标签:
简介
LruCache只是管理了内存中图片的存储与释放,如果图片从内存中被移除的话,那么又需要从网络上重新加载一次图片,这显然非常耗时。对此,Google又提供了一套硬盘缓存的解决方案:DiskLruCache(非Google官方编写,但获得官方认证)。由于DiskLruCache并不是由Google官方编写的,所以这个类并没有被包含在Android API当中,我们需要将这个类从网上下载下来,然后手动添加到项目当中。下载好了源码之后,只需要在项目中新建一个libcore.io包,然后将DiskLruCache.java文件复制到这个包中即可。
缓存路径设置
虽然我们可以自由的设定使用DiskLruCache时数据的缓存位置,但是通常情况下都会将缓存的位置选择为 /sdcard/Android/data/包名/cache,因为这是存储在SD卡上且被Android系统认定为是应用程序的缓存路径,当程序被卸载的时候,这里的数据也会一起被清除掉。另外我们也需要考虑如果这个手机没有SD卡,或者SD正好被移除了的情况,因此我们专门写一个方法来获取缓存地址,如下所示:/*** 根据传入的uniqueName(子目录)获取硬盘缓存的路径地址*/public File getDiskCacheDir(Context context, String uniqueName) {String cachePath;//当SD卡【存在】或者SD卡【不可被移除】时if (Environment.MEDIA_MOUNTED.equals(Environment.getExternalStorageState()) || !Environment.isExternalStorageRemovable()) {cachePath = context.getExternalCacheDir().getPath();//【SDCard/Android/data/包名/cache/】目录} else cachePath = context.getCacheDir().getPath();//【/data/data/包名/cache/】目录return new File(cachePath + File.separator + uniqueName);}
获取实例及初始化
DiskLruCache是不能new出实例的,如果我们要创建一个DiskLruCache的实例,则需要调用它的open()方法:public static DiskLruCache open(File directory, int appVersion, int valueCount, long maxSize)参数:数据的缓存地址,当前应用程序的版本号,同一个key可以对应多少个缓存文件(传1即可),最多可以缓存多少字节的数据。需要注意的是,每当版本号改变,缓存路径下存储的所有数据都会被清除掉,因为DiskLruCache认为当应用程序有版本更新的时候,所有的数据都应该从网上重新获取。一个标准的open()方法如下:// 获取图片缓存路径File cacheDir = getDiskCacheDir(context, "thumb");if (!cacheDir.exists()) cacheDir.mkdirs();// 创建DiskLruCache实例,初始化缓存数据try {mDiskLruCache = DiskLruCache.open(cacheDir, getAppVersion(context), 1, 10 * 1024 * 1024);} catch (IOException e) {e.printStackTrace();}/*** 获取当前应用程序的版本号。*/public int getAppVersion(Context context) {try {PackageInfo info = context.getPackageManager().getPackageInfo(context.getPackageName(), 0);return info.versionCode;} catch (NameNotFoundException e) {e.printStackTrace();}return 1;}
MD5编码生成文件名
我们将网络图片保存到本地时,需要指定一个文件名,并且此文件名必须要和图片的URL是一一对应的,那么用什么方式实现呢?直接使用URL来作为key?不合适,因为图片URL中可能包含一些特殊字符,这些字符有可能在命名文件时是不合法的。最简单的做法就是将图片的URL进行MD5编码,编码后的字符串肯定是唯一的,并且只会包含0-F这样的字符,完全符合文件的命名规则。/*** 使用MD5算法对传入的key进行加密并返回。*/public String hashKeyForDisk(String key) {String cacheKey;try {//为应用程序提供信息摘要算法的功能,如 MD5 或 SHA 算法。信息摘要是安全的单向哈希函数,它接收任意大小的数据,并输出固定长度的哈希值。MessageDigest mDigest = MessageDigest.getInstance("MD5");mDigest.update(key.getBytes());//使用指定的 byte 数组更新摘要byte[] bytes = mDigest.digest();//通过执行诸如填充之类的最终操作完成哈希计算,返回存放哈希值结果的 byte 数组StringBuilder sb = new StringBuilder();for (int i = 0; i < bytes.length; i++) {String hex = Integer.toHexString(0xFF & bytes[i]);//以十六进制无符号整数形式返回一个整数参数的字符串表示形式if (hex.length() == 1) sb.append(‘0‘);sb.append(hex);}cacheKey = sb.toString();} catch (NoSuchAlgorithmException e) {cacheKey = String.valueOf(key.hashCode());}return cacheKey;}
