设置连接网络超时时间 单位为毫秒 conn.setConnectTimeout(1000 * 10); //1.4 通过流 操作读取指定网络地址中的文件 BufferedReader bufr = new BufferedReader(new InputStreamReader(conn.getInputStream())); String line = null; //1.5 匹配email的正则 String regex = "[a-zA-Z0-9_-]+@\\w+\\.[a-z]+(\\.[a-z]+)?"; //1.6 使用模式的compile()方法生成模式对象 Pattern p = Pattern.compile(regex); //1.7 遍历打印 while((line = bufr.readLine()) != null) { Matcher m = p.matcher(line); while(m.find()) { System.out.println(m.group());// 获得匹配的email } } } }
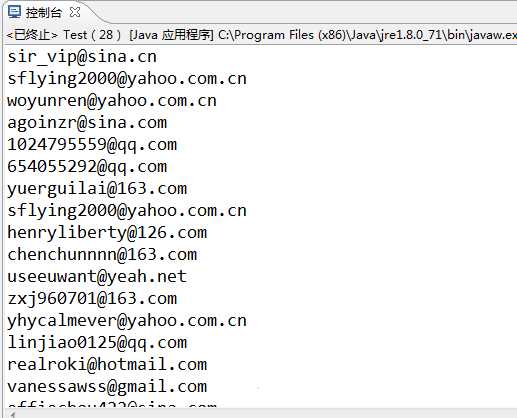
结果:
标签:
原文地址:http://www.cnblogs.com/Zhangmin123/p/5618086.html