缓存的读写操作
写入缓存写入的操作是借助DiskLruCache.Editor这个类完成的。类似地,这个类也是不能new的,需要调用DiskLruCache的edit()方法来获取实例,接口如下:public Editor edit(String key) throws IOException参数key即为缓存文件的文件名有了DiskLruCache.Editor的实例之后,我们可以调用它的newOutputStream()方法来创建一个输出流,然后把它传入到downloadUrlToStream()中就能实现下载并写入缓存的功能了。注意newOutputStream()方法接收一个index参数,由于前面在设置valueCount的时候指定的是1,所以这里index传0就可以了。在写入操作执行完之后,我们还需要调用一下commit()方法进行提交才能使写入生效,调用abort()方法的话则表示放弃此次写入。读取缓存读取主要是借助DiskLruCache的get()方法实现的,接口如下:public synchronized Snapshot get(String key) throws IOException参数就是将图片URL进行MD5编码后的值返回的是一个DiskLruCache.Snapshot对象通过Snapshot的getInputStream()方法可以得到缓存文件的输入流,同样地,getInputStream()方法也需要传一个index参数,这里传入0就好。
其他API
- 1. size()
这个方法会返回当前缓存路径下所有缓存数据的总字节数,以byte为单位,如果应用程序中需要在界面上显示当前缓存数据的总大小,就可以通过调用这个方法计算出来。
- 2.flush()
这个方法用于将内存中的操作记录同步到日志文件(也就是journal文件)当中。这个方法非常重要,因为DiskLruCache能够正常工作的前提就是要依赖于journal文件中的内容。并不是每次写入缓存都要调用一次flush()方法的,频繁地调用并不会带来任何好处,只会额外增加同步journal文件的时间。比较标准的做法就是在Activity的onPause()方法中去调用一次flush()方法就可以了。
- 3.close()
这个方法用于将DiskLruCache关闭掉,是和open()方法对应的一个方法。关闭掉了之后就不能再调用DiskLruCache中任何操作缓存数据的方法,通常只应该在Activity的onDestroy()方法中去调用close()方法。
- 4.delete()
这个方法用于将所有的缓存数据全部删除,比如很多应用中的那个手动清理缓存功能,其实只需要调用一下DiskLruCache的delete()方法就可以实现了。
- 5.remove(String key)
这个方法用于移除指定的缓存,我们并不应该经常去调用它,因为你完全不需要担心缓存的数据过多从而占用SD卡太多空间的问题,DiskLruCache会根据我们在调用open()方法时设定的缓存最大值来自动删除多余的缓存。只有你确定某个key对应的缓存内容已经过期,需要从网络获取最新数据的时候才应该调用remove()方法来移除缓存。
日志文件
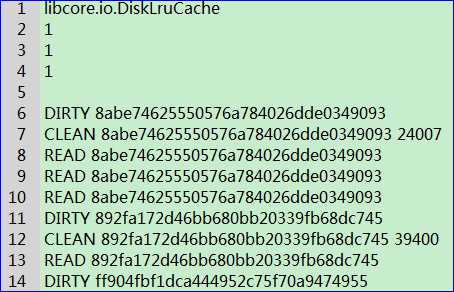
缓存目录下会自动生成一个名为journal的日志文件,程序对每张图片的操作记录都存放在这个文件中,基本上看到journal这个文件就标志着该程序使用了DiskLruCache技术了。其内容片断如下前五行被称为journal文件的头。第一行是个固定的字符串"libcore.io.DiskLruCache",标志着我们使用的是DiskLruCache技术。第二行是DiskLruCache的版本号,这个值是恒为1的。第三行是应用程序的版本号,我们在open()方法里传入的版本号是什么这里就会显示什么。第四行是valueCount,这个值也是在open()方法中传入的,通常情况下都为1。第五行是一个空行。第六行是以一个DIRTY前缀开始的,后面紧跟着缓存图片的key。通常我们看到DIRTY这个字样都不代表着什么好事情,意味着这是一条脏数据。没错,每当我们调用一次DiskLruCache的edit()方法时,都会向journal文件中写入一条DIRTY记录,表示我们正准备写入一条缓存数据,但不知结果如何。然后调用commit()方法表示写入缓存成功,这时会向journal中写入一条CLEAN记录,意味着这条“脏”数据被“洗干净了”,调用abort()方法表示写入缓存失败,这时会向journal中写入一条REMOVE记录。也就是说,每一行DIRTY的key,后面都应该有一行对应的CLEAN或者REMOVE的记录,否则这条数据就是“脏”的,会被自动删除掉。另外,DiskLruCache会在每一行CLEAN记录的最后加上该条缓存数据的大小,以字节为单位。前面我们所学的size()方法可以获取到当前缓存路径下所有缓存数据的总字节数,其实它的工作原理就是把journal文件中所有CLEAN记录的字节数相加,求出的总合再把它返回而已。每当我们调用get()方法去读取一条缓存数据时,就会向journal文件中写入一条READ记录。那么你可能会担心了,如果我不停频繁操作的话,就会不断地向journal文件中写入数据,那这样journal文件岂不是会越来越大?这倒不必担心,DiskLruCache中使用了一个redundantOpCount变量来记录用户操作的次数,每执行一次写入、读取或移除缓存的操作,这个变量值都会加1,当变量值达到2000的时候就会触发重构journal的事件,这时会自动把journal中一些多余的、不必要的记录全部清除掉,保证journal文件的大小始终保持在一个合理的范围内。
标签:
原文地址:http://www.cnblogs.com/baiqiantao/p/5624347.html